模型剪枝学习笔记 --- EagleEye: Fast Sub-net Evaluation for Efficient Neural Network Pruning
论文:https://arxiv.org/abs/2007.02491
代码:https://github.com/anonymous47823493/EagleEye
这篇论文一定要好好研究下,提出该剪枝方法的是暗物智能&中山大学,当初去面试过该公司,聊了将近一小时,大部分是关于剪枝的内容。。。。。。。可惜自己真是菜如狗。。。。。
目录
- 摘要
- 介绍
- 相关工作
- 方法
- Motivation
- Adaptive Batch Normalization
- Correlation Measurement
- EagleEye pruning algorithm
- 实验结果
摘要
找出经过训练的深度神经网络(DNN)的计算冗余部分是剪枝算法所针对的关键问题。许多算法尝试通过引入各种评估方法来预测剪枝后的子网的模型性能。但是对于一般应用而言,它们要么不准确,要么非常复杂。在这项工作中,我们提出了一种称为EagleEye的剪枝方法,其中使用了一个基于自适应批归一化的简单而有效的评估组件,以揭示不同的剪枝DNN结构与其最终确定精度之间的强相关性。这种强大的相关性使我们能够以最高的潜在精度快速发现剪枝后的候选对象,而无需实际对其进行微调。该模块通常用于插入和改进一些现有的剪枝算法。与我们实验中所有研究的剪枝算法相比,EagleEye的剪枝性能更高。具体而言,要剪枝MobileNet V1和ResNet-50,EagleEye的性能要比所有比较方法高出3.8%。即使在剪枝MobileNet V1紧凑型模型的更具挑战性的实验中,EagleEye剪枝的总体操作(FLOP)达到50%时,仍可达到70.9%的最高精度。所有准确性结果均为Top-1 ImageNet分类准确性。
介绍
深度神经网络(DNN)修剪旨在减少具有允许精度范围的完整模型的计算冗余。 修剪后的模型通常会导致能源或硬件资源预算减少,因此,对于部署到高能效的前端系统特别有意义。DNN修剪可以视为搜索问题。 搜索空间由所有合法的修剪网络组成,在本文中,其被称为子网或修剪候选者。 在这样的空间中,如何以合理的搜索工作量获得最高精度的子网是修剪任务的核心。特别是,评估过程通常可以在现有的修剪管道中找到。 此过程旨在揭示子网的潜力,以便可以选择最佳的修剪候选者来提供最终的修剪策略。 图1显示了这种概括的直观图示。
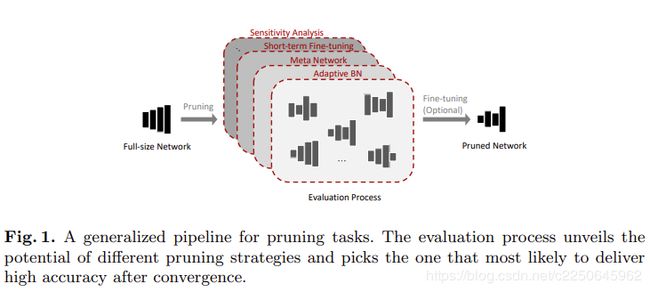
使用评估模块的优点是快速决策,因为在较大的搜索空间中训练所有子网以进行收敛以进行比较可能非常耗时,因此不切实际.
但是,我们发现现有作品中的评估方法并不理想。 具体而言,它们要么不准确,要么复杂。
用不准确的说法表示,评估过程中的获胜者子网在收敛时不一定提供很高的准确性[13,7,19]。 这将在第4.1节中定量证明为通过几个常用的相关系数测得的相关问题。 据我们所知,我们是第一个在修剪任务中引入基于相关性的子网选择分析的方法。 此外,我们证明了这样的评估不准确的原因是对于批次归一化(BN)层使用了次优的统计值[10]。 在这项工作中,我们使用一种所谓的自适应BN技术来解决该问题,并为我们提出的评估流程有效地达到更高的相关性.
复杂地说,它指出了以下事实,即某些作品的评估过程依赖于棘手的或计算量大的组件,例如强化学习代理[7],辅助网络训练[22],知识提炼[8]等。 这些方法需要仔细的超参数调整或对辅助模型的额外训练。 这些要求可能导致难以重复结果,并且由于其高算法复杂度,这些修剪方法可能很耗时。
当前工作中的上述问题促使我们提出一种更好的修剪算法,该算法配备了更快,更准确的评估过程,最终有助于提供最先进的修剪性能。 提出的EagleEye修剪算法的主要新颖性描述如下:
- 我们指出了在许多现有修剪方法中广泛发现的所谓的香草评估步骤(在第3.1节中进行了解释)的原因,导致修剪结果不佳。 为了定量说明问题,我们是第一个将相关性分析引入修剪算法领域的。
- 在这项工作中,我们采用自适应批归一化技术进行修剪,以解决香草评估步骤中的问题。 它是我们提出的称为EagleEye的修剪算法中的模块之一。 我们提出的算法可以在仅几次推理的情况下有效地估计任何修剪模型的收敛精度。 插入和改进现有的一些方法以提高性能也足够通用。
- 我们的实验表明,尽管EagleEye很简单,但与许多更复杂的方法相比,它可以实现最先进的修剪性能。 在ResNet-50实验中,EagleEye的精度比比较算法高1.3%至3.8%。 即使在修剪MobileNet V1紧凑型模型这一艰巨的任务中,EagleEye修剪的总体操作(FLOP)达到50%时,仍可达到70.9%的最高精度。 这里的结果是ImageNet top-1分类准确性。
相关工作
修剪主要是在早期由手工启发式方法处理的[13]。 因此,经过修剪的候选网络是通过人类专业知识获得的,并通过对其进行训练以达到收敛的准确性进行评估,考虑到大量可能的子网,这可能非常耗时。 在后面的章节中,我们将显示修剪候选者的选择存在问题,并且经过选择的修剪网络在微调后不一定能够提供最高的准确性。
其他一些作品在训练阶段出于修剪目的而减轻了重量。 例如,[25]引入了group-LASSO来引入内核的稀疏性,[21]则在批处理归一化层中对参数进行了规范化。 文献[23]根据泰勒展开式对滤波器的重要性进行了排名,并剔除了低级的滤波器。 这些方法中提出的选择标准与我们提出的算法正交。 最近,提出了多种技术来实现自动化和有效的修剪策略,例如强化学习[7],生成对抗性学习机制[17]等。但是引入的超参数增加了重复实验的难度,并且使辅助模型正常工作的反复试验可能很耗时.
调整BN的技术用于现有工程中的非修剪目的。 [14]在领域适应任务中为目标领域适应BN统计。 我们工作的共同点是,我们都注意到批量标准化需要进行调整,以在模型或域发生更改的新设置中适应模型。 但是,这种有用的技术尚未专门用于模型修剪。
方法
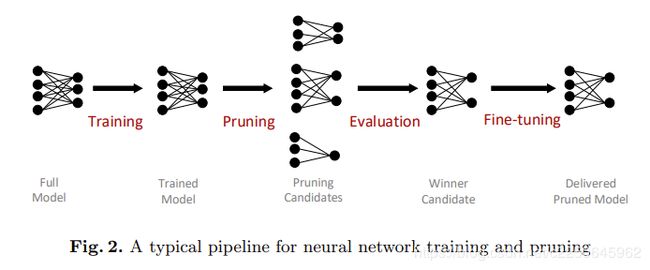
典型的神经网络训练和修剪管道在图2中得到了概括和可视化。出于消除冗余的目的,修剪通常应用于经过训练的完整网络。 然后进行微调过程,以从丢失经过精调的滤波器中的参数后获得精度。 在这项工作中,我们专注于结构化的过滤修剪方法,通常可以表述为:
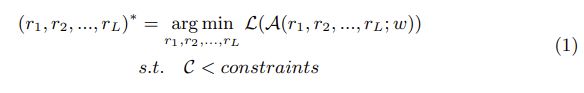
其中L是损失函数,A是神经网络模型。 rl是应用于第l层的修剪率。 给定一些约束C,例如目标参数数量,操作或执行延迟,将修剪比率(r1,r2,…,rL)的组合(称为修剪策略)应用于全尺寸模型。除了手工设计之外,在先前的工作中还应用了不同的搜索方法来找到最佳的修剪策略,例如贪婪算法[26,28],RL [7]和进化算法[20]。 所有这些方法均以修剪策略的评估结果为指导。
Motivation
在该领域的许多公开方法中[7,13,19],修剪候选者在评估准确性方面直接进行了比较。 选择具有较高评估精度的子网,并期望它们在微调后也能提供高精度。 但是,这种意图并不一定能实现,因为我们注意到如果直接用于推理,子网的性能会很差。推断结果通常会落入非常低的范围精度,如左图3所示。 较早的尝试是为MobileNet V1随机生成修剪率,并应用基于L1规范的修剪[13] 50次。
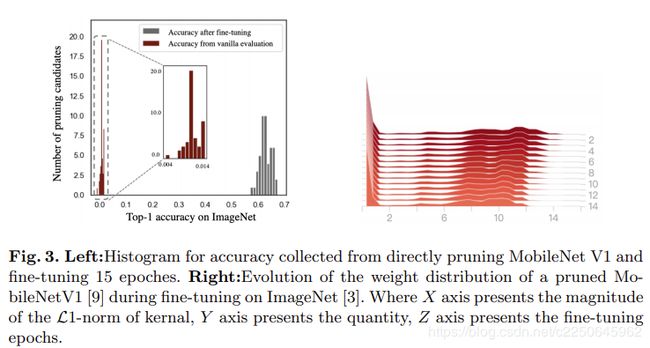
图3中的灰色条显示了对这50个修剪后的网络进行微调后的情况。 我们注意到这两个结果之间的精度分布差异很大。 因此,上面的观察提出了两个问题。 第一个问题是,尽管修剪率是随机的,为什么去除过滤器(尤其是不重要的过滤器)会导致这种明显的精度下降? 接下来要问的自然问题是,低范围精度与最终收敛精度有多强的正相关。 这两个问题触发了我们对这种常用评估过程的调查,该评估过程在本文中称为“香草评估”。
为了初步解决以上两个问题,有一些初步研究已经进行。 图3右显示,权重可能不会在评估阶段影响准确性,因为在微调过程中只能观察到权重分布的平缓变化,但所提供的推断准确性却大不相同。 另一方面,图3左显示低范围精度确实与微调精度之间存在很差的相关性,这意味着使用评估的精度指导修剪候选者的选择可能会产生误导。
有趣的是,我们发现批量标准化层极大地影响了评估。 如果不进行微调,则修剪候选对象的参数是全尺寸模型中参数的子集。 因此,逐层的特征图数据也受到更改的模型尺寸的影响。 但是,原始评估仍然使用从全尺寸模型继承的批归一化(BN)。 BN层的过时的统计值最终将评估精度降低到令人惊讶的低范围,并且更重要的是,打破了评估精度与策略搜索空间中修剪候选者的最终收敛精度之间的相关性。 简短的培训(也称为微调)是对所有修剪的候选对象进行比较,然后进行比较,这是进行评估的更准确方法[20,15]。 但是,由于搜索空间较大,因此即使是单周期微调也要进行基于训练的评估,这非常耗时。
首先,为了定量地展示香草评估的概念以及随之而来的问题,我们将原始BN [10]符号化如下:

其中β和γ是可训练的比例和偏差项。 是一个较小值的术语,以避免零除。 对于大小为N的小批量,μ和σ_2的统计值计算如下:
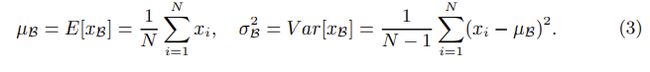
在训练过程中,使用移动平均值和方差来计算μ和σ_2:
![]()
其中m是动量系数,下标t表示训练迭代次数。 在典型的训练流水线中,如果训练迭代的总数为T,则在测试阶段使用µT和σ2T。 这两个项目称为全局BN统计信息,其中“全局”是指完整模型。
Adaptive Batch Normalization
如前所述,在[7,13,19]中使用的香草评估将全局BN统计数据应用于修剪后的网络,以快速评估其准确性潜力,我们认为这会导致低范围准确性结果和不公平的候选人选择。如果全局BN统计信息已过期到子网中,我们应该通过对部分训练集进行几次推理迭代来重新计算带有自适应值的µT和σ2T,这实际上会使BN统计值适应修剪后的网络连接。具体来说,我们在重置移动平均统计信息时冻结所有网络参数。 然后,我们使用等式4通过向前传播的几次迭代来更新移动统计信息,但不进行向后传播。 我们注意到自适应BN统计量为ˆµT和ˆσ2T。
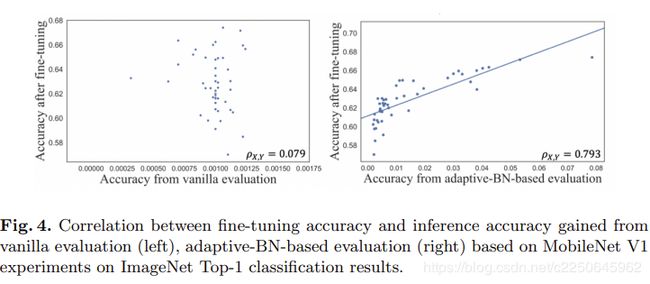
与左图4的原始评估相比右图4说明应用自适应BN可以提供具有更强相关性的评估精度。
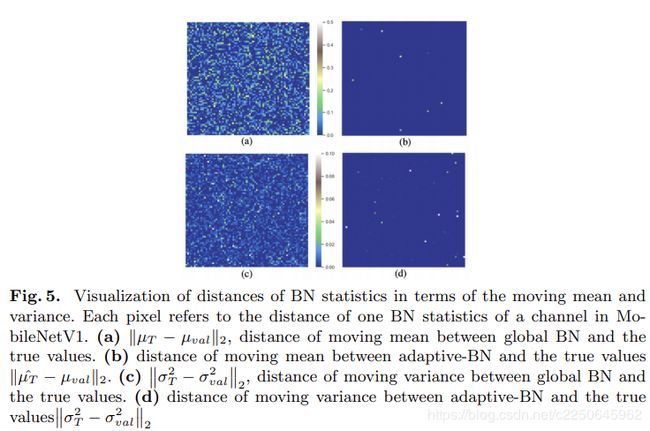
作为另一个证据,我们比较了真实统计之间的BN统计值的距离。 我们将从验证数据中采样的µ和σ2视为真实统计信息,记为µval和σ2val,因为它们是测试阶段的实际统计值。我们并不是从验证数据中获得见解,我们认为这是不公平的,而只是表明我们的评估结果与普通方法相比更接近真实情况。 具体而言,我们期望ˆµT和ˆσ2T尽可能接近真实的BN统计值µval和σ2val,因此它们可以提供接近的计算结果。因此,我们可视化了从不同评估方法获得的BN统计值的距离(请参见图5)。 热图中的每个像素代表评估后结果与通过MobileNet V1中的一个过滤器采样的真实统计之间的BN统计类型(µval或σ2val)之间的距离。 视觉观察表明,自适应BN提供的统计值与真实值更接近,而全局BN则更远。 可能的解释是,全局BN统计信息已过时且不适合修剪的网络连接。 因此,它们会在修剪后的网络评估过程中混淆推理准确性。
值得注意的是,微调还缓解了BN统计数据不匹配的问题,因为训练过程本身会重新计算前向通过中的BN统计值,从而解决了不匹配问题。 但是,BN统计信息不是可训练的值,而是仅在推断时间内计算的采样参数。 我们的自适应BN正是通过在推理步骤中进行重新采样来针对此问题的,这实现了相同的目标,但是与微调相比,计算成本更低。 这是我们声称自适应BN在修剪评估中比基于微调的解决方案更有效的主要原因。
Correlation Measurement
如前所述,==修剪管道中良好的评估过程应在评估的修剪候选者及其对应的收敛精度之间呈现出很强的正相关性。 在这里,我们比较了两种不同的评估方法,即基于自适应BN的评估和香草评估,并研究了它们与微调精度之间的相关性。==因此,我们分别使用上述两种评估方法分别将X1和X2标记为搜索空间中所有修剪候选对象的精度向量(图6),而将经过微调的精度标记为Y。 我们首先使用皮尔逊相关系数[24](PCC)ρX,Y来测量两个变量X和Y之间的线性相关性,然后首先尝试测量ρX1,Y和ρX2,Y之间的相关性:
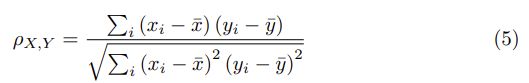
其中¯x和¯y分别是X和Y的平均值。 由于我们特别关注有序精度矢量中的高精度子网,因此采用Spearman相关系数(SCC)[2]φX,Y和Kendall等级相关系数(KRCC)[11]τX,Y来测量单调相关:
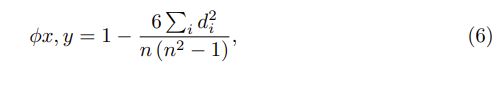

其中n是样本数。 sgn()是符号函数,di是两个有序向量X和Y之间的差。 我们比较了上述三种具有不同修剪率的指标中(X1,Y)和(X2,Y)之间的相关性。 所有情况下,对于基于自适应BN的评估,其相关性都比普通策略强。
EagleEye pruning algorithm
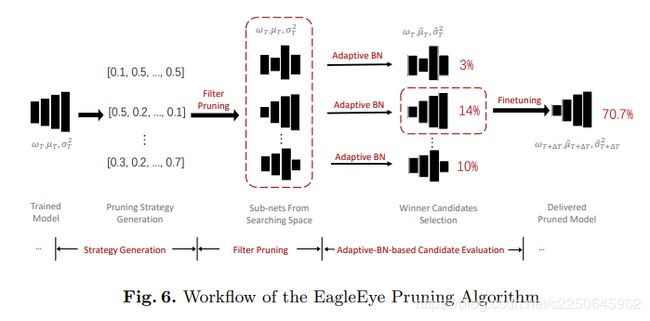
EagleEye的剪枝pipeline如上,包括三个部分,修剪策略生成,过滤器修剪和基于自适应BN的评估。
修剪策略生成以L层模型的分层修剪比例向量(如(r1,r2,…,rL))的形式输出修剪策略。 生成过程遵循预定义的约束,例如推理延迟,操作(FLOP)或参数的全局减少等。具体而言,它从给定范围[0,R]中随机采样L个实数以形成修剪策略,其中rl表示第l层的修剪率。 R是应用于图层的最大修剪比率。 这本质上是蒙特卡洛采样过程,对于所有合法的逐层修剪率。值得注意的是,这里还可以使用其他策略生成方法,例如进化算法,强化学习等,我们发现简单的随机采样足以使整个管道以最新的精度快速生成修剪候选对象。造成这种情况的可能原因是,对BN统计信息的调整导致对子网潜力的预测更加准确,因此可以大大简化生成候选者的工作。该简单组件的低计算成本还为整个算法增加了快速的优势。
过滤器修剪过程会根据前一个模块生成的修剪策略修剪完整尺寸的训练模型。 与普通的过滤器修剪方法类似,首先根据过滤器的L1范数对其进行排名,然后将最不重要的过滤器的rl永久修剪掉。 在此过程之后,可以将来自搜索空间的经过修剪的候选修剪对象准备好传递到下一个评估阶段。
基于自适应BN的候选者评估模块为从先前模块移交的修剪后的候选者提供BN统计信息适应和快速评估。给定一个经过修剪的网络,它将冻结所有可学习的参数,并遍历训练集中的少量数据以计算自适应BN统计量ˆµ和ˆσ2。 实际上,我们在ImageNet实验中对总训练集的1/55进行了50次迭代采样,而在单个Nvidia 2080 Ti GPU中仅花费了10-ish秒。接下来,此模块在训练集数据的一小部分(称为子验证集)上评估候选网络的性能,并从准确性排名中挑选出排名最高的作为候选者。 第4.1节中提供的相关分析保证了此过程的有效性。 经过微调,最终将获胜者作为输出。
实验结果
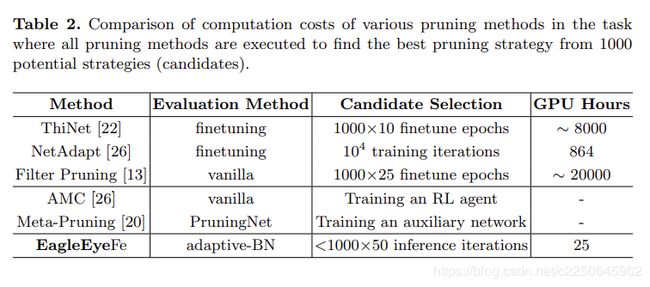
基于自适应BN的修剪评估将子网准确度的预测转换为非常快速且可靠的过程,因此与其他基于重型评估的算法相比,EagleEye花费的时间更少,可以完成整个修剪过程。
表2比较了1000个潜在的修剪候选者中选择最佳修剪策略的计算成本。 由于ThiNet [22]和Filter Pruning [13]需要手动分配逐层修剪比率,因此最终的GPU小时数是完成1000个随机策略的修剪管道的估计。 在实践中,实际的计算成本在很大程度上取决于专家的反复试验的启发式实践。 AMC [7]和元修剪的计算时间可能会很长,因为训练RL网络或辅助网络本身既耗时又棘手。 在所有比较的方法中,EagleEye是最有效的方法,因为每次评估不超过50次迭代,而在单个Nvidia 2080 Ti GPU中需要10到20秒。 因此,总候选人的选择只是一个评估比较过程,也可以立即完成。
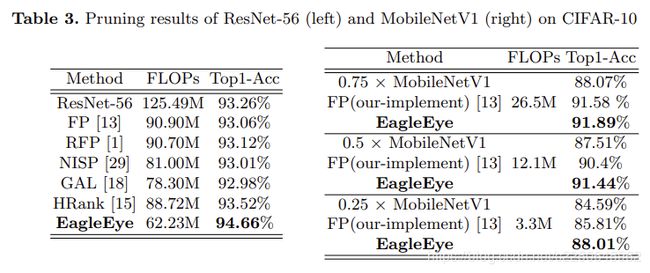
ResNet 表3左侧显示,在CIFAR-10数据集的Top-1准确性方面,EagleEye优于所有比较方法。 为了进一步证明我们方法的鲁棒性,我们比较了在不同FLOP约束下ImageNet上ResNet-50的top-1准确性。 对于每个FLOP约束(3G,2G和1G),将生成1000个修剪策略。 然后,将基于自适应BN的评估方法应用于每个候选项。 我们只对排名前2位的候选人进行微调,并提供最佳的修剪模型。 结果表明,EagleEye在表4中列出的比较方法中取得了最佳结果。
ThiNet [22]除了找到最佳的修剪策略以外,均匀地修剪每一层的通道,这会严重损害性能。 MetaPruning [20]训练了一个称为“ PruningNet”的辅助网络,以预测修剪模型的权重。 但是,采用的原始评估可能会误导对修剪策略的搜索。 如表4所示,在修剪目标不同的情况下,我们提出的算法优于所有比较方法。
MobileNet 我们对MobileNetV1的紧凑模型进行实验,并将修剪结果与“过滤修剪” [13]和直接缩放的模型进行比较。 右表3显示,在所有情况下,EagleEye修剪效果均最佳。
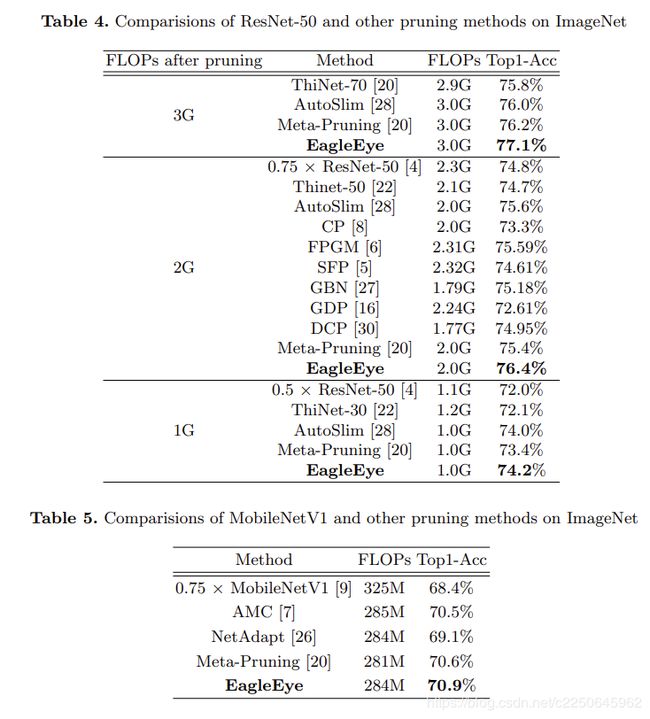
为ImageNet修剪MobileNetV1更具挑战性,因为它已经非常紧凑。 我们比较了相同FLOP约束(约280M FLOP)下的前1个ImageNet分类准确性,结果如表5所示。在此FLOP约束下,生成了1500种修剪策略。 然后,将基于自适应BN的评估应用于每个候选项。 在对前2个候选者进行微调之后,选择返回最高准确度的修剪候选者作为最终输出。
AMC [7]在没有精细调整的情况下根据修剪的模型训练其修剪策略决策代理,这可能会导致候选者的选择出现问题。 NetAdapt [26]在贪婪算法的基础上搜索修剪策略,如第2节中所述,该策略可能会陷入局部最优状态。该任务表明,EagleEye再次在所有研究方法中均获得了最佳性能(参见表5)。
总结:修剪pipeline没有什么区别,感觉唯一的亮点是提出使用基于自适应BN去评估候选子网的潜力,这样相比其他评估方法更有准确性,此外前面的子网选择策略是基于类似蒙特卡罗分析采样取获取的,这样保证了速度快。
总的来说做到了又快又不失精度。