机器学习之决策树与随机森林——基于Scikit-Learn
《Python数据科学手册》笔记
随机森林是一种集成算法,通过集成多个比较简单的评估器形成累积效果。更具体一点就是,随机森林是建立在决策树基础上的集成学习器。
一、决策树
决策树采用非常直观的方式对事物进行分类或打标签,它的每一个节点都根据一个特征的阈值将数据分成两组。在一棵结构合理的决策树中,每个问题基本上都可以将种类可能性减半,而难点也在于如何设计每一步的问题。
二、随机森林
通过组合多棵过拟合的决策树来降低过拟合程度的算法即为随机森林。具体来说就是,使用并行决策树对数据进行有放回抽取集成,每棵决策树都对数据过拟合,通过求均值来获得更好的分类结果。另外,随机森林不只可以用来分类,也可用于回归。
三、随机森林优缺点:
1.优点:
①决策树的原理很简单,所以它的训练和预测速度都非常快,每棵树完全独立,多任务可以直接并行计算。
②多棵树可以进行概率分类,多个评估器之间的多数投票可以给出概率的估计值。
③无参数,模型灵活,在其它评估器都欠拟合的任务中表现突出。
2.缺点:
其结果不太容易解释。
四、示例:
1.决策树
创建一棵含四种标签的数据,如下:
from sklearn.datasets import make_blobs
X,y = make_blobs(n_samples=300,centers=4,random_state=0,cluster_std=1.0)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap='rainbow')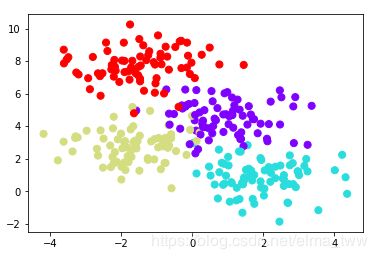
在Scikit-Learn中使用决策树拟合数据并对分类结果进行可视化:
#用决策树进行拟合
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier().fit(X,y)
#对分类器的结果进行可视化
def visualize_classifier(model,X,y,ax=None,cmap='rainbow'):
ax = ax or plt.gca()
#画出训练数据
ax.scatter(X[:,0],X[:,1],c=y,s=30,cmap=cmap,clim=(y.min(),y.max()),zorder=3)
ax.axis('tight')
ax.axis('off')
xlim = ax.get_xlim()
ylim = ax.get_ylim()
#用评估器拟合数据
model.fit(X,y)
xx,yy = np.meshgrid(np.linspace(*xlim,num=200),np.linspace(*ylim,num=200))
Z = model.predict(np.c_[xx.ravel(),yy.ravel()]).reshape(xx.shape)
#为结果生成彩色图
n_classes = len(np.unique(y))
contours = ax.contourf(xx,yy,Z,alpha=0.3,levels=np.arange(n_classes+1) - 0.5,cmap=cmap,clim=(y.min(),y.max()),zorder=1)
ax,set(xlim=xlim,ylim=ylim)
visualize_classifier(DecisionTreeClassifier(),X,y)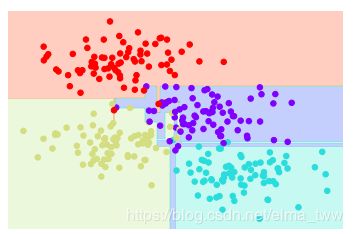
从结果图中可以看到,在米白色和浅蓝色之间有一条狭长的紫色区域,这显然不是根据数据本身情况生成的正确分类结果,更像是一个特殊的数据样本或数据噪音形成的干扰结果,即出现了过拟合。这也是决策树不可避免的一个问题——容易出现过拟合。为了解决过拟合问题,便产生了随机森林。
2.随机森林用于分类
以上面例子的四类标签数据为例,使用Scikit-Learn中的随机森林进行拟合:
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100,random_state=0)
visualize_classifier(model,X,y)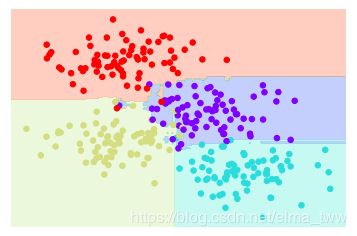
由图可见,通过随机森林,个别特殊样本数据就被忽略了,训练出的模型也更具普适性。
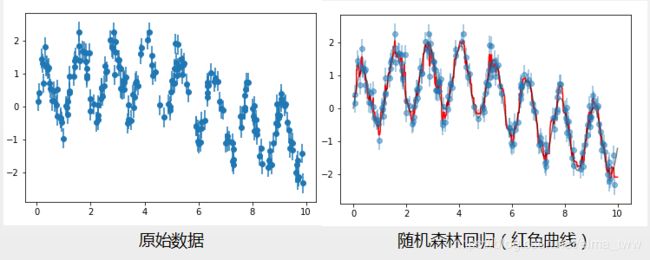
3.随机森林用于回归
#生成训练数据
rng = np.random.RandomState(42)
x = 10*rng.rand(200)
def model(x,sigma=0.3):
fast_oscillation = np.sin(5*x)
slow_oscillation = np.sin(0.5*x)
noise = sigma*rng.randn(len(x))
return slow_oscillation + fast_oscillation + noise
y = model(x)
plt.errorbar(x,y,0.3,fmt='o')
#随机森林回归
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor(200)
forest.fit(x[:,None],y)
xfit = np.linspace(0,10,1000)
yfit = forest.predict(xfit[:,None])
ytrue = model(xfit,sigma=0)
plt.errorbar(x,y,0.3,fmt='o',alpha=0.5)
plt.plot(xfit,yfit,'-r')
plt.plot(xfit,ytrue,'-k',alpha=0.5)