【深度学习】医学图像处理FCN+UNET+VNET整理
这几天看了些有关医学图像处理的网络,大概整理了一些,仅供自己学习积累
医学影像的特点:
1、图像语身的。由于器官本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要(UNet的skip connection和U型结构就派上了用场)。
2、数据量少。因此设计的模型不宜过大,参数不宜过多,否则容易过拟合。
3、多模态。
FCN:
2015年提出全卷积网络(FullyConvolutional Networks, FCN)结构。FCN可以对图像进行像素级的分类,从而解决了语义级别的图像分割问题。与经典的卷积神经网络在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax 输出)不同,全卷积网络可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类,完成最终的图像分割。

全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
Unet:
U-net网络结构与FCN网络结构相似,也是分为下采样阶段和上采样阶段,网络结构中只有卷积层和池化层,没有全连接层,网络中较浅层用来解决像素定位的问题,较深的层用来解决像素分类的问题,从而可以实现图像语义级别的分割。与FCN网络不同的是,U-net的上采样阶段与下采样阶段采用了相同数量层次的卷积操作,且使用skip connection结构将下采样层与上采样层相连,使得下采样层提取到的特征可以直接传递到上采样层,这使得U-net网络的像素定位更加准确,分割精度更高。此外,在训练过程中,U-net只需要一次训练,FCN为达到较精确的FCN-8s结构需要三次训练,故U-net网络的训练效率也高于FCN网络。
U-net网络结构如图2所示, 蓝色箭头代表卷积和激活函数, 灰色箭头代表复制剪切操作, 红色箭头代表下采样, 绿色箭头代表反卷积,conv 1X1代表卷积核为1X1的卷积操作。从图中可以看出,U-net网络没有全连接层,只有卷积和下采样。U-net可以对图像进行端到端的分割,即输入是一幅图像, 输出也是一幅图像

最大的特点:U型结构和skip-connection跳层连接
进行了4次下采样,每层像素信息都是前一层的1/2大小,因此4次采样后图像大小是原来16倍小,再经过4次上采样,并在同个stage使用skip-connection,保证了最后恢复出来的特征图融合了更多的低等级的特征,同时4次上采样也使分割图边缘信息恢复得更加精细。
其中,U型结构实际为一个编码-解码的过程:
在编码过程中,底层特征(如layer1、2、3的输出)更偏向于组成图像的基本单元,如点,线,边缘轮廓;而在高层抽象的特征(如Layer4,5)就更抽象,更近似于表示的是图像的语义信息,更像是一个区域了。
相关论文:神经网络可视化论文《Visualizing and Understanding Convolutional Networks》
https://link.springer.com/content/pdf/10.1007/978-3-319-10590-1_53.pdf
在解码过程中,对数据恢复时,特征scale减小造成信息丢失,因此利用skip connection。
skip connection起到了补充信息的作用(跳级连接能够保证特征更加精细),在高层补充了语义的信息,在底层细化了分割的轮廓等,(从特征中已经大致恢复了区域的分割信息,再加上原始特征的修正,提高最终的分割效果)
UNet结构,结合了低分辨率信息(提供物体类别识别依据)和高分辨率信息(提供精准分割定位依据)(低分辨率找位置,高分辨率进行精细分割)。
Unet适用于医学图像分割、自然图像生成。适用于医学图像原因:
(1)因为医学图像边界模糊、梯度复杂,需要较多的高分辨率信息,高分辨率用于精准分割。
(2)人体内部结构相对固定,分割目标在人体图像中的分布很具有规律,语义简单明确,低分辨率信息能够提供这一信息,用于目标物体的识别。
Milletari等人[66]提出了U-net网络结构的一种3D变形结构V-net,V-net结构使用Dice系数损失函数代替传统的交叉熵损失函数,且使用3D卷积核对图像进行卷积,通过1x1x1的卷积核减少通道维数。
Vnet:
为处理前景和背景像素体严重失衡的情况,引入了新的目标函数,骰子系数。
早期的方法是通过对图像进行分段分类来获得图像或卷中的解剖轮廓。这种分割是通过仅考虑局部环境而获得的,因此很容易失败,特别是在有大量错误分类的像素体中。与Unet不同,在Vnet中使用三维卷积核,并提出基于Dice系数最大化的目标函数来优化模型。
在医疗量中,感兴趣的解剖结构仅占据扫描的非常小的区域,导致学习过程陷入损失函数的局部最小值,从而产生其预测强烈偏向背景的网络。结果,前景区域经常丢失或仅部分检测到。
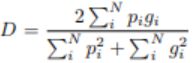
其中总和在N个体素上运行,预测的分割体积pi∈P和真实体积gi∈G。可以区分这种Dice的形式,产生相对于预测的第j个体素计算的梯度。 使用这个公式我们不需要为不同类别的样本分配权重以在前景体素和背景体素之间建立正确的平衡。
信息量、熵、交叉熵等原理解释:
https://blog.csdn.net/xg123321123/article/details/52864830
交叉熵损失函数:
信息量是用来衡量一个事件的不确定性的;一个事件发生的概率越大,不确定性越小,则它所携带的信息量就越小。
熵是用来衡量一个系统的混乱程度的,代表一个系统中信息量的总和;信息量总和越大,表明这个系统不确定性就越大。
在logistic regression中,
p:真实样本分布,服从参数为p的0-1分布,即X∼B(1,p)
q:待估计的模型,服从参数为q的0-1分布,即X∼B(1,q)
两者的交叉熵为:

对所有训练样本取均值得:
![]()
由此可见,交叉熵的损失函数单独评估每个像素矢量的类预测,然后对所有像素求平均值,所以我们可以认为图像中的像素被平等的学习了。但是,医学图像中常出现类别不均衡(class imbalance)的问题,由此导致训练会被像素较多的类主导,对于较小的物体很难学习到其特征,从而降低网络的有效性。
有较多的文章对其进行了研究,其中FCN 在每个通道加权该损失,从而抵消数据集中存在的类别不均的问题。同时,Ronneberger et al.提出的 U-Net 提出了新的逐像素损失的加权方案,使其在分割对象的边界处具有更高的权重。该损失加权方案以不连续的方式帮助他们的 U-Net 模型细分生物医学图像中的细胞,使得可以在二元分割图中容易地识别单个细胞。
dice coefficient :
dice loss比较适用于样本极度不均的情况(为什么没探究)

其中 ![]() 表示集合A、B 之间的共同元素,
表示集合A、B 之间的共同元素,![]() 表示 A 中的元素的个数,B也用相似的表示方法。
表示 A 中的元素的个数,B也用相似的表示方法。
refference:
https://blog.csdn.net/weixin_41783077/article/details/80894466