PostgreSQL源码修改 ——查询优化(二)
第二章 问题分析——查询优化执行流程
2.1 问题总体分析
如前所述,我们的问题重点是在Executor部分,并且,我们将专注这个总要重要函数的详细流程及其重要的数据结构,因此,本章的行为思路是先分析整体流程,再分述几个修改将涉及的重要模块和函数流程,最后对执行过程中的重要数据结构做一个分析。
在分析的过程中,我们采取的分析方法是结合SourceInsigh + windows和KDevelope+虚拟机VMware Workstation。即在SourceInsigh阅读和定位源码,并在KDevelope中调试单步执行并观察其结果。在调试中,我们的示例执行语句是:select * from teacher order by name limits 2 offset 1。
从第一章的问题描述小节,我们已经得知我们要做的事情。就是修改某个排序模块的某些执行步骤,使其达到优化的效果。这里所谓的某个排序模块的某些执行步骤就是我们这章分析和解决的问题,也是分析的目标。
2.2 查询优化整体流程
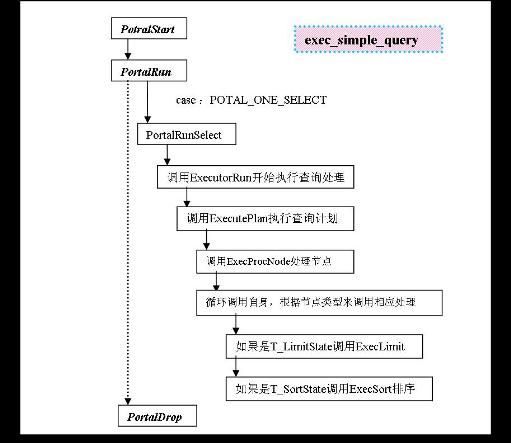
从前面的分析中,我已经知道用户输入的一个简单查询语句,经过前台的处理,系统从exec_simple_query 函数开始执行查询处理。所以我们着手从这里开始深入分析,下图为exec_simple_query函数的执行流程。此图来源于师姐的经验分析报告。因为觉得表达的确实很清晰,便不做改动,直接引用至此。
|
PotralStart |
|
PortalRun |
|
PortalRunSelect |
|
调用ExecutorRun开始执行查询处理 |
|
调用ExecutePlan执行查询计划 |
|
调用ExecProcNode处理节点 |
|
循环调用自身,根据节点类型来调用相应处理 |
|
如果是T_LimitState调用ExecLimit |
|
如果是T_SortState调用ExecSort排序 di |
|
PortalDrop |
|
case :POTAL_ONE_SELECT |
|
exec_simple_query |
图表 1:exec_simple_query总体流程
如图所示, exec_simple_query函数主要调用了PortalStart, PortalRun, PortalDrop 三个函数。PortalStart 主要做一些初始化准备工作, PortalDrop是在进行查询完毕之后的释放相关资源相关的等结尾工作。和我们项目相关的重点在PortalRun。
在PortalRun中,函数根据portal->strategy选择不同的语句执行策略,属于哪种情况,对于所给示例代码,属于PORTAL_ONE_SELECT分支,这样就调用PortalRunSelect函数开始处理,最后返回处理过的元组。
在PortalRunSelect函数中,进一步调用了ExecutorRun,它是查询处理的关键函数,查询执行器的核心功能都是在这个函数中处理完成。
ExecutorRun它主要是通过调用ExecutePlan,将按照查询规划处理之后的返回值赋给结果变量result。而ExecutePlan函数则是按照生成的查询规划树开始执行相应处理。
在ExecutePlan内部,递归遍历执行计划树,即调用ExecProcNode函数处理规划树上的每个节点,每次返回一个元组放入slot中去,如果返回元组为空则退出循环。每得到一个元组,根据其查询操作的类型对该元组进行相应处理,在我们的语句,属于CMD_SELECT情况,会继续调用到ExecSelect函数将以个slot赋给result。
其中ExecProcNode函数是我们要重点分析和修改的部分。它处理一个规划树上的节点,并返回一个tuple。至此开始,它要开始循环调用自身,不断根据不同节点类型进行不同的处理。条件判断在一进入该函数时进行,在所给的示例语句中,计划树的结构如下图所示:
图表 2:示例语句的计划树结构
从上图可以看出,首先节点类型为T_LimitState,这样就会调用ExecLimit函数来处理。该函数我们将继续作为重点在下一张流程图中作分析。
在ExecLimit中,将再次调用ExecProcNode函数,这时,它的左子节点是一个T_SortState类型,所以将会调用ExecSort函数进行排序,这个函数也是我们重点修改的,我们后面会单拿出来进行详细分析。
而ExecSort也会调用其子结点T_SeqScan的ExecSeqScan来执行,这个函数不是我们关注的重点,故可以略过。
2.3 ExecLimit详细分析
2.3.1 ExecLimit关键代码及注释
| TupleTableSlot * ExecLimit(LimitState *node) /* return: a tuple or NULL */ { TupleTableSlot *slot; PlanState *outerPlan; //获取子计划结点 outerPlan = outerPlanState(node);
/* * ExecLimit状态变化及运动的逻辑主体 */ switch (node->lstate) { case LIMIT_INITIAL: //处理offset限制 //计算limit_count和offset等数据 recompute_limits(node); //判断参数是否合法 if (node->count <= 0 && !node->noCount) { node->lstate = LIMIT_EMPTY; return NULL; } //处理至offset for (;;) { /*这里开始了第一次递归调用,在此递归调用中,会引有子计划结点的执行 根据我们的示例select * from teacher order by name limits 2 offset 1 和图1,其子计划结点为T_SortState在即将运行的ExecProcNode中,将会运行 result = ExecSort((SortState *) node); */ slot = ExecProcNode(outerPlan); if (TupIsNull(slot)) { //如果子计划返回的元组为空,即元组不够 node->lstate = LIMIT_EMPTY; return NULL; } …… } /* * 我们已经通过执行子结点,获取了正确的元组,将状态修改为LIMIT_INWINDOW */ node->lstate = LIMIT_INWINDOW; //接下来返回的原组是满足要求的。 break; }
case LIMIT_INWINDOW: /* * Get next tuple from subplan, if any. */ slot = ExecProcNode(outerPlan); //取出一下排序好的结点 //注意:outerPlan中有sort_Done标明已经排序完毕 //只是需要返回相应位置的值即可 if (TupIsNull(slot)) { //没有成功取完就退出了。 node->lstate = LIMIT_SUBPLANEOF; return NULL; } node->subSlot = slot; node->position++; //指到下一个该取的位置 } else //逆向扫描的情况 { } break; case LIMIT_EMPTY: //状态机结束 /* * The subplan is known to return no tuples (or not more than * OFFSET tuples, in general). So we return no tuples. */ return NULL;
case LIMIT_SUBPLANEOF: …… break;
case LIMIT_WINDOWEND: ……
case LIMIT_WINDOWSTART: …… default: …… break; } return slot; } |
图表 3:ExecLimit关键代码及注释
2.3.2 ExecLimit流程分析与描述
ExecLimit函数首先判断节点状态,根据不同的执行状态进入不同的分支。
当第一次进入该函数时,为LIMIT_INITIAL,调用recompute_limits函数来计算limit/offset的值,并将position参数置0。然后开始循环调用ExecProcNode函数,处理子规划的结点,知道节点的position超过了offset值,这样得到了从offset设定的开始位置的一个元组,并将node->lstate修改为LIMIT_INWINDOW。
当node->lstate是LIMIT_EMPTY情况时,则返回。
当node->lstate为LIMIT_INWINDOW情况。表示元组在我们的处理窗口中,从LIMIT_INWINDOW状态的元组开始,我们调用ExecProcNode陆续从子规划中得到tuple。如果节点状态变为了LIMIT_WINDOWEND,则退出,返回空值。ExecLimit函数每次返回一个slot给它的上层调用者。
后面的状态与我们的流程关系不大,故省略。
2.3.3 ExecLimit流程图解
由上面的分析,我们可以大致得到以下的流程图:
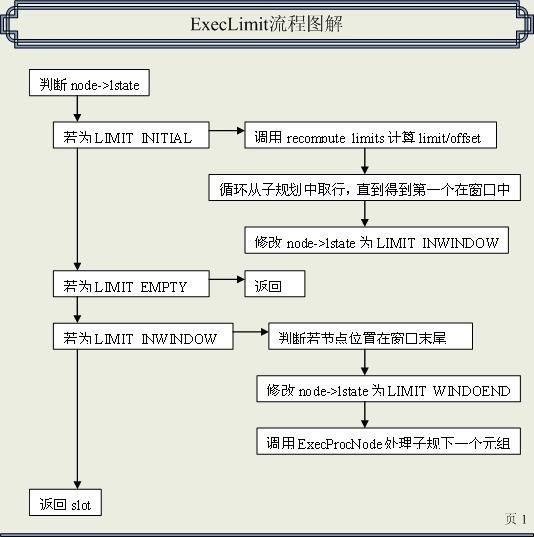
图表 4:ExecLimit流程图解
在ExecLimit中递归调用子结点的ExecProcNode,在此时的ExecProcNode中,会调用ExecSort。下面我们就继续分析分析这个重要的函数。
2.4 ExecSort详细分析
2.4.1 ExecSort关键代码及注释
| TupleTableSlot *ExecSort(SortState *node) { EState *estate; Tuplesortstate *tuplesortstate; TupleTableSlot *slot; //获取执行状态 estate = node->ss.ps.state; tuplesortstate = (Tuplesortstate *) node->tuplesortstate; //如果还没有排序,则排序 if (!node->sort_Done) { tuplesortstate = tuplesort_begin_heap(tupDesc, plannode->numCols, plannode->sortOperators, plannode->sortColIdx, work_mem, node->randomAccess); //分配空间 //下面的循环是调用其子计划结点来获取待排序的元组,在示例语句中,此子计划为T_SeqScan类型,由ExecSeqScan来执行 for (;;) { slot = ExecProcNode(outerNode); //在这里outerNode是一种方法取出数据库中数据,比方说ExecSeqScan() 方式 //运行:每一次从outerNode返回一个元组 if (TupIsNull(slot)) break;
tuplesort_puttupleslot(tuplesortstate, slot); //放入刚取出的元组 //如果放入元素量巨大,有可能演变成外排序中的顺串 } //完成排序 tuplesort_performsort(tuplesortstate); //分为内排序(快速排序)和外排序两种情况 …… } slot = node->ss.ps.ps_ResultTupleSlot; //返回一个排序后的元组,关键的是puttuple_common()函数的实现 (void) tuplesort_gettupleslot(tuplesortstate, ScanDirectionIsForward(dir), slot); return slot; } |
图表 5:ExecSort关键代码及注释
2.4.2 ExecSort流程分析与描述
这个函数执行流程比较简单,当执行状态为“node->sort_Done”时执行排序,排序前先调用子计划结点以获取元组,在示例语句中,此子计划为T_SeqScan类型,由ExecSeqScan来执行。当准备好待排序数据之后,调用tuplesort_performsort来完成排序。
2.4.3 ExecSort流程图解
ExecSort流程图解如下图:
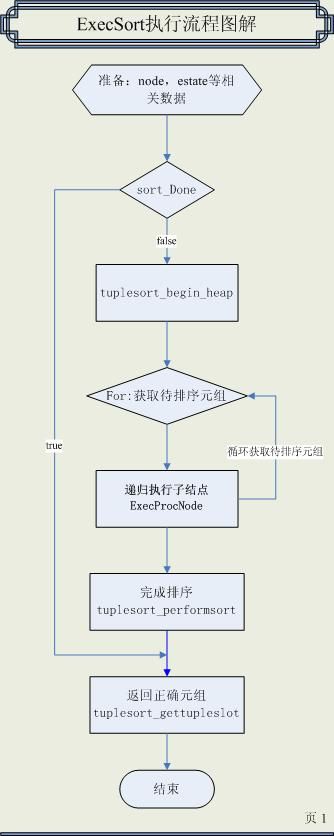
图表 6:ExecSort流程图解
在流程图中可以发现,tuplesort_performsort是完成排序模块,下面对其进行分析。
2.5 tuplesort_performsort详细分析
2.5.1 tuplesort_performsort关键代码及注释
| void tuplesort_performsort(Tuplesortstate *state) { MemoryContext oldcontext = MemoryContextSwitchTo(state->sortcontext); switch (state->status) { case TSS_INITIAL: //如果有足够的内存来完成排序,则直接在内存中调用快速排序来完成 if (state->memtupcount > 1) qsort_arg((void *) state->memtuples, state->memtupcount, sizeof(SortTuple), (qsort_arg_comparator) state->comparetup, (void *) state); state->current = 0; //output run number,初始值为 //以下两个信息是对游标信息的设置 state->eof_reached = false; state->markpos_offset = 0; state->markpos_eof = false; //是否提前结束 state->status = TSS_SORTEDINMEM; break; case TSS_BUILDRUNS: //否则进入外排序分支 dumptuples(state, true); //把内存所有的元组归位 mergeruns(state); //完成后状态机设置为TSS_FINALMERGE //如果在内存中只有一个tape,设置状态为state->status = TSS_SORTEDONTAPE; // TSS_FINALMERGE; state->eof_reached = false; state->markpos_block = 0L ; state->markpos_offset = 0; state->markpos_eof = false; break; default: elog(ERROR, "invalid tuplesort state"); break; } MemoryContextSwitchTo(oldcontext); } |
图表 7:tuplesort_performsort关键代码及注释
2.5.2 tuplesort_performsort流程分析与描述
此函数的流程也很简单,在进行上下文切换之后,判断执行状态,如果是TSS_INITIAL则表示已经有足够的内存可以放置待排序元组,且已经把数据准备好,直接调用快速排序即可完成。如果TSS_BUILDRUNS,则进入外排序分支。
2.5.3 tuplesort_performsort 流程图解

图表 8:tuplesort_performsort 流程图解
2.6 重要的数据结构分析
在我们比较详细的分析的函数ExecProcNode(PlanState *node) 、ExecLimit(LimitState *node) 、ExecSort(SortState *node) 、tuplesort_performsort(Tuplesortstate *state)中,其入口参数分别对应着PlanState、LimitState、SortState、Tuplesortstate。下面就其一些相对重要的成员做更深一步的分析。
2.6.1 P lanState
| //执行计划的状态结点 typedef struct PlanState { NodeTag type; Plan *plan; /* 查询计划结点*/ EState *state; /* 执行状态*/ …… struct PlanState *lefttree; /* 左子计划结点:输入 */ struct PlanState *righttree; List *subPlan; /* SubPlanState nodes in my expressions */ …… } PlanState; |
图表 9:PlanState关键代码及注释
PlanState关键的变量即为以上几个。其中第一个域是NodeTag,说明他继承自己Node,后面用组合的方式来获得Plan和Estate的功能,因为PlanState正是两者的结合。
2.6.2 LimitState
| typedef enum { LIMIT_INITIAL, /* initial state for LIMIT node */ LIMIT_EMPTY, /* there are no returnable rows */ LIMIT_INWINDOW, /* have returned a row in the window */ LIMIT_SUBPLANEOF, /* at EOF of subplan (within window) */ LIMIT_WINDOWEND, /* stepped off end of window */ LIMIT_WINDOWSTART /* stepped off beginning of window */ } LimitStateCond;
typedef struct LimitState { PlanState ps; /* its first field is NodeTag */ ExprState *limitOffset; /* OFFSET parameter, or NULL if none */ ExprState *limitCount; /* COUNT parameter, or NULL if none */ int64 offset; /* current OFFSET value */ int64 count; /* current COUNT, if any */ bool noCount; /* if true, ignore count */ LimitStateCond lstate; /* state machine status, as above */ int64 position; /* 1-based index of last tuple returned */ TupleTableSlot *subSlot; /* tuple last obtained from subplan */ } LimitState; |
图表 10:LimitState关键代码及注释
第一个枚举为Limit结点的一些执行状态。从LimitState的成员中可以看出,LimitState的第一个域是PlanState,说明其继承自PlanState,这也是为什么ExecProcNode能递归运行的原因,是PostgreSQL用C语文实现了结构体的伪继承,从而实现了基类与派生类的指针转换,PostgreSQL中的伪继承机制在ExecProcNode中体现的淋漓尽致。在最后一章我们将再会探讨此技术。
2.6.3 SortState
| /* ---------------- * SortState information * ---------------- */ typedef struct SortState { ScanState ss; /* its first field is NodeTag */ bool randomAccess; /* need random access to sort output? */ bool sort_Done; /* sort completed yet? */ void *tuplesortstate; /* private state of tuplesort.c */ } SortState; |
图表 11:SortState 关键代码及注释
从第一个域中可以看出,SortState继承自ScanState,其他三个成员也容易理解。第二个指示是否已经完成排序,tuplesortstate为其排序要用到的一些参数。
2.6.4 Tuplesortstate
这个数据结构比较复杂,我们摘其要点列表如下:
| //nodeSort.c struct Tuplesortstate { TupSortStatus status; /* enumerated value as shown above */ int nKeys; /* number of columns in sort key */ bool randomAccess; /* did caller request random access? */ long availMem; /* remaining memory available, in bytes */ long allowedMem; /* total memory allowed, in bytes */ int maxTapes; /* number of tapes (Knuth's T) */ int tapeRange; /* maxTapes-1 (Knuth's P) */ MemoryContext sortcontext; /* memory context holding all sort data */ /* 排序用到的各种函数 */ int (*comparetup) (const SortTuple *a, const SortTuple *b, Tuplesortstate *state); void (*copytup) (Tuplesortstate *state, SortTuple *stup, void *tup); void (*writetup) (Tuplesortstate *state, int tapenum, SortTuple *stup); void (*readtup) (Tuplesortstate *state, SortTuple *stup, int tapenum, unsigned int len); …… //下面还有一些内排序和外排序需要用到的一些数据。 }; |
图表 12:Tuplesortstate关键代码及注释
2.7 外存处理流程分析
在tuplesort_performsort(Tuplesortstate *state)中,switch (state->status)时,当case TSS_BUILDRUNS:时,会进入外存处理分支。在此分支中,调用mergeruns来完成外排序。这个函数实现了Knuth的〈计算机程序设计艺术〉中的多阶段合并算法,下面讨论一下多阶段合并算法及其在PostgreSQL中的实现流程。
2.7.1 多阶段合并算法
此算法的具体思想在书中中文版本第二版第三卷的220页,读者可以参阅。
其大致流程如下图所示:
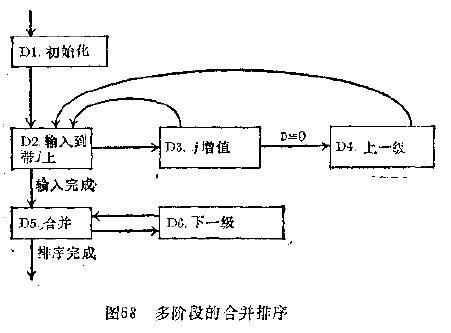
图表 13:多阶段合并算法流程示意图
算法步骤的描述简要如下:

图表 14:多阶段合并算法算法步骤
2.7.2 P ostgreSQL中多阶段合并算法实现流程
mergeruns实现了多阶段算法中的D5与D6步,因为此前的ExecSort在tuplesort_performsort之前,就已经调用tuplesort_puttupleslot准备好了初始顺串。其完成的流程是:tuplesort_puttupleslot调用puttuple_common,而puttuple_common在case TSS_BUILDRUNS:分支中调用tuplesort_heap_insert来完成的。
回到,mergeruns,在mergeruns中,会调用beginmerge(Tuplesortstate *state)来从外存中获取元组数据放入到内存中进行归并排序。
在beginmerge(Tuplesortstate *state)中,每次只取一个元组进行归并。如果我们能知道需要排序的项数,则可以在这个函数中去控制拿的项数,以减少访外的次数。