python 数据分析(四)Pandas 统计分析基础 (文本文件的读写 + DataFrame的常用属性 + loc方法)
文章目录
- 一、读写不同数据源的数据
- 1. 文本文件的读写
- (1)文本文件读取
- ① 使用 read_table 来读取文本文件
- ② 使用 read_csv 函数来读取 csv 文件
- ③ read_table 和 read_csv 常用参数及其说明
- (2)文本文件存储
- ① to_csv写入csv 文件
- ② 参数说明
- (3)读取 Excel 文件
- ① Excel 文件读取
- ② 参数说明
- (4)Excel 文件储存
- 二、查看 DataFrame 的常用属性
- 1. 基础属性
- 2. 基础属性的练习
- 三、DataFrame的操作
- 2. head 和 tail 获取数据
- 3. loc方法---location
- (1)获取所有表的数据
- (2)获取指定列的数据
- (3)获取指定行的数据
- 4. 相对不怎么常用的获取数据的方式
前言:统计分析是数据分析重要的组成部分,它几乎贯穿了整个数据分析的流程。 应用统计方法,将定量与定性结合,进行的研究活动叫统计分析。统计分析除了 包含单一数值型特征的数据集中趋势、离散趋势和峰度与偏度等统计知识外,还包含了多个特征比较计算等知识。
一、读写不同数据源的数据
1. 文本文件的读写
(1)文本文件读取
文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。
这里要介绍的是txt和csv两种类型文件的读取。
txt文件我们都很熟悉,常用的文本文档。
csv 是一种逗号分隔的文件格式,因为其分隔符不一定是逗号,又被称为字 符分隔文件,文件以纯文本形式存储表格数据(数字和文本)。
注:(1)CSV 文件根据其定义也是一种文本文件;(2)文本文件是字符分隔文件
① 使用 read_table 来读取文本文件
pandas.read_table(filepath_or_buffer,sep=’\t’,header=’infer’, names=None,index_col=None,dtype=None,engine=None,nrows=None)
案例:
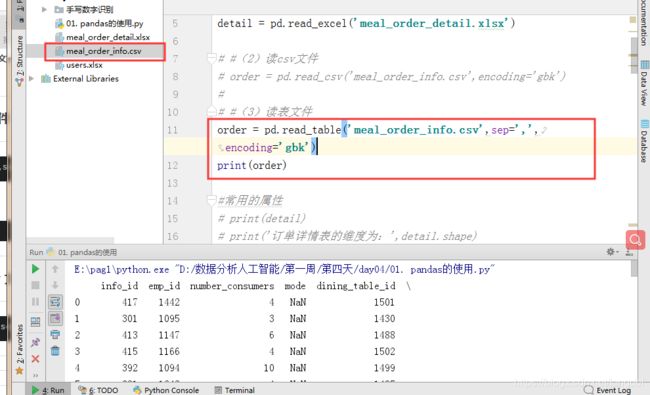
order = pd.read_table('meal_order_info.csv',sep=',',encoding='gbk')
print(order)
② 使用 read_csv 函数来读取 csv 文件
pandas.read_csv(filepath_or_buffer,sep=’\t’,header=’infer’, names=None,index_col=None,dtype=None,engine=None,nrows=None)
案例:
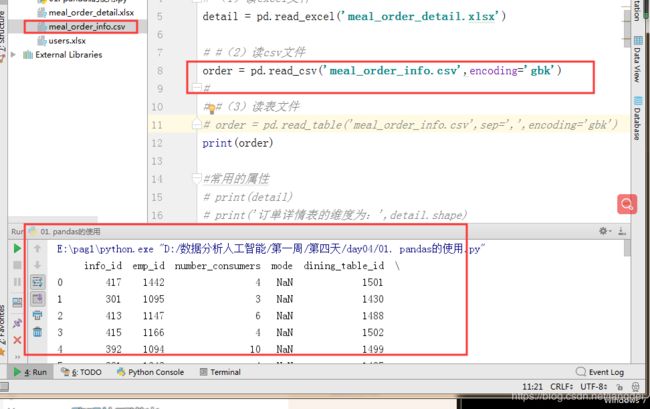
order = pd.read_csv('meal_order_info.csv',encoding='gbk')
print(order)
③ read_table 和 read_csv 常用参数及其说明

以菜品订单为例,读取订单数据,并统计订单数据条数
- read_table 和 read_csv 函数中的 sep 参数是指定文本的分隔符的,如果分隔符指定错误,在读取数据的时候,每一行数据将连成一片。
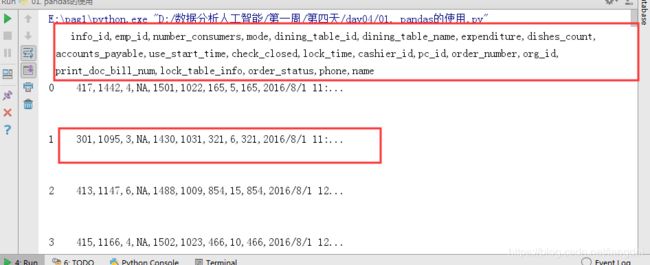
- header 参数是用来指定列名的,如果是 None 则会添加一个默认的列名。
- encoding 代表文件的编码格式,常用的编码有 utf-8、utf-16、gbk、gb2312、 gb18030 等。如果编码指定错误数据将无法读取,IPython 解释器会报解析错误。

正确案例:

(2)文本文件存储
文本文件的存储和读取类似,结构化数据可以通过 pandas 中的 to_csv 函数 实现以 csv 文件格式存储文件
① to_csv写入csv 文件
DataFrame.to_csv(path_or_buf=None, sep=’,’, na_rep=”, columns=None, header=True, index=True,index_label=None,mode=’w’,encoding=None)
案例:
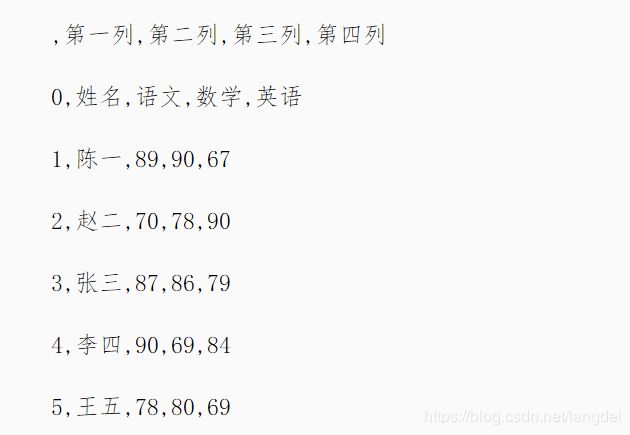
>>> df = pd.read_csv('data.csv', encoding='gbk', names=['第一列', '第二列', '第三列', '第四列'])
>>> df
第一列 第二列 第三列 第四列
姓名 语文 数学 英语
陈一 89 90 67
赵二 70 78 90
张三 87 86 79
李四 90 69 84
王五 78 80 69
df.to_csv('data_1.txt')
如果data_1.txt文件不存在,则会新建data_1.txt文件后再写入,如果本来已存在该文件,则会清空后再写入,写入后data_1.txt文件内容如下:
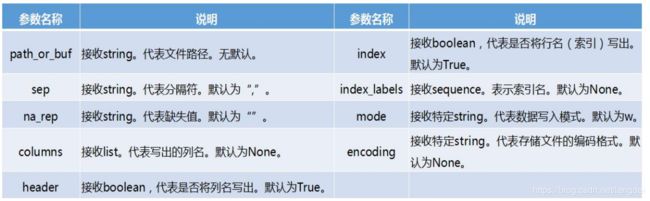
② 参数说明
(3)读取 Excel 文件
① Excel 文件读取
pandas 提供了 read_excel 函数来读取“xls”“xlsx”两种 Excel 文件。
pandas.read_excel(io, sheetname=0, header=0, index_col=None, names=None, dtype=None)
案例:
detail = pd.read_excel('meal_order_detail.xlsx')
print(detail)

② 参数说明

(4)Excel 文件储存
将文件存储为 Excel 文件,可以使用 to_excel 方法。其语法格式如下:
DataFrame.to_excel(excel_writer=None, sheet_name='None', na_rep=”, header=True, index=True, index_label=None, mode=’w’, encoding=None)
案例:
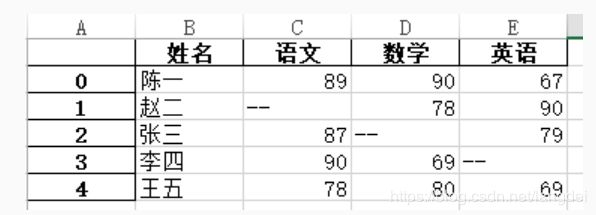
>>> import pandas as pd
>>> pd.read_excel('data.xlsx')
姓名 语文 数学 英语
陈一 89.0 90.0 67.0
赵二 NaN 78.0 90.0
张三 87.0 NaN 79.0
李四 90.0 69.0 NaN
王五 78.0 80.0 69.0
>>> df = pd.read_excel('data.xlsx')
>>> df.to_excel('data_1.xlsx', na_rep='--')
to_csv 方法的常用参数基本一致,区别之处在于指定存储文件的文件路径参 数名称为 excel_writer,并且没有 sep 参数,增加了一个 sheetnames 参数用来 指定存储的 Excel sheet 的名称,默认为 sheet1。
excel_writer:必传参数,指定需要写入的excel文件,可以使表示路径的字符串或者ExcelWriter类对象。
二、查看 DataFrame 的常用属性
1. 基础属性
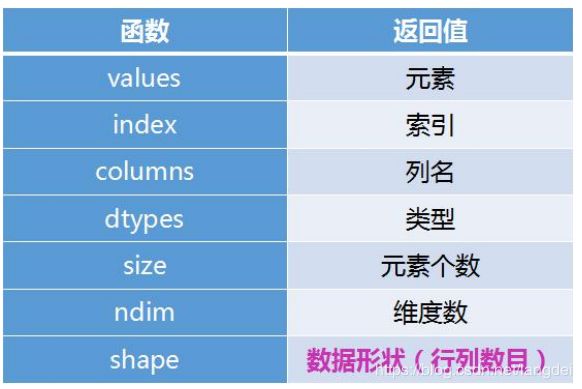
2. 基础属性的练习
import pandas as pd
detail = pd.read_excel('meal_order_detail.xlsx')
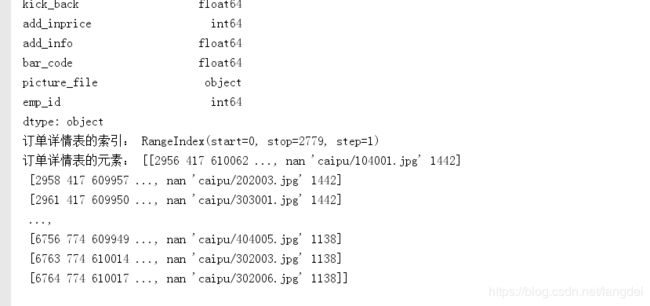
print('订单详情表的维度为:',detail.shape)
print('订单详情表的轴:',detail.ndim)
print('订单详情表的元素个数:',detail.size)
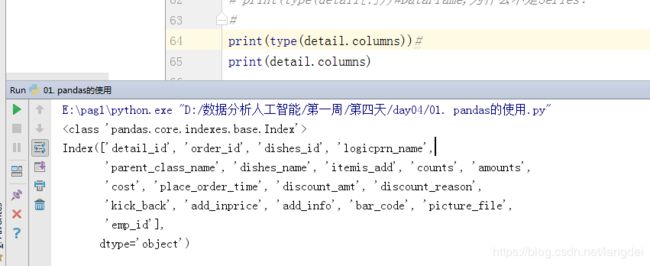
print('订单详情表的列名:',detail.columns)
print('订单详情表的类型:',detail.dtypes)
print('订单详情表的索引:',detail.index)
print('订单详情表的元素:',detail.values)


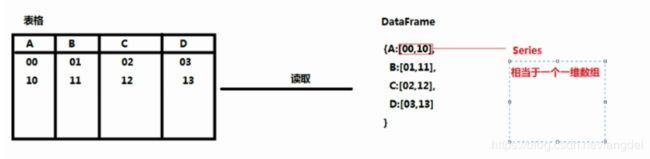
三、DataFrame的操作
我们读取文件都是
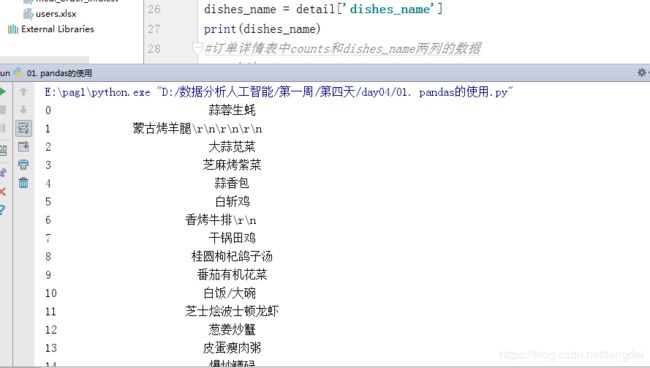
初学:把表对象当成一个字典,结合numpy二维数组进行操作
detail = pd.read_excel('meal_order_detail.xlsx')
dishes_name = detail['dishes_name']
print(dishes_name)
查看访问 DataFrame 中的数据——数据基本查看方式
对单列数据的访问:DataFrame 的单列数据为一个 Series。根据 DataFrame 的定义可以 知晓 DataFrame 是一个带有标签的二维数组,每个标签相当每一列的列名。有以下两种 方式来实现对单列数据的访问
- 以字典访问某一个 key 的值的方式使用对应的列名,实现单列数据的访问。
- 以属性的方式访问,实现单列数据的访问。(不建议使用,易引起混淆)
对某一列的某几行访问:访问 DataFrame 中某一列的某几行时,单独一列的 DataFrame 可以视为一个 Series(另一种 pandas 提供的类,可以看作是只有一列的 DataFrame), 而访问一个 Series 基本和访问一个一维的 ndarray 相同。
对多列数据访问:访问 DataFrame 多列数据可以将多个列索引名称视为一个列表,同时 访问 DataFrame 多列数据中的多行数据和访问单列数据的多行数据方法基本相同。
对某一列的某几行访问:
以菜品订单为例,获取 dishes_name 列下的前 5 个数据:
dishes_name5 = detail['dishes_name'][:5]
对某几行访问: 如果只是需要访问 DataFrame 某几行数据的实现方式则和上述的访问多列多行相似,选 择所有列,使用“:”代替即可
2. head 和 tail 获取数据
head 和 tail 也可以得到多行数据,
但是用这两种方法得到的数据都是从开始或者末尾获 取的连续数据。默认参数为访问 5 行,
只要在方法后方的“()”中填入访问行数即可实现目标 行数的查看。
print('订单详情表中前五行数据为','\n',detail.head())
print('订单详情表中后五个元素为:','\n',detail.tail())
也可以指定获取几行
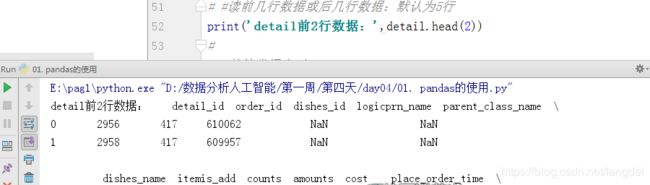
print('detail前2行数据:',detail.head(2))
3. loc方法—location
说明:可以获取到指定行或列的数据
格式:表对象.loc[行,列]
(1)获取所有表的数据
result = detail.loc[:,:]
# result等同于detail
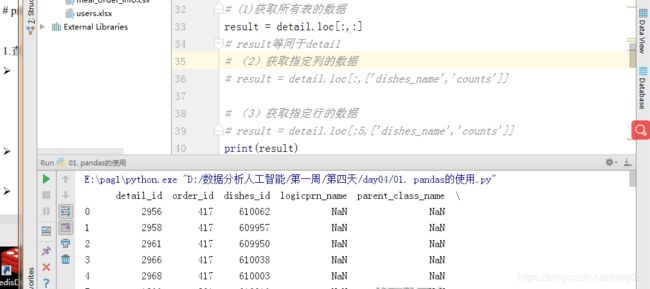
注意:获取的是所有行和所有列的数据
(2)获取指定列的数据
result = detail.loc[:,['dishes_name','counts']]
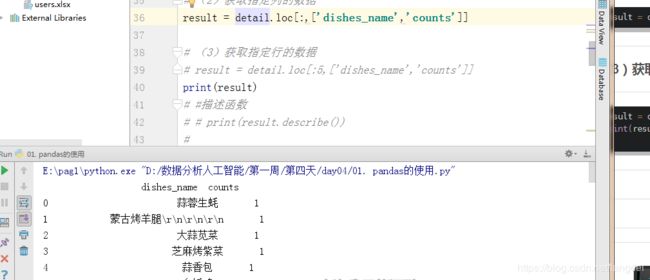
注意:获取所有行和指定列的数据
(3)获取指定行的数据
result = detail.loc[:5,['dishes_name','counts']]
print(result)
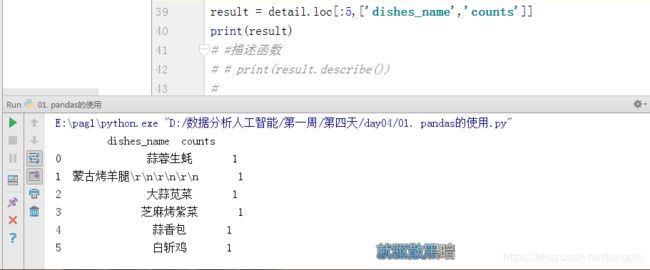
注意:获取指定列和前五行的数据
4. 相对不怎么常用的获取数据的方式
(1)eg:
print('表格中dishes_name前5行的内容:\n',detail['dishes_name'][:5])
(2)eg:
print('表格中所有列的1~6行的数据:\n',detail[:][1:6])
print(type(detail))#DataFrame—数据结构—倾向于字典
凡是DataFrame类型对象,都可以使用列名获取数据,eg:detail[‘dishes_name’]
print(type(detail['dishes_name']))#Series–序列—表示一组序列数据–倾向于列表
print(type(detail['dishes_name']))#Series
print(type(detail[:]))#DataFrame,为什么不是Series?
# :取出的是所有的列所有数据
如:
print(type(detail.columns))
print(detail.columns)