腾讯云数据库CDB技术演进之路
【IT168 专稿】本文根据【2016 第八届系统架构师大会】(微信搜索SACC2013,关注系统架构师大会公众号)现场演讲嘉宾程彬老师分享内容整理而成。录音整理及文字编辑IT168@田晓旭@老鱼。
嘉宾简介:

程彬,腾讯基础架构部数据库研发负责人。2008年毕业加入腾讯,一直从事数据存储相关研发工作;在云计算浪潮涌来之时参与到腾讯云存储产品的打造。目前在腾讯TEG基础架构部,负责数据库(CDB)和云硬盘(CBS)研发相关工作。
正文:
大家好,我是程序员程彬,08年毕业后加入腾讯,一直在腾讯技术工程事业群从事存储系统研发和运营相关工作。今天我和大家分享的主题是腾讯云云数据库CDB技术演进。

这次我会从存储、复制和数据库引擎三个维度来介绍云数据库CDB技术演进。首先是CDB的存储演进, 数据库本质上就是存储的一种表现形式,所以这里会讲一些存储技术的演进;第二部分是CDB的复制演进,基于复制技术,数据库可以衍生出各种灵活的冗余架构,来实现数据库的数据高可靠和服务高可用等特性,所以这里会讲一些复制技术的实践;最后,讲数据库肯定离不开数据库引擎,所以会来讲腾讯MySQL数据库引擎技术发展史。
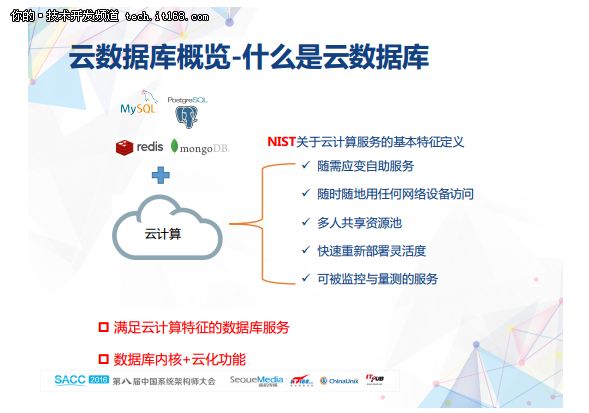
我们先简单介绍一下云数据库,顾名思义它就是数据库和云计算的结合,从产品角度看就是满足云计算特性的数据库。如何构建云数据库产品呢?个人认为要解决三类人的需求。首先就是架构师,数据库作为系统架构中不可缺少的部分,架构师的很多架构设计强依赖于数据库的可靠存储、高HA和高事务处理性能;其次就是DBA,DBA是数据库守护神,数据库管理、备份回档、弹性扩展、线上调优、安全审计和成本都是DBA关注的点;最后就是产品经理,数据库看起来和产品经理相距甚远,其实不然。产品的核心用户数据不能丢失或者泄露,这需要高可靠和高安全的数据库;用户体验的8秒法则强依赖于数据库的性能,产品活动营销的秒杀也强依赖于数据库的性能。要解决这三类人的问题,技术上就要搞定数据库内核和云化功能两件事情。数据库内核是可靠存储、高HA和高事务处理性能的基石,云化功能是解救DBA伤痛的灵方妙药。今天我们重点聊聊数据库内核技术。这里的内核不仅仅指MySQL内核。
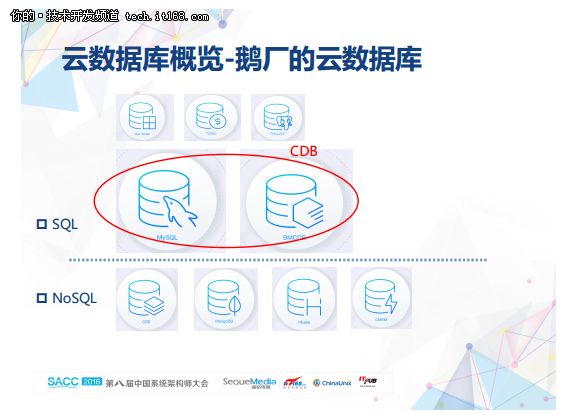
很多人都好奇鹅厂的云数据库。谈起腾讯,都知道微信、QQ、游戏。其实腾讯不仅仅是一家社交娱乐互联网公司,也是一家云计算技术公司。作为云计算关键服务的DBaaS-腾讯云数据库也是公司内比较亮眼的一个技术产品。腾讯云数据库总体是按照SQL和NOSQL派系来划分的,产品上涵盖了DBEgine上TOP开源数据库,商用oracle也有深度合作,目前也有oracle的产品对外。我们今天聊的CDB,就是SQL派系,基于MySQL打造的云数据库服务。

从技术栈的角度看,CDB内核核心技术包含三部分:接入,实例和存储。
接入集群要做的工作是什么呢?首先会对外提供数据库访问入口,访问就涉及到路由;第二,既然它是对外的,那么就会有网络安全问题;第三,对内它会屏蔽数据库的物理故障,所以它需要解决HA问题。
实例集群,简单的讲就是一堆MySQL的进程。关于MySQL进程,我们认为有两个问题需要去思考:第一个问题怎么保证MySQL性能、稳定性以及功能是否满足用户需求;第二个是复制的问题,云数据库中的数据安全是非常重要的,怎么才能多副本强一致复制,减少用户丢数据的概率,同时对性能不能损耗太多。
很多数据库只要完成接入和实例部分就可以了,无需再进行第三部分,但是我们在实践过程中也对数据存储做了一些技术创新,从根本上来讲,数据库就是一种存储形态。

CDB研发之初,团队包括我自己对MySQL内核缺少深入的了解。如何满足用户需求,构建云数据库产品的技术亮点,我们另辟蹊径。从当时的用户疼点和业务场景出发,通过优化存储来解决性能和成本的问题。在数据库存储上,我们这些年走过路,有两条经验大家可以思考下。首先,数据库存储需要根据存储介质的发展而不断重新设计的,从机械磁盘到SSD盘,未来可能还有nvram,不同存储介质下,数据库存储实现是完全不同的。第二,数据库存储的本质就是面向块的存储 ,繁杂的数据模型,复杂的数据组织,最终落地还是按照一个个数据块来进行的。
存储技术演进,总体来说,我们总共经历了4个阶段3次革命。第一个阶段,我们和大家一样用本地的SAS盘和Raid的方式来做数据库存储,第二个阶段我们把本地存储变成网络存储,我们称之为SSD-Cluster,即基于SSD分布式的存储; 第三个阶段我们还是做SSD,不过SSD的协议发生了变化;第四个阶段我们又回到Cluster阶段。

第一次革命是从本地SAS转变成网络Cluster,为什么我们当时要做这件事?背后的故事是这样的,当时SAS存储我们遇到了3个问题,第一个就是性能问题,云服务肯定是多租户的,MySQL本身就是随机IO,多租户上去之后IO就更加随机了,但SAS盘本身的随机IO性是非常糟糕的。第二个问题就是扩展性的问题,当时CDB对外提供最大实例规格的硬盘不到2T,如果一个用户需要3T的空间怎么办?可能大家会采用基于中间件的数据分片方法,但是这样又会面临一个兼容性的问题。基于中间件的数据分片方法,在SQL兼容和MySQL的ACID特性支持上,和单机MySQL相比,还是有很多不同的地方,另外分布式查询上也会有很多问题,单机上跑的很好的SQL在分片下可能会很卡。第三个就是成本的问题,云服务价格贝佐斯定律告诉我们每一计算能力单元的价格每3年大约会下降一半,其实在中国,下降的幅度会更大。我们怎么做才能持续下降成本,让大家享受到云数据库的成本优势呢? 这三个问题都和存储紧密相关,存储性能、存储容量和单位存储性价比。那么看看我们怎么解决这个存储三个难题的呢?
首先看看当时存储介质情况。2011年PCI-E SSD刚刚兴起,IO性能相比机械磁盘有划时代的进步,但同时价格也非常昂贵。如果用它,上面三个问题的情况会变成什么样子呢?首先性能问题迎刃而解,随机IO性能会有较大提升;扩展性问题依旧存在;成本问题,单位存储成本更高。另外,早期SSD本身做的也不太好,写放大、写性能下降问题在线上业务运营中比较突出。
用单机版PCI-E SSD比较难解决的问题就是存储空间扩展性问题,其次是单位存储成本问题,最后是如何更好更科学的使用SSD层介质问题。
当时在腾讯内部,基于SSD的分布式存储已经存在,所以我们就考虑使用这种方法是否能够解决上述问题。首先,分布式所以扩展性肯定没有问题;其次,成本问题, 分布式存储有一个很好的地方就是它的资源分配更加灵活,可以按需分配,整体来看利用率会变更高,当时分析了一个线上数据,利用率有3到5倍的提升空间,所以之前花100块钱。现在只需要20~30块钱了。成本问题也就解决了。第三个问题是怎么去用好SSD,当时MySQL的存储引擎和SSD两者配合的还不是很好,但在SSD上开发一个专有的存储引擎,适配SSD的数据组织和读写机制,那么SSD性能很容易就可以被充分使用,也可以规避SSD写放大、写性能下降等问题。
所以我们认为这种方法是可行的,接下来我们面临的唯一问题就是怎么把数据库的存储和分布式的SSD做关联?在MySQL中,ROW和磁盘关联的桥梁是块,磁盘的block。数据库存储的本质就是块存储。我们要解决的就是块存储怎么和KV存储关联起来。块的数据模型可以用diskid、lba、len和data来描述。把diskid+lba作为key,data作为value,这样就很容易转换为(key,value,len)的数据模型。数据模型转换的事情搞定了,接下来只需要通过虚拟块设备进行IO网络化处理,本地的块读写就彻底转变为网络KV操作了。

第二件事情就是怎么适配SSD特性的KV存储系统,这个问题比较容易解决,而比较麻烦的就是MySQL层的适配。怎么让MySQL更好的跑在网络存储上呢?当时MySQL跑在网络存储上主要存在两个问题。第一个问题就是网络带宽的问题,2011年万兆网络还没有普及,很多互联网公司服务器网络环境都是千兆,这里就存在一个很明显的问题:InnoDB默认数据库页的大小是16KB,在千兆网络下,IOPS理论上是没有办法超过7000次, 我们当时的解决方法是把16KB转成4KB,IOPS能力提升了4倍左右。但page size调整为4KB后,又引发一些新的问题,比如并发事务数会受到限制,这里需要需改MySQL内核来解决这个限制。另外一个问题就是性能,相同的存储介质下,走网络的开销肯定比本地延时开销大,毕竟走本地的总线肯定非常快,那么怎么去提升整体的性能呢?我们在做测试的时候发现了double write问题,double write 就是为了解决页的partial write问题,但当我们把InnoDB改成4KB以后这个问题也就基本没有了, 因为4KB本来就是最小的原子操作。所以说我们当时既解决了千兆网络瓶颈也把double write干掉了,这样性能相比原生会提升不少。另外,在IO调度上,也有一些优化,比如InnoDB原生顺序化flush机制对于网络存储其实起反作用,网络存储要尽快加大并发度。
除了MySQL之外,我们还做了一些文件系统和块层的调优,这里就不展开一一赘述了。
当时云上数据库收费方式包括现在,并没有真正实现非常严谨的按需付费。假如我去买一台虚拟机或者买一个数据库实例,选择了硬盘100G,但其实一开始业很难使用到这么多空间,有的甚至业务下线后还没用完,但我必须为100G买单。当时我们对内部的服务器使用情况做了一个盘点,把闲置的空间利用起来,通过下调价格的方式反馈给客户,间接的帮助用户实现了按需付费。由于有了分布式存储的动态伸缩的能力,即使出现爆仓的情况,我们也可以快速进行扩容。这个版本做出来以后,价格直接下调了50%,让广大开发商受益。
在运营方面我们经历了一段小插曲,那就是存储集群的蝴蝶效应。它讲的是可用性问题,以前单机版存储的数据库有一个好处,当你单台服务器、单个硬盘坏了以后,对整体的影响非常小,但如果你做了网络存储,那么单点或者单个部件异常对整体的影响就会非常大,一块硬盘或者一台机器出现异常没有快速的处理,那么可能会波及到很多开发商,最终上升为一次大事件。
关于这个问题,我们主要优化SSD KV的高HA能力。除了加固网络故障、机器故障发现机制之外,针对服务亚健康状态也做了优化。举个简单例子,一块盘或者一台服务器直接是用0和1两个状态来标记好与坏,但很多时候,比如坏盘或者网络故障,好到坏是有一个过程的,也就是所谓的亚健康状态。所以,我们除了0和1两个状态之外,我们还设置了中间状态的,如0.5、0.7等。 这个数字设置的依据是什么呢?我们不仅是根据心跳机制,还依据更多IO服务的质量,比如我们会统计它的延时,如果当前的延时比较大,尽管还是可用,那么我们就会认为这是一个非常危险的状态,我们会把它剔除掉。这样做完之后,效果很明显,大大减少了故障对用户的影响时间,缩短了RTO时间。
第二个问题可能比较普遍,在分布式存储系统中,当一个副本出现异常的时候,特别是网络波动情况下,系统就认为这个节点异常而被剔除掉,需要重构一个新的副本,由于涉及到数据搬迁,所以开销是非常大。我们的做法是把临时故障和长久故障分开来处理,对于网络波动等临时故障,让节点临时离线,恢复正常后,会让它重新加入到线上,这个时候只需要把离线这段时间的流水补过来就可以了,这样就会大大的减少数据重构的时间。

2013年CDB的用户又有了新变化。首先第一个是腾讯云上开发商的变化,早期很多开发商把一些非核心应用放到云上,所以整个计算和IO要求不是特别高。到了2013年,很多IO密集应用开始上云了,这里对数据库性能有更高的要求,包括吞吐和RT。第二个变化就是存储介质的变化,2013年的时候,PCI-E SSD 已经非常便宜了,稳定性也不错了,这时就出现了两个问题,一个本地PCI-E SSD性能更好,第二个就是本地PCI-E SSD性价比也比较高。我们刚开始考虑PCI-E SSD Cluster存储可行性。首先是性能,本地延迟本身就要比网络低,所以性能上面没有太大优势;第二个扩展性,很多的单机的PCI-E SSD可以支持6T,基本上能满足核心业务存储量的需求,集群存储带来的大容量也失去了原有的价值;第三个就是SSD的使用,SSD厂商自己也在不停地发展,特别是一些FTL技术发展的特别好,可以非常好地去适配一些通用的用法。接下来就是成本问题, 成本问题我们是基于PCI-ESSD Cluster和PCI-ESSD本地来比,PCI-ESSD Cluster在成本上可以会继续保持优势,因为它可以按需分配,但如果我们去量化的话,就会发现这个问题其实不是主要矛盾。最后一个问题就是运维成本,以前本地的时候只需要 3或5个DBA,但我们用了网络之后发现运维的成本可能会增加到6到10个DBA, 因为整个系统的IO路径变长了很多。
基于以上几个原因的综合考虑,我们把Cluster的方案砍掉了,选择采用本地PCI-E SSD,但是采用这种做法之后,是不是我们数据库的研发工程师就已经失业了?当然不是,我们在2013年又做了一次技术调整,对数据库引擎本身的性能和稳定性做了一些优化。

2015年底,我们发现金融和政企的一些数据库开始上云,这些用户和以前互联网用户有很大的区别,他们上云的一个必要条件就是不要改变现有应用软件,所以这就产生了第一个问题,就是兼容性问题,其余的问题包括RTO、RPO和扩展性。
这里看下典型的扩展性问题,像金融、政企这些传统企业,他们都有专有的存储设备,它的单机支持个几十T都没有问题的,所以他的业务上云之后发现业务环境支持变成6TB,肯定是无法满意的。如果我们采用中间件sharding技术,他可以解决扩展性问题,但是无法解决兼容性问题。
所以,我们当时给自己定的目标是做一个100TB以下的、完全兼容SQL的传统行业的DB服务。我们分析一些行业案例和学术论文,发现MySQL+SDP技术能比较好的满足我们的需求。简单的讲,我们用的是一个共享存储,它是一个并行共享存储,MySQL的master对这个共享存储有读写权限,而slave只有读权限。这时我们要考虑怎么去保证一致性的问题,如master写的时候,slave上的一些脏数据怎么处理。另外一个问题,就是master节点异常后,怎么进行故障转移,怎么快速把slave提升为master,怎么让它能从共享存储中恢复完整数据。这个版本目前还在内测中,内部成熟后会对外。
上面就是CDB在存储技术上一些实践。
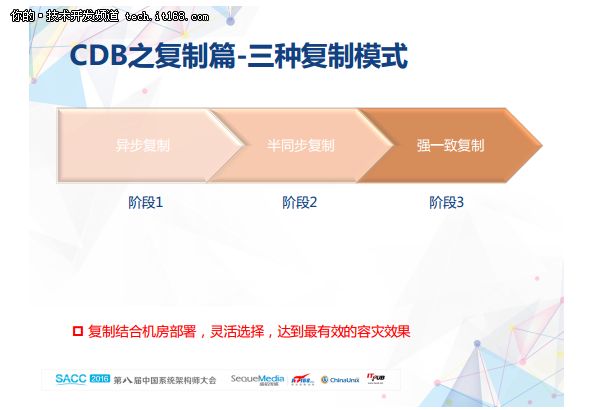
CDB复制技术演进经历了三个阶段。第一个阶段是异步复制,主要面向的是游戏等互联网场景,因为互联网里很多主从一致性已经通过了业务架构解决,如双写或者MQ的手段;第二个就是我们发现很多传统企业并没有像互联网企业很好的解决了数据一致性的问题,他们对数据库自身的同步复制还是比较依赖的,所以第二个阶段就是半同步复制;对于金融行业,半同步也不能满足了,它就是要求数据不能丢失,所以这就进入到了第三个阶段,强一致复制。
复制技术需要在可靠存储、高HA和性能之间进行取舍。所以从产品角度来看,CDB需要能结合机房部署,能灵活选择,让用户用的爽。
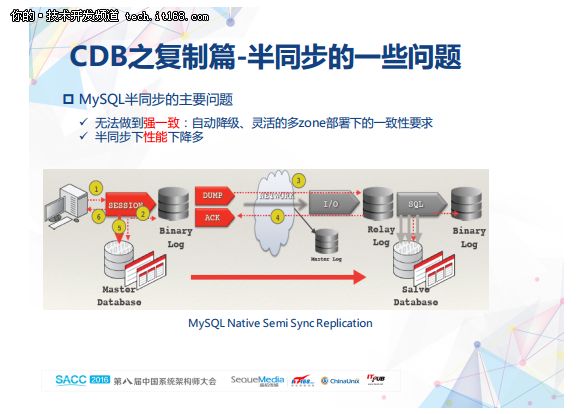
针对当时MySQL原生异步复制的一些问题,我们在强一致复制中对数据可靠和同步性能做了一些改进工作。
第一个主要是原生MySQL半同步没办法做到强一致,上图是原生半同步的过程。第一个问题就是它会自动降级,比如早期5.5的时候,你把它配置为半同步,它在半同步失效的时候又转换为异步;第二个就是多园区的部署一些问题。比如同城两个园区,部署三个节点,肯定有一个slave和master部署在同一个园区。在原生半同步下,只要有一个slave返回ack它就成功了,考虑到网络RTT,一般情况下,同园区slave肯定是优先返回,另外一个园区的slave数据就落后于master了,此时,master所在园区异常,跨园区数据容灾其实就没达到应有效果。
第二个是半同步性能下降多。

当时我们主要是从两个方面来考虑性能优化,第一个是单个事务耗时,第二个是系统整体吞吐。
MySQL在同步复制下耗时主要包含三个部分。第一个是SQL部分,第二是存储引擎,第三部分是复制。和异步相比,我们重点优化第三部分的延时。复制延时主要有两部分:第一部分是binlog网络传输过去的耗时,第二部分是slave落地binlog的延时。binlog传输耗时取决于网络RTT值,这里从MySQL层面没有太好的优化方法。我们重点就看看slave落地binlog的延时。
我们做了一个测试进行定量分析。在全Cache下MySQL异步的情况下,单事务耗时是3.37毫秒,就是说它的SQL加引擎一共耗时3.37毫秒,但是我们发现在半同步的情况下延时就变成了8.33毫秒,我们发现RTT是2.6毫秒,那么slave落地binlog就花费了1.9毫秒,那1.9毫秒是否合理呢?我们接着做了一个测试,模拟slave落地binlog的操作,发现只需要0.13毫秒,这里面其实有接近1.8毫秒的优化空间。
第二个就是如何提升系统吞吐。当单个事务的延时降下来后,是不是就意味着整个系统的吞吐就上来了?这也未必,整个吞吐来说取决于两个因素,一个是支持的并发数,另外一个就是单个事务的延时。假如你有一些公共资源存在很大的竞争,那就可能存在并发数上不来了的问题,我们发现master的binlog发送/响应线程是有很大的优化空间的。所以我们就基于这两个方面去做了系统吞吐的优化。

如何解决slave落地binlog的耗时呢?我们当时分析MySQL slave的IO线程接收binlog耗时的主要瓶颈有三个:第一个就是锁冲突,IO/SQL线程间的锁冲突,如元数据文件锁;第二部分就是小IO消耗,IO线程离散小磁盘IO消耗过多的IOPS;第三个问题是串行化,IO线程接收和落盘操作串行。
基于上述分析,我们发现slave复制这部分需要进行重度优化,为了减少对MySQL关键部分的侵入性,同时把性能做到极致,我们就把slave这部分复制功能单独抽出来,做了一个logbus。logbus兼容MySQL复制的协议,MySQL复制协议本身是没有多大变化的。所以当MySQL版本变化时,logbus是可以复用的。基于logbus,我们就构造出了一个快速强一致的复制通道。logbus基于semisync协议,模拟slave向master建立主从关系,同步binlog;避免原生相关耗时瓶颈;外置logbus,减少对MySQL的侵入,方便各种分支兼容 。

MySQL 5.6里有一个binlog同步阻塞传输模型,我们解决了如何把同步变成异步的问题,同时也在复制方面做了性能优化。这里社区也有类似工作,就不展开讲了。

最后我们聊聊数据库引擎。CDB数据库引擎是基于oracle MySQL CE版来进行定制的,版本覆盖5.1、5.5和5.6,5.7目前还在内测中。我们内部称之为Tencent MySQL,简称TXSQL。坦白地讲,相比其他技术,国内各厂在MySQL内核研发能力上整体还是偏弱的。我们也是从零开始,所幸的是依赖腾讯这个大平台以及腾讯云这个战略业务,我们内核研发能力也初显成效。
我们在2010到2011年主要做的就是面向运维的优化。当时遇到一个问题就是,DBA没办法从MySQL实例中得到SQL操作延时以及相关库表的操作频度,DBA不能很好的预测SQL质量以及“死”库表。我们当时做的第一件事情就是在MySQL里面把这些东西统计出来,我们把所有的select、delete等这样的一些操作全部统计了出来,然后通过agent收集到一个专有的统计系统来进行分析和处理。接着我们就对DBA常遇到的slave写权限、连接数满等问题,进行优化。这个阶段,很好的解决了DBA的问题,同时也锻炼了内核研发能力。
当我们面向运维做了一些优化之后,我们在数据库引擎方面就有些自信和实力了,所以接下来就会做一些面向BUG的优化。当时,游戏比较风靡,90后流行使用火星文,但是MySQL 5.1原生版本里面是对火星文支持不够好,所以我们针对这个做了优化。另外就是MySQL高版本或者其他社区版本已经解决的一些bug,我们怎么安全的移植过来。这个阶段让我们开始融入社区,体会到开源的好处。
经过上面两个阶段后,我们开始进入深水区-性能优化。针对高并发读场景,我们专门进行了read view优化。针对高并发写场景,我们专门进行了redo log buffer锁拆分。这个阶段,对内核掌控能力要求非常之强,另外更重要的是性能优化的方法论建立,包括怎么发现问题、分析问题和找到解决方案。另外内核源码测试和版本灰度上,也有很多故事。这里我就不展开了,后续有同事会专门分享。
到了第四阶段,我们开始做深度定制。目前深度定制主要是两个方向,第一个围绕replication,怎么做更好一致性和更好性能的复制;另外一个方向就是基于SSD Cluster2.0的存储架构,怎么解决数据一致性和高HA的问题。
总体来讲,我们最新TXSQL版本现在自研技术有10多个,从社区移植的技术有30多个。
好了,今天我的分享就到这里。谢谢大家。