基于UserCF算法实现电影推荐
0.总结
Get to the points firstly, the article comes from lawsonAbs!
- 使用开源数据集,数据在这里下载
- 使用基于UserCF的推荐算法实现电影推荐
- 本代码放在了我的GitHub中,欢迎大家
fork & star
1.思想
UserCF 其实是属于协同过滤算法的一种。其核心思想是 基于“相似度” 来完成推荐。
1.1 实现步骤
下面按照具体步骤逐一叙述:
- step 1.得到用户的正反馈信息向量【这里的正反馈信息指的是:用户喜欢的商品信息。比如点赞过的,浏览时长超过某时间值的商品,然后分别记录这种商品】。
举例子,假设有如下的评分信息:
userId movieId rate timestamp
650 612 4 891369656
650 96 4 891369479
650 849 2 891381745
650 654 3 891369890
650 416 3 891387312
650 715 3 891383206
那么我们得到的用户正反馈向量则可表示如下:
| 电影Id的评分 | 612 | 96 | 849 | 654 | … |
|---|---|---|---|---|---|
| 用户id=650 | 4 | 4 | 2 | 3 | … |
- step 2.计算出用户的相似矩阵,并找出与用户A最为相似的几个用户【可以使用优先队列实现,在我的代码中,我取了top-10】
根据步骤一,已经可以得到了所有用户的评分向量了,我们把这些向量放一起,那么就可以得到一个由用户和商品共同组成的一个矩阵,这个矩阵就是俗称的共现矩阵【共现的是用户和商品】。共现矩阵示例如下:
| 用户id \ 电影id | 96 | … | 849 | 654 | … |
|---|---|---|---|---|---|
| … | … | … | … | … | … |
| 650 | 4 | … | 2 | 3 | … |
| … | … | … | … | … | … |
那么接下来就可以计算这些用户间的一个相似度了。计算相似度的方法有很多,常用的算法也都十分简单,例如:余弦相似度;皮尔逊相关系数等等。这并非本文核心内容,这里就采用了最基础的余弦相似度来计算相似度。余弦相似度的计算公式如下:
假设有两个向量:a 和 b,其都是n维行向量,如下所示:
a = [ a 1 , a 2 , . . . , a n , ] a = [a_{1},a_{2},...,a_{n},] a=[a1,a2,...,an,]
b = [ b 1 , b 2 , . . . , b n , ] b = [b_{1},b_{2},...,b_{n},] b=[b1,b2,...,bn,]
那么相似度计算公式就是:
s i m = c o s ( θ ) = a ∗ b ∣ a ∣ ∗ ∣ b ∣ sim = cos(\theta) = \frac{a*b}{|a|*|b|} sim=cos(θ)=∣a∣∗∣b∣a∗b
得到的两两用户之间的相似度,遍历所有的用户,在O(N2)的复杂度下就可以得到所有用户间的相似度了。仍然用例子来说:
现有用户A,B,C。其对商品评分的信息分别如下:
| 用户\商品id | 1 | 2 | 3 |
|---|---|---|---|
| A | 2 | 1 | 3 |
| B | 2 | 0 | 1 |
| C | … | … | … |
分别计算其相似度:
A = [2,1,3]
B = [2,0,1]
那么用户A与用户B 之间的相似度就是
s i m = 2 ∗ 2 + 1 ∗ 0 + 3 ∗ 1 2 ∗ 2 + 1 ∗ 1 + 3 ∗ 3 ∗ 2 ∗ 2 + 0 ∗ 0 + 1 ∗ 1 = 7 14 ∗ 5 = 0.837 sim = \frac{2*2+1*0+3*1}{\sqrt{2*2+1*1+3*3} * \sqrt{2*2+0*0+1*1}} = \frac{7}{\sqrt{14} * \sqrt{5}} = 0.837 sim=2∗2+1∗1+3∗3∗2∗2+0∗0+1∗12∗2+1∗0+3∗1=14∗57=0.837
同样的计算方法可以得到其余向量间的相似度。我们假设得到了该三个用户的 相似度矩阵,如下所示:
| sim | A | B | C |
|---|---|---|---|
| A | * | 0.837 | 0.3 |
| B | 0.837 | * | 0.7 |
| C | 0.3 | 0.7 | * |
通过相似矩阵,可以很明显的看到,与用户A最像似的是用户B。那么当我们为用户A推荐商品时,我们着重考虑与其最相似的用户B【着重的意思是带有一个权重去做计算,后面会有提及】
- step 3.根据得到的top 10 计算出用户A尚未看过但是最可能想看的电影。计算方法如下:
这里假设就是要为用户A计算出推荐商品,然后我们根据用户相似矩阵找出与其最相似的top-n个用户,根据top-n个用户的正反馈向量信息,可以得到一个商品Id集合【这个集合中包含的是与用户A相似用户所喜欢的商品,那么这些商品可能也是用户A所喜欢的。当然在这个集合中要把用户A喜欢过的商品剔除掉】,然后结合用户间的相似权重,以及相似用户的打分信息,将二者相乘就得出了该用户被推荐的概率,遍历所有的相似用户,并把推荐权值和累加,最后按照从高到低排序,得到的top-k 就是将推荐给用户A的商品。
计算公式如下:
p a j = ∑ i = 1 n R i a ∗ Q i j p_{a j} = \sum_{i=1}^{n} {R_{i a}} * {Q_{i j}} paj=i=1∑nRia∗Qij
公式以及叙述中涉及的几个名词:
(1)top-n: 相似用户 【指的是与用户A最为相似的用户,根据相似矩阵得到】
(2)Ria表示的是第i个人与用户a的相似度;Qij表示第i个人对电影j的兴趣度【我们按照其评分来计算】;二者相乘计算出来的结果就是Paj,表示用户a对电影j的兴趣值。
(3)这样我们就预测出用户A对电影j的兴趣。然后将j取遍所有的电影集合【实际生产中可以不这么做,只需要取出相似度高的用户中访问过的电影的并集即可】,那么就得出其对各部电影的可能感兴趣度,最后排个序取前5部。
2.具体代码
2.1 数据来源
这个数据在文件夹中已经被解释的很清楚了,这里我就不再废言了。
2.2 主要数据结构
-
优先队列
使用优先队列为了更好的保留top-n相似的用户,以及最后top-k的推荐商品。所以需要学习一下如何定义优先队列的“优先级”定义方式 -
字典
使用字典存储用户评分信息
2.3 简单的优化
当商品列表很大时,如果采用上述那种方法去计算两个用户的相似度,将会耗费非常大的内存。一种较为好的实现方式就是只存有评分的商品信息。比如一个用户只对id=2345的电影评分为4,那么我们就存储为{2345:4},即用一个字典存储用户的评分信息而不是 用类“one-hot”编码的方式。
2.4主要代码
-
项目结构
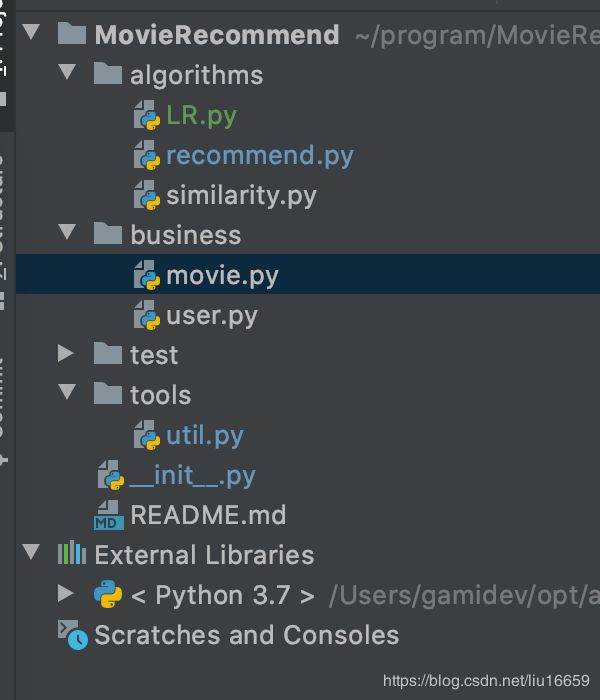
(1)business 指的是业务包
比如用户类; 商品类 等信息都是放在这里的
(2)util 指的是工具包
常用的工具包,如:读取csv文件; 处理行信息等等
(3)algorithms 指的是实现推荐算法的包
如相似度计算; UseCF ; ItemCF; LR 等等 -
代码实现流程
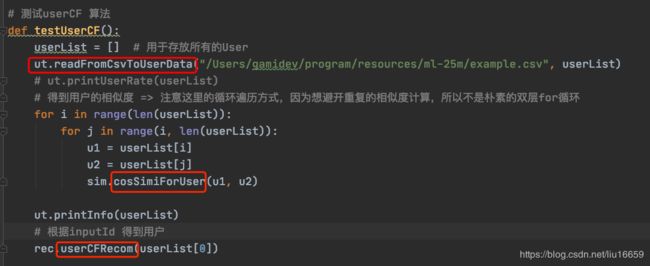
对应的三行代码的功能是:
(1)读取csv文件,因为原本数据集中的rating.csv文件较大,小电脑的运行速度根本不够,所以我从中抽取搞了一个小样本出来名为:example.csv 用于做测试。
"""
功能:读取csv文件
Parms:filePathName: 需要读取的文件地址(注意只有输入 "/Users/gamidev/program/MovieRecommend/resources/ml-25m/ratings.csv" 这样
的内容才算正确)
cfStyle: 表明
"""
def readFromCsvToUserData(filePathName,userList):
# 判断文件路径是否正确
with open(filePathName) as file: # 这句话是什么意思 => 打开filePathName所指的那个文件,然后将其存储在文件对象file中
ratingReader = csv.reader(file)
next(ratingReader) # 摆脱第一行的数据
for line in ratingReader:
# 为每个用户形成一个字典
userExtract(line, userList)
user.rateInfo = rating
userList.append(user)
"""
从每行中提取有效信息,形成一个字典;
这个line应该是一个列表
为用户形成数据信息,故为userExtract()
"""
def userExtract(line, userList):
userId, movieId, rate = line[0:-1]
userId = int(userId)
movieId = int(movieId)
global curUserId, user, rating, movies_read
if userId != curUserId:
# step 1.赋值
user.movies_read = movies_read
user.rateInfo = rating
if rating: # 防止加入空用户
userList.append(user) # 清空dict 中的值
# step 2.重置
user = User(userId, str(userId), str(userId)) # 新建一个User
curUserId = userId
rating = {}
movies_read = [] #
movies_read.append(movieId)
rating[int(movieId)] = float(rate) # 转换为数字
(2)计算各个用户间的相似度
# 余弦相似度
# 传入的是俩个用户引用,计算其相似度
def cosSimiForUser(u1,u2):
# 分别得到两个人的评分
rate1 = u1.rateInfo
rate2 = u2.rateInfo
# 得到两个向量的长度,并将其相乘得到 multi2
lenA = ut.getLenOfVector(rate1)
lenB = ut.getLenOfVector(rate2)
multi2 = lenA * lenB
multi1 = 0 # 记录点乘的结果
key1 = list(rate1.keys()) # 转换成键列表
key2 = list(rate2.keys())
i = 0
j = 0
lK1 = len(key1)
lK2 = len(key2)
while i < lK1 and j < lK2:
# 在下面这个while循环中加入j
while i < lK1 and j < lK2 and key1[i] < key2[j]:
i += 1
while i < lK1 and j < lK2 and key2[j] < key1[i]:
j += 1
if i < lK1 and j < lK2 and key1[i] == key2[j]:
multi1 += (rate1[key1[i]]) * (rate2[key2[j]])
i += 1 # 再分别往后移动一位
j += 1
res = 0 # 预定义
if multi2 != 0 : # 除数不能为0
res = multi1/multi2 # 最后计算出的相似度
print("用户", u1, "和用户", u2, "的点乘结果是:",multi1,";模长乘积是:",multi2,";余弦相似度是:",res)
if u1.simFriends.qsize() > 10: # 弹出队列首部
u1.simFriends.get()
if u2.simFriends.qsize() > 10:
u2.simFriends.get()
if u1 is not u2: # 如果是同一个用户
# 优先队列中
u1.simFriends.put((res,u2))
u2.simFriends.put((res,u1))
return res
(3)为用户计算推荐商品【在本文中,就是计算推荐的电影】
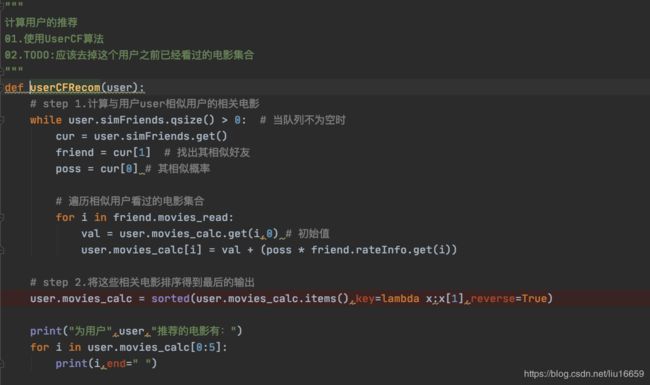
(4)最后的执行效果如下所示:
