linux内存映射(一)
参考:https://blog.csdn.net/godleading/article/details/18702029
https://blog.csdn.net/qq_21435127/article/details/80481546
一. 内存映射原理
由于所有用户进程总的虚拟地址空间比可用的物理内存大很多,因此只有最常用的部分才与物理页帧关联。这不是问题,因为大多数程序只占用实际可用内存的一小部分。在将磁盘上的数据映射到进程的虚拟地址空间的时,内核必须提供数据结构,以建立虚拟地址空间的区域和相关数据所在位置之间的关联,linux软件系统多级页表映射机制

注:上图中的最右侧page,代表软件层面的页帧率,并非真正的物理内存。真正的物理内存也会分页,名称为页框,页帧到页框的转换则是有MMU自动完成的。以下讨论均不考虑MMU(MMU完成的工作作为黑箱看待)。
二. Linux的页表实现
一级页表
一个32位逻辑地址空间的计算机系统,总地址4G字节,页大小为4KB,则有4G/4K = 1M个页,那么页表中需要存放1M个条目(每个条目代表一个页)。假设每个条目占4B,则需要4M字节内存来存放页表。
每个进程都需要管理所有4G内存,所以每个进程都要4M来存放页表,极其浪费。
二级页表
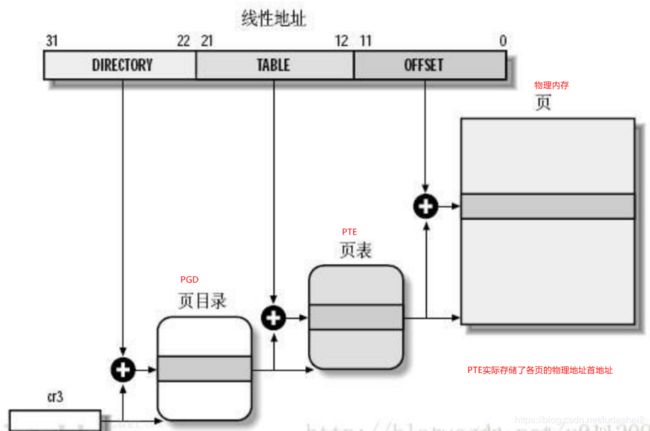
虚拟地址到物理页地址的转换过程如下:
-
结合在CR3寄存器中存放的页目录(page directory, PGD)的这一页的物理地址,再加上从虚拟地址中抽出高10位叫做页目录表项(内核也称这为pgd)的部分作为偏移, 即定位到可以描述该地址的pgd;
-
从该pgd中可以获取可以描述该地址的页表的物理地址,再加上从虚拟地址中抽取中间10位作为偏移, 即定位到可以描述该地址的pte;
-
在这个pte中即可获取该地址对应的页的物理地址, 加上从虚拟地址中抽取的最后12位,即形成该页的页内偏移, 即可最终完成从虚拟地址到物理地址的转换。
其中 虚拟地址的组成:
DIRECTORY [22:31] 可表示1024个页目录(PGD)
TABLE[12:21] 可表示1024个页表(PTE)
OFFSET[22:31] 可表示4096个物理内存
因此最大映射物理内存大小为 102410244096 = 4G/Byte
三级页表
当X86引入物理地址扩展(Pisycal Addrress Extension, PAE)后,可以支持大于4G的物理内存(36位),但虚拟地址依然是32位,原先的页表项不适用,它实际多4 bytes被扩充到8 bytes,这意味着,每一页现在能存放的pte数目从1024变成512了(4k/8)。相应地,页表层级发生了变化,Linus新增加了一个层级,叫做页中间目录(page middle directory, PMD)
办法是针对使用2级页表的架构,把PMD抽象掉,即虚设一个PMD表项。这样在page table walk过程中,PGD本直接指向PTE的,现在不了,指向一个虚拟的PMD,然后再由PMD指向PTE。这种抽象保持了代码结构的统一。
该方法其实就是在原有虚拟地址组成中的几位作为PMD索引:
|31| -----PGD-----|29|-----PMD-----| 20|-----PTE-----|11|----OFFSET|-----|0|
四级页表
硬件在发展,3级页表很快又捉襟见肘了,原因是64位CPU出现了, 比如X86_64, 它的硬件是实实在在支持4级页表的。它支持48位的虚拟地址空间(不过Linux内核最开始只使用47位)。如下:
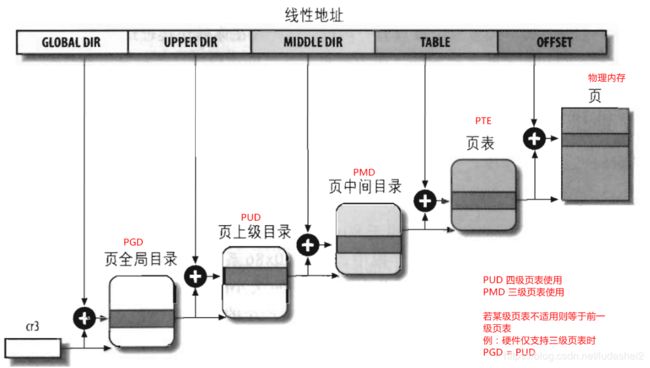
需注意软件的页表映射依赖于硬件所支持的映射级别,目前ARM64支持2/3/4 级映射,假如ARM配置的映射级别为3级,那么linux的映射表中 PGD=PUD,即实际为三级映射。
文件索引节点
设文件索引节点中有7 个地址项,其中4 个地址项是直接地址索引,2 个地址项是一级间
接地址索引,1 个地址项是二级间接地址索引,每个地址项大小为4B,若磁盘索引块和磁盘数据块
大小均为256B,请计算可表示的单个文件最大长度。
每个索引块上可以存放的索引项为256B/4B=26 =64个。直接索引的数据块有4 块;两个一级
间接索引指向的数据块有2×26=27 = 128个;一个二级间接索引指向的数据块有1×26×26=212 个。所以单个文件最大可以有4+27+212(=4228)个数据块。
文件大小为 4228×256B=(4+27+212)×28=33KB+1MB=1057KB
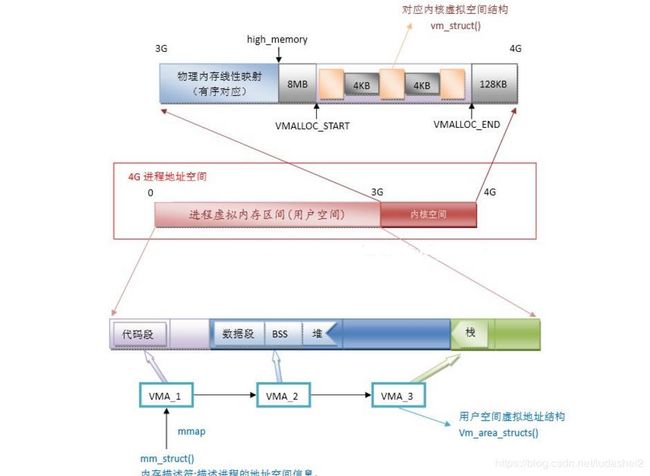
三. 虚拟空间分布
linux将整个虚拟空间分为用户空间与内核空间,且每个用户进程均占用一份完整的用户虚拟空间
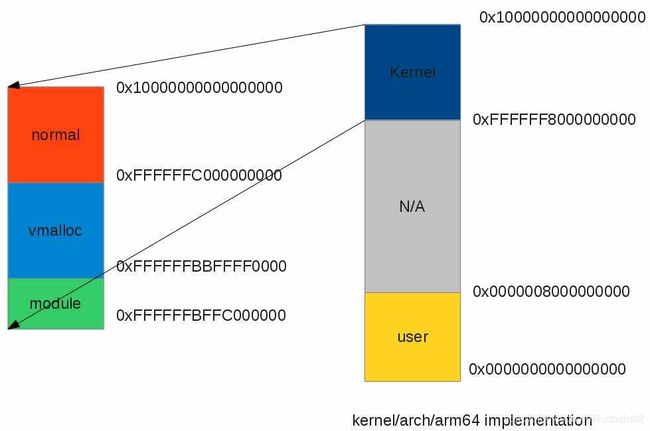
上图为64位系统的虚拟地址空间分布用户空间大小为512G,32位系统用户空间结束地址为0xc0000000,大小为3G.
用户空间
用户虚拟地址空间大小为3G,每个应用程序均独占完整的3G虚拟空间。这里应该可以看出,真是的物理内存不可能等于虚拟内存,因为同一时间会有众多进程运行,每一进程均拥有3G内存,而实际物理内存不可能满足所有进程的需求。此时上面说到的内存映射便发挥了作用。
- 一般而言,一个进程虽然拥有3G虚拟内存访问权限,但是实际需要的内存可能很少,另外一个进程大部分的主体,比如代码段,只读数据段等并不需要实时驻留在内存中,因为这些内容在大多数时间是“死的”。因此内存映射的第一个作用就是:
只会将某一进程此刻需要的内存大小映射到物理内存,其它暂时不需要的内容交换到硬盘存储即可。当进程需要使用在硬盘中的内容或者需要动态申请内存时,操作系统会利用缺页操作,触发一次内存映射,将另外的物理内存映射进虚拟内存,供程序使用,这样对于进程而言,则认为内存总是够用的。 - 各个进程均拥有3G虚拟内存,那么操作系统是如何做到各进程所使用的实际物理内存不会互相占用呢?实际上,各个进程均有自己的内存映射表。任意一个时刻,在一个CPU上只有一个进程在运行。所以对于此CPU来讲,在这一时刻,整个系统只存在一个4GB的虚拟地址空间,这个虚拟地址空间是面向此进程的。当进程发生切换的时候,虚拟地址空间也随着切换。由此可以看出,每个进程都有自己的虚拟地址空间,只有此进程运行的时候,其虚拟地址空间才被运行它的CPU所知。在其它时刻,其虚拟地址空间对于CPU来说,是不可知的。所以尽管每个进程都可以有4 GB的虚拟地址空间,但在CPU眼中,只有一个虚拟地址空间存在。虚拟地址空间的变化,随着进程切换而变化。
内核空间
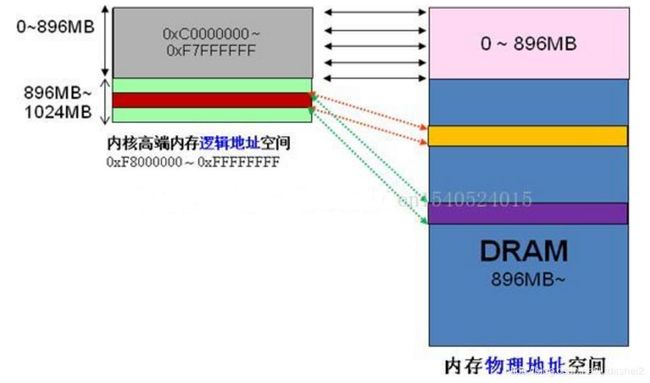
内核空间具有相对独立的特性。即内核的虚拟地址空间范围是自己独有的,不与任何用户进程共享(内核实质也是一个进程)。这样可保证内核空间的安全性。但是由于内核虚拟地址空间较小0xc000000~0xFFFFFFFF 仅有1G大小,这一大小往往小于实际的物理内存,因此内核空间需要额外的方式来访问到所有物理内存。
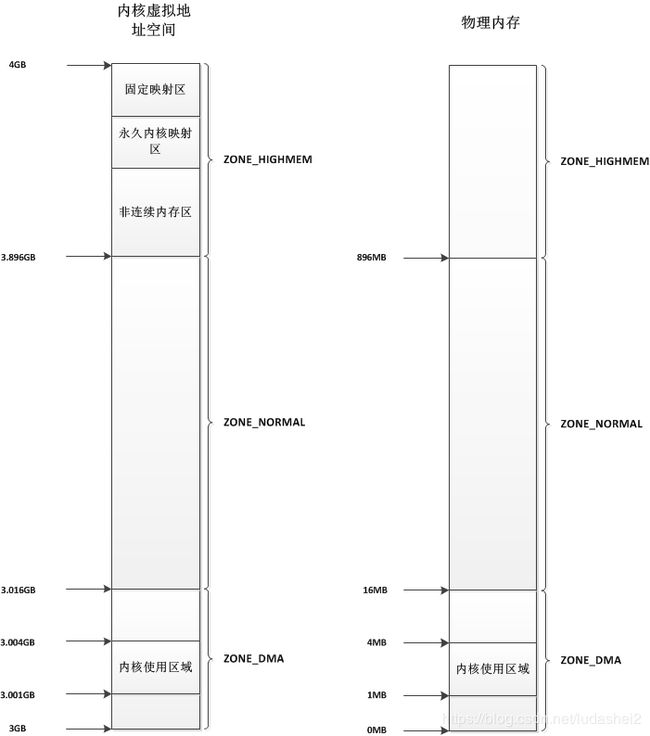
由上图可知,内核空间又分为三大部分:
ZONE_DMA :0XC000000 + 16M 线性映射区
该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA。例如dma_alloc_coherent函数获取的内存就是ZONE_DMA内存
ZONE_NORMAL :0XC100000 + 880M 线性映射区
该区域的物理页面是内核能够直接使用的,比如内核程序中代码段、全局变量以及kmalloc获取的堆内存等。从此处获取内存一般是连续的,但是不能太大。
ZONE_HIGHMEM :0xF8000000 + 28M
该区域比较负责又可细分为三部分:
- 非连续内存区
非连续内存分配是指将物理地址不连续的页框映射到线性地址连续的线性地址空间,主要应用于大容量的内存分配。采用这种方式分配内存的主要优点是避免了外部碎片,而缺点是必须打乱内核页表,而且访问速度较连续分配的物理页框慢。函数vmalloc即是通过该部分虚拟地址来映射物理内存。 - 永久内核映射区
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。 - 临时固定映射区
fixmap和pkmap的最大区别是fixmap不会被阻塞,因此可以在中断上下文中使用。实际上每次fixmap都是可以成功执行映射的,原因是fixmap不会动态申请映射,它是以固定映射的方式进行的,如果我们传入了一个映射type,它就肯定会执行对应的映射,而把之前的映射冲刷掉,因此fixmap的映射关系是靠内核代码来进行维护的,所以内核需要保证同一个映射区不被重复使用,从而出现错误。
前 面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为 0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。
例 如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0×80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0×80000000 ~ 0x800FFFFF的内存。
四.内核空间与用户空间交互
系统调用
系统调用的可实现进程由用户态切换至内核态。但是通过上面分析已经了解,用户进程与内核进程相互分离的,那么在进行系统调用时参数传递是如何实现的呢?
解决这一办法的思路是:数据拷贝。因为无论是用户地址空间还是内核地址空间均为虚拟地址空间,因此在做参数传递时,只需要将在用户地址空间存放的参数拷贝至内核地址空间即可。完成拷贝的函数就是大家熟知的copy_from_user() ©_to_user().
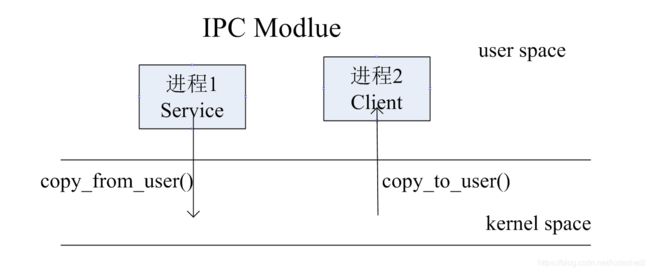
上图表示某一用户进程将一组数据传递给内核,内核经过处理后将数据返回至用户进程。该过程涉及到数据在两块内存区域的转移:用户虚拟内存地址对应的物理内存与内核虚拟内存地址对应的物理内存。
mmap函数
函数原型:
void *mmap{
void *addr; //映射区首地址,传NULL
size_t length; //映射区的大小
//会自动调为4k的整数倍
//不能为0
//一般文件多大,length就指定多大
int prot; //映射区权限
//PROT_READ 映射区比必须要有读权限
//PROT_WRITE
//PROT_READ | PROT_WRITE
int flags; //标志位参数
//MAP_SHARED 修改了内存数据会同步到磁盘
//MAP_PRIVATE 修改了内存数据不会同步到磁盘
int fd; //要映射的文件对应的fd
off_t offset; //映射文件的偏移量,从文件的哪里开始操作
//映射的时候文件指针的偏移量
//必须是4k的整数倍
//一般设置为0
作者:哆啦尼可夫
来源:CSDN
原文:https://blog.csdn.net/wk_bjut_edu_cn/article/details/80467749
版权声明:本文为博主原创文章,转载请附上博文链接!
mmap函数分为用户空间与内核两版
用户空间mmap调用
用户空间读写文件时,需经过内核,数据拷贝多了一次。通过mmap函数,可以建立用户虚拟空间到文件所在物理页的直接映射建立该映射后,可以像直接操作内存一样读写文件(比如读写数组),减少一次用户到内核的数据拷贝。
fd = open(argv[1], O_RDWR);
/* 将文件映射至进程的地址空间 ,mmaped 为文件所在物理页对应的虚拟内存地址*/
mmaped = (char *)mmap(NULL, sb.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
/* 映射完后, 关闭文件也可以操纵内存 */
close(fd);
mmaped[5] = '$';
msync(mmaped, sb.st_size, MS_SYNC)
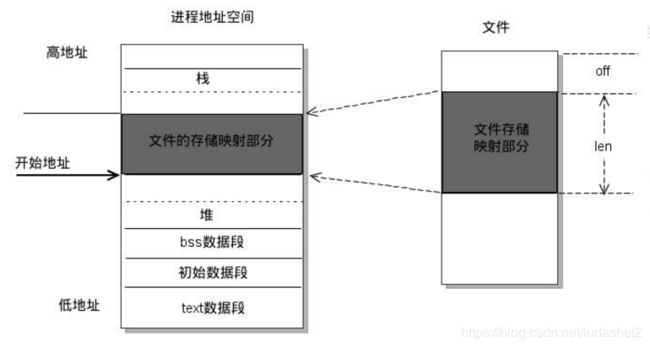
内核空间mmap实现
直接打开一个磁盘文件,实际是调用了文件系统提供的mmap版本。但是对于开发linux驱动的工程师来说,需自己实现对应设备文件的mmap函数,例如framebuffer这种设备需要较高频率大数据读写,因此不能容忍内核空间到用户空间的数据拷贝,因此驱动需开发自己的mmap函数供用户进程调用,驱动mmap实现流大致为:
-
通过kmalloc, get_free_pages, vmalloc等分配一段虚拟地址
-
如果是使用kmalloc, get_free_pages分配的虚拟地址,那么使用virt_to_phys()将其转化为物理地址,再将得到的物理地址通过”phys>>PAGE_SHIFT”获取其对应的物理页面帧号。或者直接使用virt_to_page从虚拟地址获取得到对应的物理页面帧号。
如果是使用vmalloc分配的虚拟地址,那么使用vmalloc_to_pfn获取虚拟地址对应的物理页面的帧号。 -
对每个页面调用SetPageReserved()标记为保留才可以。
-
通过remap_pfn_range为物理页面的帧号建立页表,并映射到用户空间。
//内存分配 buffer = (unsigned char *)kmalloc(PAGE_SIZE,GFP_KERNEL); //将该段内存设置为保留 SetPageReserved(virt_to_page(buffer)); //得到物理地址 phys = virt_to_phys(buffer); //将用户空间的一个vma虚拟内存区映射到以page开始的一段连续物理页面上 remap_pfn_range(vma, vma->vm_start, phys >> PAGE_SHIFT,//第三个参数是页帧号,由物理地址右移PAGE_SHIFT得>到 vma->vm_end - vma->vm_start, vma->vm_page_prot)
mmap函数并非实现用户空间与内核空间的交互,而是用户空间试图绕过内核空间,直接操作物理页
四. 完整的linux系统下内存分布图