MxNet 实践(1):Spatial Transformer Networks
论文:Spatial Transformer Networks
演示:google drive
博客:kevinzakka
代码:自己实现的代码
————————————————————
-
- 摘要
- 网络结构
- 特点
- 结构
- 1 Localisation Net
- 2 Grid Generator
- 3 Sampler
- 代码
- 1 使用Gluon
- 11 STN结构示例
- 12 主体网络
- 2 使用MxNetsymbol
- 3 注意
- 4 可视化
- 5 可视化结果
- 6 训练结果
- 1 使用Gluon
- 参考资料
摘要
卷积神经网络在图像分类,目标检测等任务上显示了强大的特征提取能力,且CNN本身具有一定的位移、旋转、尺度不变性。然而,对于一些图像数据变形的情况,CNN并不能自适应地学习图像的变形情况。
Spatial Transformer Networks (以下均简称STN)提供了一种可微分的网络结构,不需要关键点的标定,能够根据分类或者其它任务自适应地将数据进行空间变换和对齐(包括平移、缩放、旋转以及其它几何变换等)。
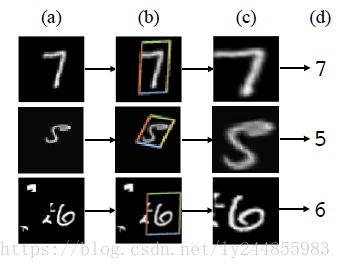
上述图片是将STN作为MNIST分类网络第一层的结果,我们注意到STN学会了如何更“健壮”地进行图像分类:通过放大和消除背景噪声,它已经“标准化”输入数据以提高分类效果。 详细动画 here
网络结构
特点
论文作者提出STN 有三个重要的特性:
- 模块化: STN可以插入到现有深度学习网络结构的任意位置,且只需要较小的改动。
- 可微分性: STN 是一个可微分的结构,可以进行反向传播,整个网络可以端到端训练。
- 动态性: 与对所有输入进行相同的pooling操作相比,STN对每一特征图输入采样,并主动学习空间变换。
结构

如上图所示,STN由Localisation net (定位网络),Grid generator(网格生成器)和Sampler(采样器)三部分构成。
2.1 Localisation Net
Localisation 网络的目标是学习空间变换参数 θ ,无论通过全连接层,还是卷积层,Localisation网络最后一层必须回归产生空间变换参数 θ 。
- 输入 特征图 U ,其大小为 (H, W, C)
- 输出 空间变换参数 θ (对于仿射变换来说,其大小为(6,))
- 结构 全连接,卷积均可,记作 θ=floc(U)
2.2 Grid Generator
该层利用Localisation Net 输出的空间变换参数θ,将输入的特征图进行变换,以仿射变换为例,将输出特征图上某一位置 (xti,yti) 通过参数 θ 映射到输入特征图上某一位置 (xsi,ysi) ,计算公式如下:
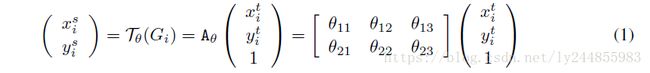
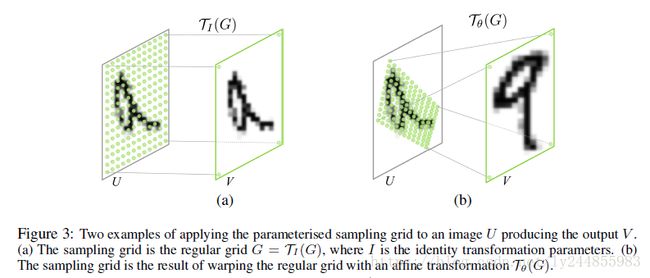
网格参数恒等映射和应用仿射变换后结果如下:
2.3 Sampler
实际上 (xsi,ysi) 往往会落在原始输入特征图的几个像素点中间,因此需要利用双线性插值来计算出对应该点的灰度值。需要补充的是,文中在变换时用都是标准化坐标,即 xi,yi∈[−1,1] 。实际采样形式如下:
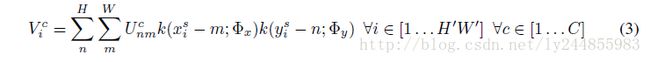
- Φx 和 Φy 是 采样核函数 k() 的参数,定义了图像插值的形式(比如,双线性)。
- Ucnm 是输入特征图 U 通道 c 中位置为 (n,m) 的值。
- Vci 是输出特征图 V 通道 c 中位置为 (xti,yti) ,即像素点 i 的值。
注意到采样是对输入的每一个通道的确定性映射,这样做在通道上维持了空间的一致性。
理论上,只要能对 xsi 和 ysi 求得次梯度的任何采样核函数都可以使用。使用整数插值的情况如下:

其中, ⌊x+0.5⌋ 对 x 向下取整,即取最近邻的整数。而 δ() 是Kronecker delta函数。这样的采样核将对 (xsi,ysi) 的最近邻像素的值复制得到输出位置 (xti,yti) 的值。在作者的实验中采用的是双线性插值:

代码
3.1 使用Gluon
3.1.1 STN结构示例
class STN(nn.HybridBlock):
##继承HybridBlock模块,可以方便的hybrid,将命令式编程转换为符号式提升性能但损失了一定的灵活性
def __init__(self):
super(STN, self).__init__()
with self.name_scope():
# 使用name_scope可以自动给每一层生成独一无二的名字方便读取特定层
# Spatial transformer localization-network
# loc 定义了两层卷积网络
loc = self.localization = nn.HybridSequential()
loc.add(nn.Conv2D(8, kernel_size=7))
loc.add(nn.MaxPool2D(strides=2))
loc.add(nn.Activation(activation='relu'))
loc.add(nn.Conv2D(10, kernel_size=5))
loc.add(nn.MaxPool2D(strides=2))
loc.add(nn.Activation(activation='relu'))
# 采用两层全连接层,回归出仿射变换所需的参数θ(6,)
# Regressor for the 3 * 2 affine matrix
fc_loc = self.fc_loc = nn.HybridSequential()
fc_loc.add(nn.Dense(32,activation='relu'))
# 将该层w初始化为全零,b初始化为[1,0,0,0,1,0]
fc_loc.add(nn.Dense(3 * 2,weight_initializer='zeros'))
# Spatial transformer network forward function
# 使用hybrid_forward需要增加F参数,它会自动判定前向过程中调用nd还是sym
def hybrid_forward(self,F, x):
xs = self.localization(x)
xs = xs.reshape((-1, 10 * 3 * 3))
theta = self.fc_loc(xs)
theta = theta.reshape((-1, 2*3))
# MxNet 已经定义好了相应的产生网格和采样的函数接口
grid = F.GridGenerator(data=theta, transform_type='affine',target_shape=(28,28),name='grid')
x = F.BilinearSampler(data=x,grid=grid,name='sampler' )
return x 3.1.2 主体网络
class Net(nn.HybridBlock):
def __init__(self):
super(Net, self).__init__()
# 对输入图片进行STN变换后送入一个简单的两层卷积,两层全连接网络
with self.name_scope():
self.model = nn.HybridSequential()
self.model.add(STN())
self.model.add(nn.Conv2D(10, kernel_size=5))
self.model.add(nn.MaxPool2D())
self.model.add(nn.Activation(activation='relu'))
self.model.add(nn.Conv2D(20, kernel_size=5))
self.model.add(nn.Dropout(.5))
self.model.add(nn.MaxPool2D())
self.model.add(nn.Activation(activation='relu'))
self.model.add(nn.Flatten())
self.model.add(nn.Dense(50))
self.model.add(nn.Activation(activation='relu'))
self.model.add(nn.Dropout(.5))
self.model.add(nn.Dense(10))
def hybrid_forward(self,F, x):
for i,b in enumerate(self.model):
x = b(x)
return x3.2 使用MxNet.symbol
def get_loc(data, attr={'lr_mult':'0.01'}):
"""
the localisation network in stn, it will increase acc about more than 1%,
when num-epoch >=15
"""
## 与gluon写法一致,只是调用的mx.symbol模块
loc = sym.Convolution(data=data, num_filter=8, kernel=(7, 7), stride=(1,1))
loc = sym.Activation(data = loc, act_type='relu')
loc = sym.Pooling(data=loc, kernel=(2, 2), stride=(2, 2), pool_type='max')
loc = sym.Convolution(data=loc, num_filter=10, kernel=(5, 5), stride=(1,1))
loc = sym.Activation(data = loc, act_type='relu')
loc = sym.Pooling(data=loc, kernel=(2, 2),stride=(2, 2), pool_type='max')
loc = sym.FullyConnected(data=loc, num_hidden=32, name="stn_loc_fc1", attr=attr)
loc = sym.Activation(data = loc, act_type='relu')
# loc = sym.Flatten(data=loc)
loc = sym.FullyConnected(data=loc, num_hidden=6, name="stn_loc_fc2", attr=attr)
return loc
def get_symbol(num_classes=10, flag='training' ,add_stn=True, **kwargs):
data = sym.Variable('data')
if add_stn:
## mx.sym中写好了STN层包括grid generator和sampler,只需要送入相应参数θ
data = sym.SpatialTransformer(data=data, loc=get_loc(data), target_shape = (28,28),
transform_type="affine", sampler_type="bilinear")
# first conv
conv1 = sym.Convolution(data=data, kernel=(5,5), num_filter=10)
relu1 = sym.Activation(data=conv1, act_type="relu")
pool1 = sym.Pooling(data=relu1, pool_type="max",
kernel=(2,2), stride=(2,2))
# second conv
conv2 = sym.Convolution(data=pool1, kernel=(5,5), num_filter=20)
relu2 = sym.Activation(data=conv2, act_type="relu")
pool2 = sym.Pooling(data=relu2, pool_type="max",
kernel=(2,2), stride=(2,2))
drop1 = mx.sym.Dropout(data=pool2)
# first fullc
flatten = sym.Flatten(data=drop1)
fc1 = sym.FullyConnected(data=flatten, num_hidden=50)
relu3 = sym.Activation(data=fc1, act_type="relu")
# second fullc
drop2 = mx.sym.Dropout(data=relu3,mode=flag)
fc2 = sym.FullyConnected(data=drop2, num_hidden=num_classes)
# loss
net = sym.SoftmaxOutput(data=fc2, name='softmax')
return net3.3 注意
对于Localisation学习的参数 θ 可以初始化为[1,0,0,0,1,0],相当于恒等映射,没有对输入图像做空间变换。可将Localisation的最后一层的w的初始化为0,b初始化为[1,0,0,0,1,0]
b = net.model[0].fc_loc[1].bias
b.set_data(nd.array([1, 0, 0, 0, 1, 0]))3.4 可视化
def visualize_stn():
# 随机读取其中一个batch数据进行可视化
for i,(data,_) in enumerate(test_data):
if i==1:
break
data = data.as_in_context(ctx)
# 只做STN部分
output = net.model[0](data)
# convert_image_np函数 转换图片通道为(W,H,C)便于显示,以及标准化
in_grid = convert_image_np(make_grid(data))
out_grid = convert_image_np(make_grid(output))
# Plot the results side-by-side
fig, axarr = plt.subplots(1, 2)
axarr[0].imshow(in_grid)
axarr[0].set_title('Dataset Images')
axarr[1].imshow(out_grid)
axarr[1].set_title('Transformed Images')
# 将图片结果保存
fig.savefig('result/compare.jpg',dpi=256)3.5 可视化结果

3.6 训练结果
Train Epoch: 1 [0/60000 (0%)] Loss: 0.002750
Train Epoch: 1 [32000/60000 (53%)] Loss: 0.790990Test set: Average loss: 0.0072, Accuracy: 9196.0/10000 (92%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.000803 Train Epoch: 2
[32000/60000 (53%)] Loss: 0.260360Test set: Average loss: 0.0032, Accuracy: 9568.0/10000 (96%)
………………………………………………………………………………………………………………
………………………………………………………………………………………………………………
Train Epoch: 19 [0/60000 (0%)] Loss: 0.000084 Train Epoch: 19
[32000/60000 (53%)] Loss: 0.057609Test set: Average loss: 0.0008, Accuracy: 9833.0/10000 (98%)
Train Epoch: 20 [0/60000 (0%)] Loss: 0.000102 Train Epoch: 20
[32000/60000 (53%)] Loss: 0.056364Test set: Average loss: 0.0008, Accuracy: 9852.0/10000 (99%)
完整代码请移步我的github,欢迎star
参考资料
- Pytorch 教程
- MxNet 范例
- MxNet 初始化模型参数
- http://www.cnblogs.com/neopenx/p/4851806.html
- https://blog.csdn.net/xbinworld/article/details/69049680
- kevinzakka 博客