论文笔记之目标检测(2)-- GRP-DSOD
Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
文章:https://arxiv.org/abs/1712.00886
代码:https://github.com/szq0214/GRP-DSOD(还未公布)
结构:caffe netscope视图
作者:沈志强
-
- Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
- 文章摘要
- 文章背景
- 痛点
- 改进
- 主要贡献
- 方法详述
- DSOD
- 循环特征金字塔
- 下采样与上采样通道
- 循环策略
- 门控自适应校准
- 动机
- 门函数
- 实验
- 结论
- 参考文献
- Learning Object Detectors from Scratch with Gated Recurrent Feature Pyramids
文章摘要
作者受自己上一篇论文(DSOD)激励,研究了一种可以在目标检测中可以动态调整不同尺度的监督信息。新的网络有两个重要改进:
- 提出了一个recurrent feature-pyramid structure(循环特征金字塔结构)压缩丰富的空间和语义特征到单个预测层,可以压缩需要学习的参数(DSOD需要学习1/2,新方法只需用学习1/3)
- 提出了一个新颖的门控预测策略在基于不同目标尺寸的尺度预测上自适应地增强或减弱监督。
新的模型比原来的DSOD收敛更快(只有原来一半的迭代次数),且在小目标检测上表现更佳。
文章背景
痛点
和大多数新提出的框架,像SSD,DSSD,MS-CNN,FPN,ION,Focal loss等一样,DSOD也在单次过程中采用了特征金字塔。在不同的金字塔层中,一系列预测操作被应用于调整任意目标尺度。这存在两点不足:
- 当前特征金字塔设计有一个重大缺陷,每个金字塔层只有一个尺度的特征表达。像SSD,FPN等方法,特征层各自独立且没有任何交互。
- 另一关键限制在于,当前方法中每个金字塔层对最终的监督信息的贡献是固定的。
改进
作者基于此给出的改进方式:
- 提出了recurent feature pyramid,该结构可以拼接高水平的语义特征和低水平的空间特征到单个金字塔层中。文章后边的对照实验显示了该设计极大地提升了目标检测的性能,减少了模型参数。
应用了一个门控机制

想法来源
在小尺度上的目标很容易被细粒度特征(低水平)检测到,此时,从低水平特征得来的信号应该被增强
在大尺度上的目标很容易被粗粒度特征(高水平)检测到,此时,从高水平特征得来的信号应该被增强门控单元(详细描述于文中3.3节)
- channel-level attention
- global-level attention
- identity mapping
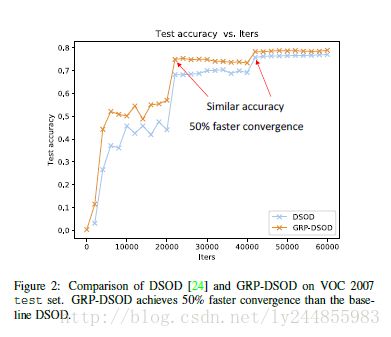
从上图可知,GRP-DSOD相比于DSOD可以更快收敛并达到更高精度。
主要贡献
- 提出了一个新颖的结构设计–循环特征金字塔,非常时候从头训练的目标检测网络,在收敛速度和精度上都得到了不错的提升。
- 提出了广泛适用于目标检测的门控机制,是第一个在目标检测方面尝试重新校正监督信息的。
- 在DSOD应用门控循环特征金字塔即GRP-DSOD成为表现最好的不需要预训练模型的目标检测器。
方法详述
DSOD
与SSD相比,DSOD替换VGGNet主网络为“Stem + Dense Block”的结构同时运用dense connections到多尺度预测层中。

如图所示,在每个尺度的预测层中,临近feature maps组合在一起,使预测层包含了不同水平的空间和语义信息。DSOD仅仅学习了一半新特征且重用一半。在GRP-DSOD中,同样采用了这样的策略,但仅仅学习了1/3新特征,重用了2/3,这使模型更为紧凑。
循环特征金字塔
为了在单个预测过程中充分利用多尺度CNN特征,组合来自低层的详尽的空间信息和高层的语义信息,提出了循环特征金字塔结构,主要包含三个部分:
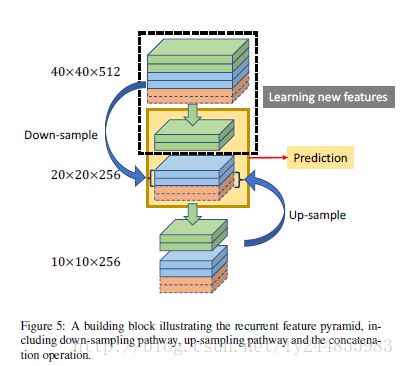
(如图所示重用了2/3特征,新学习了1/3特征)
其中,重用特征指来自下采样和上采样过程的特征,仅做了尺度调整,没有新的参数需要学习。新学习特征指主网络送入预测层的feature map 有新参数需要学习。
- 通过下采样块将低水平的feature map中的信息传到当前层并与当前层拼接;
- 通过上采样将高水平的语义信息传到当前层与当前层拼接;
- 在每个尺度的预测层中重复上述拼接操作
下采样与上采样通道
下采样通道,主要包含一个max pooling层(kernel size = 2×2, stride = 2)和一个 用于降维的1 × 1卷积层(kernel size = 1 × 1, stride = 1)。
上采样通道,在上方最近一层feature map采用双线性上采样的方式实现卷积转置操作并接一层1 × 1卷积层(kernel size = 1 × 1, stride = 1)。
于是在当前层拼接了下采样得来的细粒度信息以及上采样得来的粗粒度信息,使每个预测层含有丰富的多尺度特征。
循环策略
迭代拼接过程直到产生最粗粒度的block。对于320 × 320分辨率的输入图片,采用6个尺度预测目标,其中最精细的分辨率为40 × 40,最粗糙的分辨率为2 × 2。初始迭代,简单地选择预测层相邻尺度作为上采样和下采样的输入 。采用额外的160 × 160分辨率作为下采样的输入实现最精细的40 × 40的尺度,提升检测小物体的能力。
(ps:循环过程具体没看懂,代码作者也没有放出。望看懂的小伙伴批评指正)
门控自适应校准
动机
为了确保目标检测网络面对不同尺寸目标时采用有价值的尺度,即增加合适分辨率的有用特征,减少无用信息。受SENets[1]启发加入了两个水平的注意力机制和在每个预测层前的确定性映射。

门函数
O=Fgate(U)=Fr(Fg(Fc(U)))
作者在文中将门控机制的三个阶段做了定义(和上图一致)
Channel-level and Global-level Attention
channel-level attention 和 global-level attention自适应地增强或减弱不同尺度的监督信息。采用了Squeeze-and-Excitation block作为channel-level attention,共包含2个部分:
- 全局信息由squeeze stage Fsq (挤压过程)产生
- 通道水平重校正由excitation stage Fex (激励阶段)控制
因此定义 U˜=Fex(Fsq(U))
squeeze stage又可以看做在每个channel做global pooling的过程
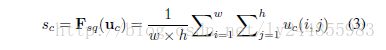
Sc 为S的第c个元素,S为U通过global pooling得到的c维的向量。exitiation stage可以看做两个全连接层加一个sigmiod激活函数。
![]()
因此, U˜ 也可以这样计算:
![]()
global attention使用squeeze stage的输出作为输入,修改exitiation stage只产生一个元素。新的exciation stage有如下定义:
![]()
最后, V˜ 定义如下:
![]()
确定性映射
使用按元素相加的操作得到最后的结果:
![]()

以上为使用门控函数前后feature map 可视化对比
实验
实验部分不再详述,具体可看作者论文第4章节
仅贴出重要结果对比图
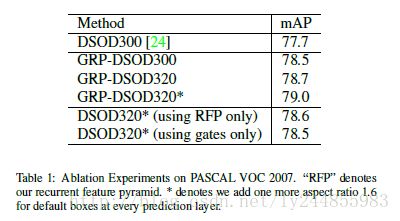
DSOD与REP-DSOP对比

VOC 2007及2012 测试结果图
结论
作者提出的GRP-DSOD模型适合从头开始训练的目标检测器,在速度和精度上都超越了DSOD。在VOC和MS COCO的其他实验中,作者猜测从头训练目标检测器还有很大的空间和潜能,甚至可以超越预训练模型。
参考文献
1.SE-NET