urllib库的基本函数使用及cookie的基本概念
urllib库
最基本的网络请求库。可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据。
在python3的urllib库中,所有和网络请求相关的方法,都被集成到urllib.request模块下面了。
urlopen函数:
from urllib import request
resp = request.urlopen('http://www.baidu.com')
print(resp.read(10))
print(resp.readline())
print(resp.readlines())
print(resp.getcode())1、URL:请求的URL
2、data:请求的data,如果设置了这个值,将变成post请求
3、返回值:返回一个http.client.HTTPResponse对象,这个对象是一个类文件句柄对象
方法有:read(size)、readline()、readlines()、getcode()等。
urlretrieve函数
方便的在将网站上的一个文件保存到本地:
from urllib import request
# '地址'+'保存名称'
request.urlretrieve('https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=1069870791,2525748285&fm=26&gp=0.jpg','sanli.jpg')urlencode函数
用浏览器发送请求时,如果url中包含了中文或者其他特殊字符,那么浏览器会自动的给我们进行编码。而如果使用代码发送请求,必须手动进行编码,这时就应该使用urlencode函数来实现。
urlencode可以把字典数据转换为URL编码数据
from urllib import parse
# urencode函数的用法
params = {'name':'黄鹏','age':19,'greet':'hello world!'}
result = parse.urlencode(params)
print(result)name=%E9%BB%84%E9%B9%8F&age=19&greet=hello+world%21
parse_qs函数:
可以将经过编码后的URL参数进行解码:
from urllib import parse
# parse_qs函数的用法
params = {'name':'hp','age':19,'greet':'hello world!'}
qs = parse.urlencode(params)
print(qs)
result = parse.parse_qs(qs)
print(result)name=%E9%BB%84%E9%B9%8F&age=19&greet=hello+world%21
{'name': ['hp'], 'age': ['19'], 'greet': ['hello world!']}
urlparse 和 urlsplit函数
有时拿到一个url,想对这个url的各个组成成分进行分割,那么此时可以使用urlparse或者urlsplit进行分割:
from urllib import parse
url = 'http://www.baidu.com/s;hello?wd=python&username=abc#1'
# urlparse 和 urlsplit的用法
result = parse.urlparse(url) # 多了一个'params'属性
# result = parse.urlsplit(url)
print('scheme:',result.scheme)
print('netloc:',result.netloc)
print('path:',result.path)
print('params:',result.params) # ;和?之间的东西
print('query:',result.query)
print('fragment:',result.fragment)
scheme: http
netloc: www.baidu.com
path: /s
params: hello
query: wd=python&username=abc
fragment: 1
request.Request类:
若想在请求时增加一些请求头(让请求成功率提升),那么必须使用request.Request类实现。
比如增加一个‘User-Agent’、‘cookie’…
url = 'https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36',
'referer':'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'cookie':'user_trace_token=20200510104034-98ab09b0-64ac-433c-89ec-7ff7df9fac5a; LGUID=20200510104034-27db9faf-db7d-40f9-a586-9b194c73299c;'
' _ga=GA1.2.557183537.1589078433; index_location_city=%E6%B7%B1%E5%9C%B3; '
'sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22171fc74fda3395-062e990d62214-d373666-1327104'
'-171fc74fda441b%22%2C%22%24device_id%22%3A%22171fc74fda3395-062e990d62214-d373666-1327104'
'-171fc74fda441b%22%7D; '
'JSESSIONID=ABAAAECAAEBABIIE0F9D767914DEF475ACA9E0801AFC85F; WEBTJ-ID=20200512103829-17206bf70fdcc-0081e574c33fdf-d373666-1327104-17206bf70ff826; '
'RECOMMEND_TIP=true; PRE_UTM=; PRE_HOST=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; LGSID=20200512103829-8b918f33-0909-4fe9-b26a-49bc3dffd8c2; '
'PRE_SITE=https%3A%2F%2Fwww.lagou.com; _gat=1; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1589078433,1589251110; _gid=GA1.2.1417960217.1589251110; '
'TG-TRACK-CODE=index_search; X_HTTP_TOKEN=c00891e1743ee6aa1331529851250b8c48dab71e86; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1589251331; '
'LGRID=20200512104211-ba03d0d8-b4c0-4c21-84c9-386970365a83; SEARCH_ID=3322ed24329a44aa825b3e7ea20fa335',
'origin':'https://www.lagou.com',
'pragma': 'no-cache',
'content-length': 25,
'accept':'/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false',
'accept-language':'zh-CN,zh;q=0.9'
}
data = {
'first': 'true',
'pn': 1,
'kd': 'python'
}
req = request.Request(url, headers=headers, data=parse.urlencode(data).encode('utf-8'), method='POST')
resp = request.urlopen(req)
print(resp.read().decode('utf-8'))
print(resp.getcode())
ProxyHandler处理器(代理设置)
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
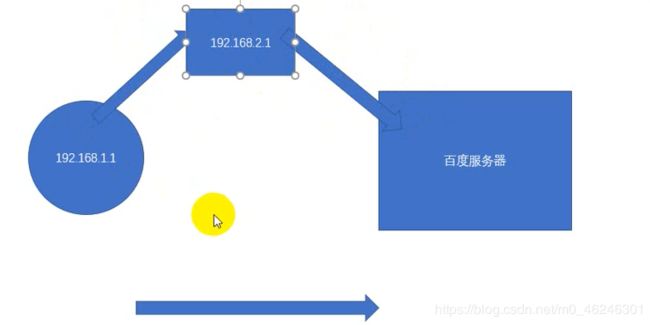
urllib中通过ProxyHandler来设置使用代理服务器,下面代码说明如果使用自定义opener来使用代理:
1、代理的原理:在请求目的网站之前,现请求代理服务器,然后让代理服务器去请求目的网站,代理服务器拿到了目的网站的数据后,再转发给我们的代码。
2、http://httpbin.org:可以方便查看http请求的一些参数
3、在代码中使用代理:
-
使用‘urllib.request.ProxyHandler’
,传入一个代理,这个代理是一个字典,字典的key依赖于代理服务器能够接受的类型,
一般是’http’或者’https’,value是‘IP:PORT’
-
使用上一步创建的’handler’,以及’request.build_opener’,创建一个”opener‘对象
-
使用上一步创建的’opener’,调用’open‘函数,发起请求。
# -*- encoding: utf-8 -*-
from urllib import request
'''没有使用代理时:'''
url = 'http://httpbin.org/ip'
# resp = request.urlopen(url)
# print(resp.read()) # 读取本地IP地址
'''使用代理:'''
# 1.使用ProxyHandler,传入代理构建一个handler
handler = request.ProxyHandler({"http":"163.204.244.14:9999"})
# 2.使用上面创建的handler构建一个opener
opener = request.build_opener(handler)
# 3.使用opener去发送一个请求
resp = opener.open(url)
print(resp.read())b'{\n "origin": "163.204.244.14"\n}\n'
常用的代理:
- 西刺免费代理IP:http://www.xicidaili.com/
- 快代理:http://www.kuaidaili.com/
- 代理云:http://www.dailiyun.com/
什么是cookie?

在网站汇总,http请求时无状态的。即使第一次和服务器连接后并登录成功后,第二次请求服务器依然不能知道当前请求时哪个用户。cookie就是为了解决这个问题,第一次登录后服务器返回一些数据(cookie)给浏览器,然后浏览器保存在本地,当该用户发送第二次请求的时候,就会自动把上次请求存储的cookie数据自动的携带给服务器,服务器通过浏览器携带的数据就能判断当前用户是哪个了。cookie存储的数据量有限,不同的浏览器有不同的存储大小,但一般不超过4KB,因此使用cookie只能存储一些小量的数据。
cookie的格式:
Set-Cookie: NAME=VALULE; Expires/Max-age=DATE; Path=PATH; Domain=DOMAIN_NAME; SECURE
参数:
- NAME:cookie名字
- VALUE:cookie的值
- Expires:cookie的过期时间
- Path:cookie作用的路径
- Domain:cookie作用的域名
- SECURE:是否只在https协议下起作用
以百度为例:

使用cookielib库和HTTPCookieProcessor模拟登陆
Cookie是指网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话。
以人人网为例,要访问某人的主页,必须先登录才能访问,登录就是要有cookie信息,若想用代码的方式访问,就必须要有正确的cookie信息才能访问,解决方案有两种,第一种是使用浏览器访问,然后将cookie信息复制下来,放到headers中:
# -*- encoding: utf-8 -*-
# 大鹏主页:http://www.renren.com/880151247/profile
# 人人网登陆url:http://www.renren.com
from urllib import request
# 1.不使用cookie去请求大鹏的主页->得到登录页面数据
# 2.使用cookie去请求大鹏的主页->得到主页信息
dapeng_url = "http://www.renren.com/880151247/profile"
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,"
" like Gecko) Chrome/81.0.4044.138 Safari/537.36",
'Cookie':"anonymid=kaaswhm1yz2o36; depovince=ZGQT; _r01_=1; taihe_bi_sdk_" \
"uid=d71b694df46eb4d4cf129c911760de42; _de=C70D57FD7CCEDB1F34E575F96A153546; " \
"ln_uact=15814746672; ln_hurl=http://head.xiaonei.com/photos/0/0/men_main.gif; jebe_key" \
"=edeb3bcd-d363-40a9-b2d7-c1937a5520c3%7C97b67773162326428b05c7d4c5fa5625%7C1589704326512%" \
"7C1%7C1589704324726; jebecookies=e2fb446e-5569-4a22-a2a8-ee3e2a0f8e44|||||; ick_login=f7667" \
"40c-88f7-4543-98be-4be66f9976f4; taihe_bi_sdk_session=998b7e96cc3cfac9a7d94a0f79b7ccbf; p=7d9" \
"afdf460a1e122f97dc87288a2c42d7; first_login_flag=1; t=3b5ecbd9d1b26c704eb4a3e1d3d9ce1c7; society" \
"guester=3b5ecbd9d1b26c704eb4a3e1d3d9ce1c7; id=974454297; xnsid=d8386085; loginfrom=syshome; wp_fold=0"
}
req = request.Request(url=dapeng_url, headers=headers)
resp = request.urlopen(req)
# print(resp.read().decode('utf-8'))
'''写到文件中,在网页中打开'''
with open('renren.html','wb') as fp:
# write函数必须写入一个str的数据类型
# resp.read()读出来的是一个byte数据类型,则需解码utf-8
# bytes -> decode -> str
# str -> encode -> bytes
fp.write(resp.read())每次在访问需要cookie的页面都要从浏览器中赋值cookie比较麻烦。在python处理cookie时,一般通过http…cookiejar模块和urllib模块的HTTPCookieProcessor处理器类一起使用。http.cookiejar模块的主要作用是提供用于存储cookie的对象;而HTTPCookieProcessor处理器主要作用是处理这些cookie对象并构建handler对象
http.cookiejar模块:
该模块主要的类有:CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
1、CookieJar:管理HTTP cookie值、存储HTTP请求生成的cookie,向传出的HTTP请求添加cookie对象,整个cookie都存储在内存中,对CookieJar实例进行垃圾回收后cookie也将丢失。
2、FileCookieJar(filename, delayload=None, policy=None):从CookieJar派生而来,用来创建FileCookieJar实例,检索cookie信息并将cookie存储到文件中。filename是存储cookie的文件名。delayload为True时支持延迟访问文件,即只有在需要时才读取文件或在文件中存储数据。
3、MozillaCookieJar(filename, delayload=None, policy=None):从FileCookieJar派生而来,创建与Mozilla浏览器cookies.txt兼容的FileCookieJar实例。
4、LWPCookieJar(filename, delayload=None, policy=None):从FileCookieJar派生而来,创建与libwww-perl标准的Set-Cookie3文件格式兼容的实例。
利用http.cookiejar 和 HTTPCookieProcessor登陆人人网
# -*- encoding: utf-8 -*-
# 大鹏主页:http://www.renren.com/880151247/profile
# 人人网登陆url:http://www.renren.com/PLogin.do
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,"
" like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
from urllib import request
from urllib import parse
from http.cookiejar import CookieJar
'''一、创建opener'''
def get_opener():
# 1、登录
# 1.1 创建一个cookiejar对象
cookiejar = CookieJar()
# 1.2 使用cookiejar创建一个HTTPCookieProcess对象
handler = request.HTTPCookieProcessor(cookiejar)
# 1.3 使用上一步创建的headler创建一个opener
opener = request.build_opener(handler)
return opener
def login(opener):
# 1.4 使用opener发送登录的请求(人人网的邮箱和密码)
data = {
'email':"15814746672",
'password':"123456"
}
login_url = "http://www.renren.com/PLogin.do"
req = request.Request(login_url, data=parse.urlencode(data).encode('utf-8'),
headers=headers)
opener.open(req)
def visit_profile(opener):
# 2、访问个人主页
dapeng_url = "http://www.renren.com/880151247/profile"
# 获取个人主页的页面时,不要新建一个opener
# 而应该使用之前的那个opener,因为已经包含了登录所需要的的cookie信息
req = request.Request(dapeng_url,headers=headers)
resp = opener.open(req)
with open('renren.html','w',encoding='utf-8') as fp:
fp.write(resp.read().decode('utf-8'))
if __name__ == '__main__':
opener = get_opener()
login(opener)
visit_profile(opener)
保存cookie到本地:
可以使用cookiejar和save方法,并且需要指定一个文件名:
# -*- encoding: utf-8 -*-
from urllib import request
from http.cookiejar import MozillaCookieJar
# 创建对象
cookiejar = MozillaCookieJar('cookie.txt')
handler = request.HTTPCookieProcessor(cookiejar)
opener = request.build_opener(handler)
# 将加载进来的cookie打印出来
cookiejar.load(ignore_discard=True)
for cookie in cookiejar:
print(cookie)
# 发送请求
resp = opener.open('http://www.baidu.com/')
# cookiejar.save() # 无法保存即将过期的cookie信息
cookiejar.save(ignore_discard=True) # 能保存即将过期的cookie信息