大数据面试知识点总结Spark Sql、DataFrames、DataSet
1 简述SparkSQL中RDD、DataFrame、DataSet三者的区别与联系? (笔试重点)
1)RDD
优点:
编译时类型安全
编译时就能检查出类型错误
面向对象的编程风格
直接通过类名点的方式来操作数据
缺点:
序列化和反序列化的性能开销
无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。
GC的性能开销,频繁的创建和销毁对象, 势必会增加GC
2)DataFrame
DataFrame引入了schema和off-heap
schema : RDD每一行的数据, 结构都是一样的,这个结构就存储在schema中。 Spark通过schema就能够读懂数据, 因此在通信和IO时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
3)DataSet
DataSet结合了RDD和DataFrame的优点,并带来的一个新的概念Encoder。
当序列化数据时,Encoder产生字节码与off-heap进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。Spark还没有提供自定义Encoder的API,但是未来会加入。
三者之间的转换:
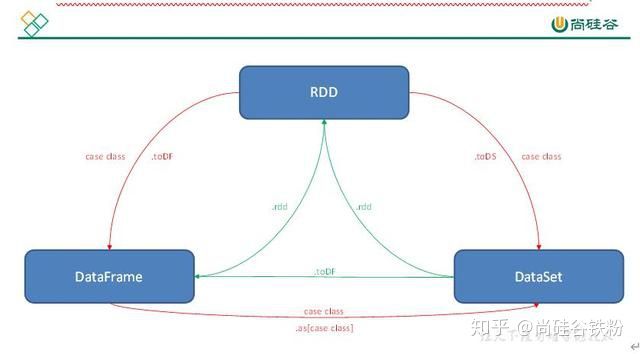
2 append和overwrite的区别
append在原有分区上进行追加,overwrite在原有分区上进行全量刷新
3 coalesce和repartition的区别
coalesce和repartition都用于改变分区,coalesce用于缩小分区且不会进行shuffle,repartition用于增大分区(提供并行度)会进行shuffle,在spark中减少文件个数会使用coalesce来减少分区来到这个目的。但是如果数据量过大,分区数过少会出现OOM所以coalesce缩小分区个数也需合理
4 cache缓存级别
DataFrame的cache默认采用 MEMORY_AND_DISK 这和RDD 的默认方式不一样RDD cache 默认采用MEMORY_ONLY
5 释放缓存和缓存
缓存:(1)dataFrame.cache (2)
sparkSession.catalog.cacheTable(“tableName”)
释放缓存:(1)dataFrame.unpersist (2)
sparkSession.catalog.uncacheTable(“tableName”)
6 Spark Shuffle默认并行度
参数
spark.sql.shuffle.partitions 决定 默认并行度200
7 kryo序列化
kryo序列化比java序列化更快更紧凑,但spark默认的序列化是java序列化并不是spark序列化,因为spark并不支持所有序列化类型,而且每次使用都必须进行注册。注册只针对于RDD。在DataFrames和DataSet当中自动实现了kryo序列化。
8 创建临时表和全局临时表
DataFrame.createTempView() 创建普通临时表
DataFrame.createGlobalTempView()
DataFrame.createOrReplaceTempView() 创建全局临时表
9 BroadCast join 广播join
原理:先将小表数据查询出来聚合到driver端,再广播到各个executor端,使表与表join时
进行本地join,避免进行网络传输产生shuffle。
使用场景:大表join小表 只能广播小表
10 控制Spark reduce缓存 调优shuffle
spark.reducer.maxSizeInFilght 此参数为reduce task能够拉取多少数据量的一个参数默认48MB,当集群资源足够时,增大此参数可减少reduce拉取数据量的次数,从而达到优化shuffle的效果,一般调大为96MB,资源够大可继续往上跳。
spark.shuffle.file.buffer 此参数为每个shuffle文件输出流的内存缓冲区大小,调大此参数可以减少在创建shuffle文件时进行磁盘搜索和系统调用的次数,默认参数为32k 一般调大为64k。
11 注册UDF函数
SparkSession.udf.register 方法进行注册
12 SparkSQL中join操作与left join操作的区别?
join和sql中的inner join操作很相似,返回结果是前面一个集合和后面一个集合中匹配成功的,过滤掉关联不上的。
leftJoin类似于SQL中的左外关联left outer join,返回结果以第一个RDD为主,关联不上的记录为空。
部分场景下可以使用left semi join替代left join:
因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,性能更高,而 left join 则会一直遍历。但是left semi join 中最后 select 的结果中只许出现左表中的列名,因为右表只有 join key 参与关联计算了
大数据培训