Python:聚合函数(groupby)
一堆废话
不知不觉都12月12日了。
如果再不写CSDN,我的持之以恒勋章就要消失了!
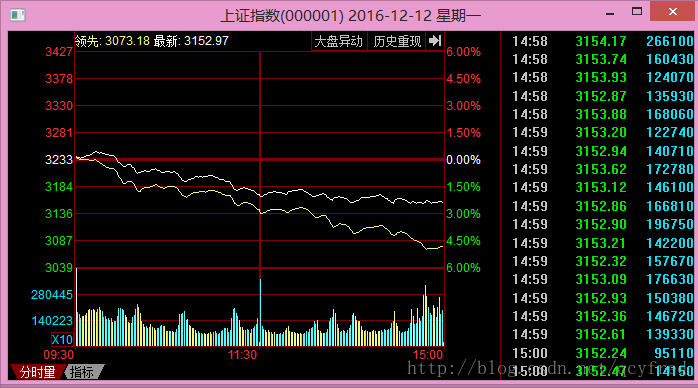
记得去年的双十二,是真的大打折了!上证一天跌了2.47%,近400只股票跌停。
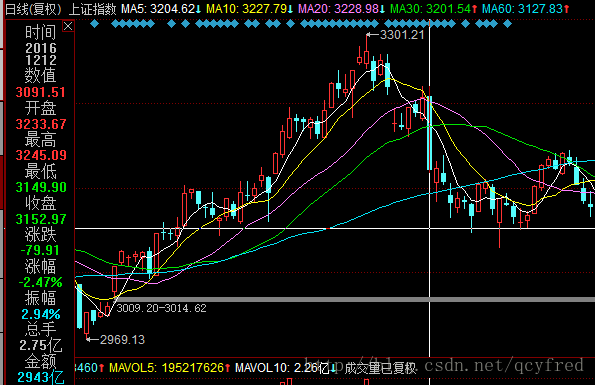
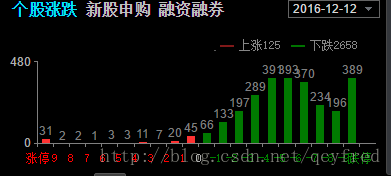
我还清晰地记得,那天是一路下跌。中午收盘已经跌了接近1.7%了。
在食堂吃饭的时候,除了恐慌,脑子一片空白…(毕竟我在潘老板的带领下,也到市场里走了一圈的。而且那个时候啥都不懂)
今天也是双十二,又来打折。不过我看着你们跌就好了。
我也不去像某些人一样,整天吼着买哪只哪只股票,或者全仓抄底啥的,尽管我已经通过了发布证券研究报告业务资格的考试。
反正一涨一跌,一半的时间能猜中。而且这种空头排列,你就猜跌,多头排列,你就跟风喊涨。更有可能命中。
股市这东西,整天盯着布朗运动看几个小时,累不累?
买入配置型仓位,然后做实业去,挺好的…
国家队都说了,我们股市波动如此之大,就是因为有太多的趋势交易者,太多的追涨杀跌!
正题
一天的交易结束后,根据交易流水,要生成持仓汇总。
所以推荐使用py的聚合函数,groupby。
案例代码演示是这样的。
import pandas as pddf = pd.read_excel('trade.xlsx')df| 证券代码 | 证券名称 | 买卖方向 | 数量 | |
|---|---|---|---|---|
| 0 | 601318 | 中国平安 | 买入 | 100 |
| 1 | 601398 | 工商银行 | 买入 | 100 |
| 2 | 600050 | 中国联通 | 买入 | 100 |
| 3 | 601318 | 中国平安 | 卖出 | 100 |
| 4 | 601318 | 中国平安 | 买入 | 200 |
| 5 | 600050 | 中国联通 | 买入 | 100 |
| 6 | 600050 | 工商银行 | 卖出 | 100 |
df_grp = df.groupby(['证券代码', '买卖方向']).sum()df_grp| 数量 | ||
|---|---|---|
| 证券代码 | 买卖方向 | |
| 600050 | 买入 | 200 |
| 卖出 | 100 | |
| 601318 | 买入 | 300 |
| 卖出 | 100 | |
| 601398 | 买入 | 100 |
tmp_df = df.copy()
tmp_df.index = [df['证券代码'], df['买卖方向']]
tmp_df| 证券代码 | 证券名称 | 买卖方向 | 数量 | ||
|---|---|---|---|---|---|
| 证券代码 | 买卖方向 | ||||
| 601318 | 买入 | 601318 | 中国平安 | 买入 | 100 |
| 601398 | 买入 | 601398 | 工商银行 | 买入 | 100 |
| 600050 | 买入 | 600050 | 中国联通 | 买入 | 100 |
| 601318 | 卖出 | 601318 | 中国平安 | 卖出 | 100 |
| 买入 | 601318 | 中国平安 | 买入 | 200 | |
| 600050 | 买入 | 600050 | 中国联通 | 买入 | 100 |
| 卖出 | 600050 | 工商银行 | 卖出 | 100 |
tmp_df.drop_duplicates(['证券代码','买卖方向'], inplace=True)
tmp_df| 证券代码 | 证券名称 | 买卖方向 | 数量 | ||
|---|---|---|---|---|---|
| 证券代码 | 买卖方向 | ||||
| 601318 | 买入 | 601318 | 中国平安 | 买入 | 100 |
| 601398 | 买入 | 601398 | 工商银行 | 买入 | 100 |
| 600050 | 买入 | 600050 | 中国联通 | 买入 | 100 |
| 601318 | 卖出 | 601318 | 中国平安 | 卖出 | 100 |
| 600050 | 卖出 | 600050 | 工商银行 | 卖出 | 100 |
other_cols = list(set(tmp_df.columns) - set(df_grp.columns))
df_sum = pd.concat([df_grp, tmp_df.loc[:, other_cols]], axis=1)df_sum| 数量 | 证券名称 | 证券代码 | 买卖方向 | ||
|---|---|---|---|---|---|
| 证券代码 | 买卖方向 | ||||
| 600050 | 买入 | 200 | 中国联通 | 600050 | 买入 |
| 卖出 | 100 | 工商银行 | 600050 | 卖出 | |
| 601318 | 买入 | 300 | 中国平安 | 601318 | 买入 |
| 卖出 | 100 | 中国平安 | 601318 | 卖出 | |
| 601398 | 买入 | 100 | 工商银行 | 601398 | 买入 |
上面的案例,py代码在附在下面。
# coding: utf-8
import pandas as pd
df = pd.read_excel('trade.xlsx')
df_grp = df.groupby(['证券代码', '买卖方向']).sum()
tmp_df = df.copy()
tmp_df.index = [df['证券代码'], df['买卖方向']]
tmp_df.drop_duplicates(['证券代码','买卖方向'], inplace=True)
other_cols = list(set(tmp_df.columns) - set(df_grp.columns))
df_sum = pd.concat([df_grp, tmp_df.loc[:, other_cols]], axis=1)