使用sparkSQL进行数据分析并使用echart画图
使用sparkSQL进行数据分析并使用echart画图
刚学了一些大数据的基础知识,老师留了一个小实验,用sparkSql或mapreduce分析数据,然后在进行数据可视化。因为sparkSql可以使用sql语句查询,所以采取的sparksql进行数据分析。
下面就记录一些操作
实验要求:
老师给的5000条数据,格式是这样的
- 分析发布公司最多的Top 10 公司名称及发布职位数量【饼状图展示】
- 分析招聘职位最多的Top5 职位名称及数量【柱状图展示】
- 分析工资最高的职位Top3 职位名称及工资【折线图展示】
前提条件:
在idea中配置好hadoop、scala和spark环境
配置好环境之后就可以开始写代码了
一、用sparkSQL分析数据
1、新建一个scala object
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataTypes, StructField}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SQLContext, SparkSession}
import scala.collection.mutable.ArrayBuffer
import scala.xml.Text
object DataAnalysis {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("dataFrameTest")
.set("spark.port.maxRetries","1000");
val sc = new SparkContext(conf)
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val data = spark.read
.format("com.databricks.spark.csv")
.option("inferSchema", "true")
.option("header", "true") //reading the headers
.option("mode", "DROPMALFORMED")
.option("nullValue", "?")
.csv("c:\\51Job_python_5000.txt");
data.show()
val dataDF = data.toDF("work","company","add","salary","date")
val dataDF2 = dataDF.filter("work != '' and company != '' and add != '' and salary != '' and date != ''")
//dataDF.show()
//dataDF2.show()
val message = dataDF2.createOrReplaceTempView("message")
//第一题答案
val resdata = spark.sql("select count(*) num,company FROM message group by company").registerTempTable("q1temp")
val resdata2 = spark.sql("select num,company from (select num,company,row_number() OVER(ORDER BY num DESC) rank from q1temp) tmp where rank <= 10")
resdata2.show()
//第二题答案
val resdata3 = spark.sql("select count(*) num,work FROM message group by work")
resdata3.show()
resdata3.registerTempTable("q2temp")
val resdata4 = spark.sql("select num,work from (select num,work,row_number() OVER(ORDER BY num DESC) rank from q2temp) tmp where rank <= 5")
resdata4.show()
//第三题答案
val resdata5 = spark.sql(""" select work,company,salary,
(CASE
WHEN salary like '%千/月%' then translate(split(salary,'[-/]')[1],'千','')*1000
when salary like '%万/月%' then translate(split(salary,'[-/]')[1],'万','')*10000
when salary like '%万/年%' then round(translate(split(salary,'[-/]')[1],'万','')*10000/12)
else 0 end) new_salary from message """).registerTempTable("q3temp")
val resdata6 = spark.sql("select work,company,salary,new_salary from (select work,company,salary,new_salary,row_number() OVER(ORDER BY new_salary DESC) rank from q3temp ) tmp where rank <= 3")
resdata6.show()
resdata2.write.json("C://result/res1")
resdata4.write.json("C://result/res2")
resdata6.write.json("C://result/res3")
}
}
总结一些点:
(1)读取csv文件中文乱码
解决办法:我是直接把csv文件的内容复制出来放到一个txt里面保存成utf-8格式,之后直接读取.txt。因为csv就是用逗号分隔的格式虽然后缀是txt但保留了csv格式的内容,所以可以使用.csv()方法读取
(2)第一题把resdata和resdata2写成一条语句错误,原因不太清楚
解决办法:我把它分成两条语句用registerTempTable生成了一个临时表就好使了
(3)row_number() OVER(ORDER BY num DESC)内置函数
语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
over()里头可以分组以及排序,因为我需要按照num小到大所以没写分组
(4)write.json()输出的json文件
2、运行这个scala object
执行之后会生成json文件
二、用echart画图
1、把输出的json文件导入到Java web工程的web下边
2、修改一下json文件的格式
用spark输出的json文件格式不太对,在后面读取会有问题,所以修改一下,输出的三个文件都修改
修改前:

修改后:

3、新建jsp用echart画图
直接贴代码
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
Title
4、效果图

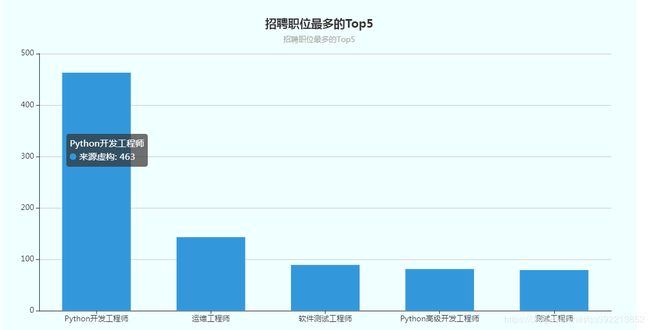
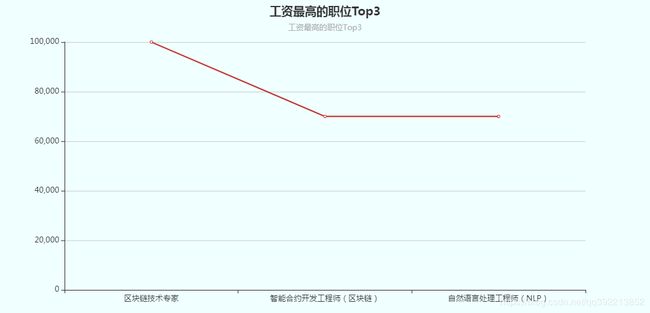
总结几点:
1、填入数据时注意,echart的饼状图需要的数据形式是
name:xxx value:xxx
填入数据用这样的方式
q1Data.push({
name: v.company,
value: v.num
});
2、定义div的时候给一个长宽大小,echart渲染才能显示出来