Java中的锁机制 synchronized & 偏向锁 & 轻量级锁 & 重量级锁 & 各自优缺点及场景 & AtomicReference 侵立删
转自:https://www.cnblogs.com/charlesblc/p/5994162.html
参考文章: http://blog.csdn.net/chen77716/article/details/6618779
目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug Lea。本文并不比较synchronized与Lock孰优孰劣,只是介绍二者的实现原理。
数据同步需要依赖锁,那锁的同步又依赖谁?synchronized给出的答案是在软件层面依赖JVM,而Lock给出的方案是在硬件层面依赖特殊的CPU指令。
synrhronized使用广泛。其应用层的语义是可以把任何一个非null对象作为"锁", 当synchronized作用在方法上时,锁住的便是对象实例(this); 当作用在静态方法时锁住的便是对象对应的Class实例,因为Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁; 当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。 在HotSpot JVM实现中,锁有个专门的名字:对象监视器。
线程状态及状态转换

当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程: Contention List:所有请求锁的线程将被首先放置到该竞争队列 Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck Owner:获得锁的线程称为Owner !Owner:释放锁的线程
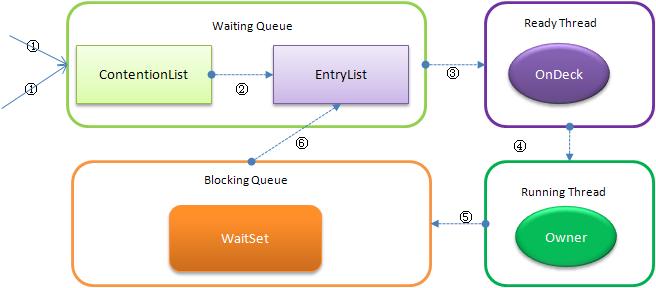
上图和文章中提到了ContentionList,又提到了EntryList。
自旋锁
还提到了自旋锁(Spin Lock),在一个线程获取锁的时候,先进行自旋,尝试。虽然对ContentionList中的线程不尽公平,但是效率可以大大提升。
那些处于ContetionList、EntryList、WaitSet中的线程均处于阻塞状态,阻塞操作由操作系统完成(在Linxu下通过pthread_mutex_lock函数)。 线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能 缓解上述问题的办法便是自旋,其原理是: 当发生争用时,若Owner线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋),在Owner线程释放锁后,争用线程可能会立即得到锁, 从而避免了系统阻塞。 但Owner运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。 基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。 自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。
自旋锁详细介绍:
还有个问题是,线程自旋时做些啥?其实啥都不做,可以执行几次for循环,可以执行几条空的汇编指令,目的是占着CPU不放,等待获取锁的机会。 所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。 显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择, 如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。 对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。 经过调查,目前只是通过汇编暂停了几个CPU周期,除了自旋周期选择,HotSpot还进行许多其他的自旋优化策略, 具体如下: 如果平均负载小于CPUs则一直自旋 如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞 如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞 如果CPU处于节电模式则停止自旋 自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差) 自旋时会适当放弃线程优先级之间的差异 那synchronized实现何时使用了自旋锁? 答案是在线程进入ContentionList时,也即第一步操作前。 线程在进入等待队列时首先进行自旋尝试获得锁,如果不成功再进入等待队列。这对那些已经在等待队列中的线程来说,稍微显得不公平。 还有一个不公平的地方是自旋线程可能会抢占了Ready线程的锁。自旋锁由每个监视对象维护,每个监视对象一个。
偏向锁
偏向锁(Biased Lock)主要解决无竞争下的锁性能问题.
首先我们看下无竞争下锁存在什么问题: 现在几乎所有的锁都是可重入的,也即已经获得锁的线程可以多次锁住/解锁监视对象, 按照之前的HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作(比如对等待队列的CAS操作),CAS操作会延迟本地调用, 因此偏向锁的想法是一旦线程第一次获得了监视对象,之后让监视对象“偏向”这个线程,之后的多次调用则可以避免CAS操作, 说白了就是置个变量,如果发现为true则无需再走各种加锁/解锁流程。
以上内容来自 http://blog.csdn.net/chen77716/article/details/6618779 但是没怎么读懂
在搜索偏向锁的过程中,又找到下面这篇
http://blog.163.com/silver9886@126/blog/static/35971862201472274958280/
Java偏向锁(Biased Locking)是Java6引入的一项多线程优化。它通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。 偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在接下来的运行过程中,该锁没有被其他的线程访问,则持有偏向锁的线程将永远不需要触发同步。 如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会尝试消除它身上的偏向锁,将锁恢复到标准的轻量级锁。 (偏向锁只能在单线程下起作用) 因此 流程是这样的 偏向锁->轻量级锁->重量级锁
其中还提到轻量级锁和重量级锁。那么这还涉及锁膨胀。
通过知乎上的一篇回答 https://www.zhihu.com/question/39009953?sort=created
轻量级锁就是为了在无多线程竞争的环境中使用CAS来代替mutex,一旦发生竞争,两条以上线程争用一个锁就会膨胀。
回到前一篇
锁存在Java对象头里。如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。 在32位虚拟机中,一字宽等于四字节,即32bit。 锁状态包括:轻量级锁定、重量级锁定、GC标记、可偏向
- 这篇文章 http://blog.csdn.net/wolegequdidiao/article/details/45116141
- 对象自身的运行时数据
如:哈希吗(HashCode)、GC分代年龄(Generational GC Age)等,这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,简称“Mark Word”
- 对象自身的运行时数据
下面两张图可以先忽略,因为后面有更清楚的
(忽略图,看后面的)32位JVM的Mark Word的默认存储结构如下: 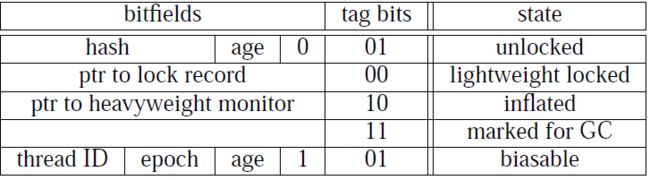
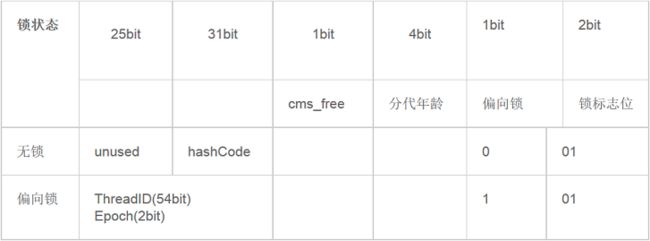
(忽略图,看后面的)64位JVM下, Mark Word是64bit大小的,存储结构如下:
简单的加锁机制:
机制:每个锁都关联一个请求计数器和一个占有他的线程,当请求计数器为0时,这个锁可以被认为是unhled的, 当一个线程请求一个unheld的锁时,JVM记录锁的拥有者,并把锁的请求计数加1,如果同一个线程再次请求这个锁时,请求计数器就会增加, 当该线程退出syncronized块时,计数器减1,当计数器为0时,锁被释放(这就保证了锁是可重入的,不会发生死锁的情况)。
偏向锁流程:
偏向锁,简单的讲,就是在锁对象的对象头中有个ThreaddId字段,这个字段如果是空的, 第一次获取锁的时候,就将自身的ThreadId写入到锁的ThreadId字段内,将锁头内的是否偏向锁的状态位置1. 这样下次获取锁的时候,直接检查ThreadId是否和自身线程Id一致,如果一致,则认为当前线程已经获取了锁,因此不需再次获取锁, 略过了轻量级锁和重量级锁的加锁阶段。提高了效率。 但是偏向锁也有一个问题,就是当锁有竞争关系的时候,需要解除偏向锁,使锁进入竞争的状态。
下面是清晰的流程:
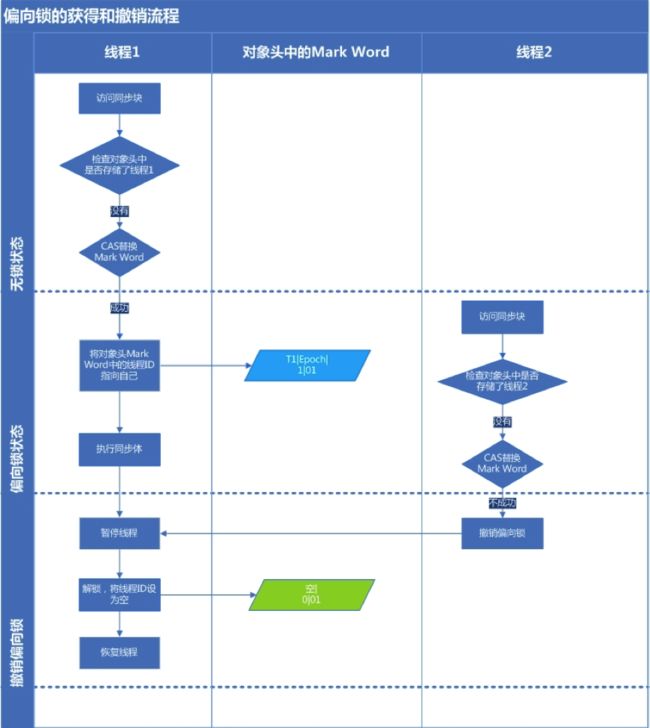
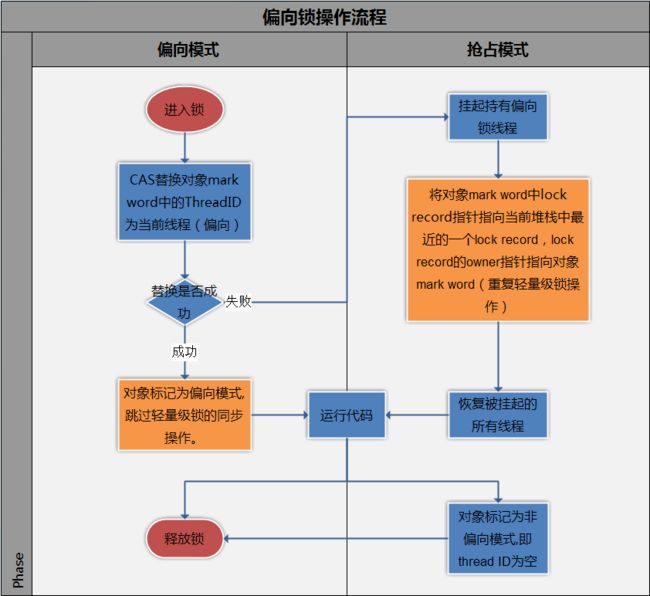
上图中只讲了偏向锁的释放,其实还涉及偏向锁的抢占,其实就是两个进程对锁的抢占,在synchrnized锁下表现为轻量锁方式进行抢占。
注:也就是说一旦偏向锁冲突,双方都会升级为轻量级锁。(这一点与轻量级->重量级锁不同,那时候失败一方直接升级,成功一方在释放时候notify,加下文后面详细描述)
如下图。之后会进入到轻量级锁阶段,两个线程进入锁竞争状态(注,我理解仍然会遵守先来后到原则;注2,的确是的,下图中提到了mark word中的lock record指向堆栈中最近的一个线程的lock record),一个具体例子可以参考synchronized锁机制。(图后面有介绍)
上面163的文章中,提到了这一篇 http://xly1981.iteye.com/blog/1766224,里面对于synchronized的过程讲的挺好:
每一个线程在准备获取共享资源时: 第一步,检查MarkWord里面是不是放的自己的ThreadId ,如果是,表示当前线程是处于 “偏向锁” 第二步,如果MarkWord不是自己的ThreadId,锁升级,这时候,用CAS来执行切换,新的线程根据MarkWord里面现有的ThreadId,通知之前线程暂停, 之前线程将Markword的内容置为空。 第三步,两个线程都把对象的HashCode复制到自己新建的用于存储锁的记录空间,接着开始通过CAS操作, 把共享对象的MarKword的内容修改为自己新建的记录空间的地址的方式竞争MarkWord, 第四步,第三步中成功执行CAS的获得资源,失败的则进入自旋 第五步,自旋的线程在自旋过程中,成功获得资源(即之前获的资源的线程执行完成并释放了共享资源),则整个状态依然处于 轻量级锁的状态,如果自旋失败 第六步,进入重量级锁的状态,这个时候,自旋的线程进行阻塞,等待之前线程执行完成并唤醒自己
总结:
偏向锁,其实是无锁竞争下可重入锁的简单实现。流程是这样的 偏向锁->轻量级锁->重量级锁
发现,这篇文章对于synchronized讲得比较清楚 http://www.infoq.com/cn/articles/java-se-16-synchronized
先介绍一下CAS:
Compare and Swap 比较并设置。用于在硬件层面上提供原子性操作。在 Intel 处理器中,比较并交换通过指令cmpxchg实现。 比较是否和给定的数值一致,如果一致则修改,不一致则不修改。
同步的基础
Java中的每一个对象都可以作为锁。
- 对于同步方法,锁是当前实例对象。
- 对于静态同步方法,锁是当前对象的Class对象。
- 对于同步方法块,锁是Synchonized括号里配置的对象。
当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。那么锁存在哪里呢?锁里面会存储什么信息呢?
同步的原理
JVM规范规定JVM基于进入和退出Monitor对象来实现方法同步和代码块同步,但两者的实现细节不一样。
代码块同步是使用monitorenter和monitorexit指令实现,而方法同步是使用另外一种方式实现的,细节在JVM规范里并没有详细说明,但是方法的同步同样可以使用这两个指令来实现。
monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处, JVM要保证每个monitorenter必须有对应的monitorexit与之配对。
任何对象都有一个 monitor 与之关联,当且一个monitor 被持有后,它将处于锁定状态。线程执行到 monitorenter 指令时,将会尝试获取对象所对应的 monitor 的所有权,即尝试获得对象的锁。
Java对象头
锁存在Java对象头里。如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。在32位虚拟机中,一字宽等于四字节,即32bit。(下面这个表格讲的很清楚)
| 参考文章: http://blog.csdn.net/chen77716/article/details/6618779 目前在Java中存在两种锁机制:synchronized和Lock,Lock接口及其实现类是JDK5增加的内容,其作者是大名鼎鼎的并发专家Doug Lea。本文并不比较synchronized与Lock孰优孰劣,只是介绍二者的实现原理。 数据同步需要依赖锁,那锁的同步又依赖谁?synchronized给出的答案是在软件层面依赖JVM,而Lock给出的方案是在硬件层面依赖特殊的CPU指令。 synrhronized使用广泛。其应用层的语义是可以把任何一个非null对象作为"锁", 当synchronized作用在方法上时,锁住的便是对象实例(this); 当作用在静态方法时锁住的便是对象对应的Class实例,因为Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁; 当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。 在HotSpot JVM实现中,锁有个专门的名字:对象监视器。 线程状态及状态转换
当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程: Contention List:所有请求锁的线程将被首先放置到该竞争队列 Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck Owner:获得锁的线程称为Owner !Owner:释放锁的线程
上图和文章中提到了ContentionList,又提到了EntryList。 自旋锁还提到了自旋锁(Spin Lock),在一个线程获取锁的时候,先进行自旋,尝试。虽然对ContentionList中的线程不尽公平,但是效率可以大大提升。
那些处于ContetionList、EntryList、WaitSet中的线程均处于阻塞状态,阻塞操作由操作系统完成(在Linxu下通过pthread_mutex_lock函数)。 线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能 缓解上述问题的办法便是自旋,其原理是: 当发生争用时,若Owner线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋),在Owner线程释放锁后,争用线程可能会立即得到锁, 从而避免了系统阻塞。 但Owner运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。 基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。 自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。
自旋锁详细介绍:
还有个问题是,线程自旋时做些啥?其实啥都不做,可以执行几次for循环,可以执行几条空的汇编指令,目的是占着CPU不放,等待获取锁的机会。 所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。 显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择, 如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。 对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。 经过调查,目前只是通过汇编暂停了几个CPU周期,除了自旋周期选择,HotSpot还进行许多其他的自旋优化策略, 具体如下: 如果平均负载小于CPUs则一直自旋 如果有超过(CPUs/2)个线程正在自旋,则后来线程直接阻塞 如果正在自旋的线程发现Owner发生了变化则延迟自旋时间(自旋计数)或进入阻塞 如果CPU处于节电模式则停止自旋 自旋时间的最坏情况是CPU的存储延迟(CPU A存储了一个数据,到CPU B得知这个数据直接的时间差) 自旋时会适当放弃线程优先级之间的差异 那synchronized实现何时使用了自旋锁? 答案是在线程进入ContentionList时,也即第一步操作前。 线程在进入等待队列时首先进行自旋尝试获得锁,如果不成功再进入等待队列。这对那些已经在等待队列中的线程来说,稍微显得不公平。 还有一个不公平的地方是自旋线程可能会抢占了Ready线程的锁。自旋锁由每个监视对象维护,每个监视对象一个。
偏向锁偏向锁(Biased Lock)主要解决无竞争下的锁性能问题. 首先我们看下无竞争下锁存在什么问题: 现在几乎所有的锁都是可重入的,也即已经获得锁的线程可以多次锁住/解锁监视对象, 按照之前的HotSpot设计,每次加锁/解锁都会涉及到一些CAS操作(比如对等待队列的CAS操作),CAS操作会延迟本地调用, 因此偏向锁的想法是一旦线程第一次获得了监视对象,之后让监视对象“偏向”这个线程,之后的多次调用则可以避免CAS操作, 说白了就是置个变量,如果发现为true则无需再走各种加锁/解锁流程。 以上内容来自 http://blog.csdn.net/chen77716/article/details/6618779 但是没怎么读懂 在搜索偏向锁的过程中,又找到下面这篇 http://blog.163.com/silver9886@126/blog/static/35971862201472274958280/ Java偏向锁(Biased Locking)是Java6引入的一项多线程优化。它通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。 偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在接下来的运行过程中,该锁没有被其他的线程访问,则持有偏向锁的线程将永远不需要触发同步。 如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会尝试消除它身上的偏向锁,将锁恢复到标准的轻量级锁。 (偏向锁只能在单线程下起作用) 因此 流程是这样的 偏向锁->轻量级锁->重量级锁 其中还提到轻量级锁和重量级锁。那么这还涉及锁膨胀。 通过知乎上的一篇回答 https://www.zhihu.com/question/39009953?sort=created 轻量级锁就是为了在无多线程竞争的环境中使用CAS来代替mutex,一旦发生竞争,两条以上线程争用一个锁就会膨胀。 回到前一篇 锁存在Java对象头里。如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。 在32位虚拟机中,一字宽等于四字节,即32bit。 锁状态包括:轻量级锁定、重量级锁定、GC标记、可偏向
下面两张图可以先忽略,因为后面有更清楚的 (忽略图,看后面的)32位JVM的Mark Word的默认存储结构如下: (忽略图,看后面的)64位JVM下, Mark Word是64bit大小的,存储结构如下:
简单的加锁机制: 机制:每个锁都关联一个请求计数器和一个占有他的线程,当请求计数器为0时,这个锁可以被认为是unhled的, 当一个线程请求一个unheld的锁时,JVM记录锁的拥有者,并把锁的请求计数加1,如果同一个线程再次请求这个锁时,请求计数器就会增加, 当该线程退出syncronized块时,计数器减1,当计数器为0时,锁被释放(这就保证了锁是可重入的,不会发生死锁的情况)。 偏向锁流程: 偏向锁,简单的讲,就是在锁对象的对象头中有个ThreaddId字段,这个字段如果是空的, 第一次获取锁的时候,就将自身的ThreadId写入到锁的ThreadId字段内,将锁头内的是否偏向锁的状态位置1. 这样下次获取锁的时候,直接检查ThreadId是否和自身线程Id一致,如果一致,则认为当前线程已经获取了锁,因此不需再次获取锁, 略过了轻量级锁和重量级锁的加锁阶段。提高了效率。 但是偏向锁也有一个问题,就是当锁有竞争关系的时候,需要解除偏向锁,使锁进入竞争的状态。 下面是清晰的流程:
上图中只讲了偏向锁的释放,其实还涉及偏向锁的抢占,其实就是两个进程对锁的抢占,在synchrnized锁下表现为轻量锁方式进行抢占。 注:也就是说一旦偏向锁冲突,双方都会升级为轻量级锁。(这一点与轻量级->重量级锁不同,那时候失败一方直接升级,成功一方在释放时候notify,加下文后面详细描述) 如下图。之后会进入到轻量级锁阶段,两个线程进入锁竞争状态(注,我理解仍然会遵守先来后到原则;注2,的确是的,下图中提到了mark word中的lock record指向堆栈中最近的一个线程的lock record),一个具体例子可以参考synchronized锁机制。(图后面有介绍)
上面163的文章中,提到了这一篇 http://xly1981.iteye.com/blog/1766224,里面对于synchronized的过程讲的挺好:
每一个线程在准备获取共享资源时: 第一步,检查MarkWord里面是不是放的自己的ThreadId ,如果是,表示当前线程是处于 “偏向锁” 第二步,如果MarkWord不是自己的ThreadId,锁升级,这时候,用CAS来执行切换,新的线程根据MarkWord里面现有的ThreadId,通知之前线程暂停, 之前线程将Markword的内容置为空。 第三步,两个线程都把对象的HashCode复制到自己新建的用于存储锁的记录空间,接着开始通过CAS操作, 把共享对象的MarKword的内容修改为自己新建的记录空间的地址的方式竞争MarkWord, 第四步,第三步中成功执行CAS的获得资源,失败的则进入自旋 第五步,自旋的线程在自旋过程中,成功获得资源(即之前获的资源的线程执行完成并释放了共享资源),则整个状态依然处于 轻量级锁的状态,如果自旋失败 第六步,进入重量级锁的状态,这个时候,自旋的线程进行阻塞,等待之前线程执行完成并唤醒自己
总结: 偏向锁,其实是无锁竞争下可重入锁的简单实现。流程是这样的 偏向锁->轻量级锁->重量级锁
发现,这篇文章对于synchronized讲得比较清楚 http://www.infoq.com/cn/articles/java-se-16-synchronized 先介绍一下CAS: Compare and Swap 比较并设置。用于在硬件层面上提供原子性操作。在 Intel 处理器中,比较并交换通过指令cmpxchg实现。 比较是否和给定的数值一致,如果一致则修改,不一致则不修改。 同步的基础Java中的每一个对象都可以作为锁。
当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。那么锁存在哪里呢?锁里面会存储什么信息呢? 同步的原理JVM规范规定JVM基于进入和退出Monitor对象来实现方法同步和代码块同步,但两者的实现细节不一样。 代码块同步是使用monitorenter和monitorexit指令实现,而方法同步是使用另外一种方式实现的,细节在JVM规范里并没有详细说明,但是方法的同步同样可以使用这两个指令来实现。 monitorenter指令是在编译后插入到同步代码块的开始位置,而monitorexit是插入到方法结束处和异常处, JVM要保证每个monitorenter必须有对应的monitorexit与之配对。 任何对象都有一个 monitor 与之关联,当且一个monitor 被持有后,它将处于锁定状态。线程执行到 monitorenter 指令时,将会尝试获取对象所对应的 monitor 的所有权,即尝试获得对象的锁。 Java对象头锁存在Java对象头里。如果对象是数组类型,则虚拟机用3个Word(字宽)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。在32位虚拟机中,一字宽等于四字节,即32bit。(下面这个表格讲的很清楚)
Java对象头里的Mark Word里默认存储对象的HashCode,分代年龄和锁标记位。32位JVM的Mark Word的默认存储结构如下:
在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。Mark Word可能变化为存储以下4种数据:
上图里面的GC标记,为11的话,推断应该是准备GC的意思。 在64位虚拟机下,Mark Word是64bit大小的,其存储结构如下:
锁的升级Java SE1.6为了减少获得锁和释放锁所带来的性能消耗,引入了“偏向锁”和“轻量级锁”, 所以在Java SE1.6里锁一共有四种状态,无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,它会随着竞争情况逐渐升级。 锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。 这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率,下文会详细分析。
偏向锁
Hotspot的作者经过以往的研究发现大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。 当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID, 以后该线程在进入和退出同步块时不需要花费CAS操作来加锁和解锁,而只需简单的测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁, 如果测试成功,表示线程已经获得了锁,如果测试失败,则需要再测试下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁),如果没有设置, 则使用CAS竞争锁,如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。 偏向锁的撤销:偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。 偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行), 它会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否活着, 如果线程不处于活动状态,则将对象头设置成无锁状态, 如果线程仍然活着,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录, 栈中的锁记录和对象头的Mark Word要么重新偏向于其他线程,要么恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。 上面的意思是,先暂停持有偏向锁的线程,尝试直接切换。如果不成功,就继续运行,并且标记对象不适合偏向锁,锁膨胀(锁升级)。 详见,上面有张图中的“偏向锁抢占模式”: 其中提到了mark word中的lock record指向堆栈最近的一个线程的lock record,其实就是按照先来后到模式进行了轻量级的加锁。
上文提到全局安全点:在这个时间点上没有字节码正在执行。 关闭偏向锁:偏向锁在Java 6和Java 7里是默认启用的,但是它在应用程序启动几秒钟之后才激活, 如有必要可以使用JVM参数来关闭延迟-XX:BiasedLockingStartupDelay = 0。 如果你确定自己应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁-XX:-UseBiasedLocking=false,那么默认会进入轻量级锁状态。 轻量级锁轻量级锁加锁:线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。 然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。 轻量级锁解锁:轻量级解锁时,会使用原子的CAS操作来将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。 如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。 注:轻量级锁会一直保持,唤醒总是发生在轻量级锁解锁的时候,因为加锁的时候已经成功CAS操作;而CAS失败的线程,会立即锁膨胀,并阻塞等待唤醒。(详见下图) 下图是两个线程同时争夺锁,导致锁膨胀的流程图。
锁不会降级 因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。 当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。 锁的优缺点对比
上面这张表格好好看,总结的非常好! 6 参考源码对象头源码markOop.hpp。偏向锁源码biasedLocking.cpp。以及其他源码ObjectMonitor.cpp和BasicLock.cpp。
上面这篇文章(http://www.infoq.com/cn/articles/java-se-16-synchronized)讲得非常清晰了。下面还有几篇文章之前打开了,看是否有补充。
http://blog.csdn.net/wolegequdidiao/article/details/45116141 这篇文章提到: 轻量级锁加锁进行的CAS操作中,是先更新Lock Record指针,然后再更新最后2bit的锁标记位(也不一定,没有明确说。但是各种锁的顺序要一致;注:涉及偏向锁,很可能是先改锁标记位的)。 下面这张图,和上面那张图是一致的:
总结轻量级锁能提高程序同步性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销,但如果存在锁竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。 偏向锁JDK1.6引入
注意:偏向锁的锁标记位和无锁是一样的,都是01,但是有单独一位偏向标记设置是否偏向锁。 再复习一下,轻量级锁00,重量级锁10,GC标记11,无锁 01. 下面这张图做一个复习:
总结偏向锁可以提高带有同步但无竞争的程序性能。如果程序中大多数的锁总是被多个不同的线程访问,那偏向模式就是多余的。 在具体情形分析下,禁止偏向锁优反而可能提升性能。
看这篇文章的一些笔记 http://www.cnblogs.com/javaminer/p/3889023.html
在jdk1.6中对锁的实现引入了大量的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、 偏向锁(Biased Locking)、适应性自旋(Adaptive Spinning)等技术来减少锁操作的开销。 锁粗化(Lock Coarsening):也就是减少不必要的紧连在一起的unlock,lock操作,将多个连续的锁扩展成一个范围更大的锁。 锁消除(Lock Elimination):通过运行时JIT编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护, 通过逃逸分析也可以在线程本地Stack上进行对象空间的分配(同时还可以减少Heap上的垃圾收集开销)。 轻量级锁(Lightweight Locking):这种锁实现的背后基于这样一种假设,即在真实的情况下我们程序中的大部分同步代码一般都处于无锁竞争状态 (即单线程执行环境),在无锁竞争的情况下完全可以避免调用操作系统层面的重量级互斥锁, 取而代之的是在monitorenter和monitorexit中只需要依靠一条CAS原子指令就可以完成锁的获取及释放。 当存在锁竞争的情况下,执行CAS指令失败的线程将调用操作系统互斥锁进入到阻塞状态,当锁被释放的时候被唤醒(具体处理步骤下面详细讨论)。 偏向锁(Biased Locking):是为了在无锁竞争的情况下避免在锁获取过程中执行不必要的CAS原子指令, 因为CAS原子指令虽然相对于重量级锁来说开销比较小但还是存在非常可观的本地延迟(可参考这篇文章)。 适应性自旋(Adaptive Spinning):当线程在获取轻量级锁的过程中执行CAS操作失败时,在进入与monitor相关联的操作系统重量级锁 (mutex semaphore)前会进入忙等待(Spinning)然后再次尝试,当尝试一定的次数后如果仍然没有成功则调用与该monitor关联的semaphore(即互斥锁), 进入到阻塞状态。
注:(适应性)自旋锁,是在从轻量级锁向重量级锁膨胀的过程中使用的,是在进入重量级锁之前进行的。
轻量级锁具体实现: 一个线程能够通过两种方式锁住一个对象:1、通过膨胀一个处于无锁状态(状态位001)的对象获得该对象的锁; 2、对象已经处于膨胀状态(状态位00)但LockWord指向的monitor record的Owner字段为NULL, 则可以直接通过CAS原子指令尝试将Owner设置为自己的标识来获得锁。 从中可以看出,是先检查锁的标识位。
看下面这篇文章的记录: http://www.cnblogs.com/javaminer/p/3892288.html?utm_source=tuicool&utm_medium=referral 偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令。 其他,这篇文章也没什么需要注意的内容了。 这时候,我突然想到,为什么CAS就不能对标识位和数据一起操作呢,一次操作完成是否可以呢? CAS应用 CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
下面从分析比较常用的CPU(intel x86)来解释CAS的实现原理。
下面是sun.misc.Unsafe类的compareAndSwapInt()方法的源代码:
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
可以看到这是个本地方法调用。这个本地方法在openjdk中依次调用的c++代码为:unsafe.cpp,atomic.cpp和atomicwindowsx86.inline.hpp。
对于32位/64位的操作应该是原子的: 奔腾6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器不能自动保证其原子性, 比如跨总线宽度,跨多个缓存行,跨页表的访问。但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。 CAS的缺点
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作 1. ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A, 那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。 在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。 从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。 这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等, 则以原子方式将该引用和该标志的值设置为给定的更新值。 关于ABA问题参考文档: http://blog.hesey.net/2011/09/resolve-aba-by-atomicstampedreference.html 2. 循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升, pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源, 延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。 第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。 3. 只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作, 但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁, 或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。 从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
AtomicReference类的学习可以参考以下 http://www.cnblogs.com/skywang12345/p/3514623.html 简单源码示例如下(已经实际实验验证):
// AtomicReferenceTest.java的源码
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceTest {
public static void main(String[] args){
// 创建两个Person对象,它们的id分别是101和102。
Person p1 = new Person(101);
Person p2 = new Person(102);
// 新建AtomicReference对象,初始化它的值为p1对象
AtomicReference ar = new AtomicReference(p1);
// 通过CAS设置ar。如果ar的值为p1的话,则将其设置为p2。
ar.compareAndSet(p1, p2);
Person p3 = (Person)ar.get();
System.out.println("p3 is "+p3);
System.out.println("p3.equals(p1)="+p3.equals(p1));
}
}
class Person {
volatile long id;
public Person(long id) {
this.id = id;
}
public String toString() {
return "id:"+id;
}
}
运行结果: p3 is id:102 p3.equals(p1)=false
以上,是关于synchronized, 偏向锁,轻量级锁,重量级锁,自旋锁,CAS等的一些内容和笔记。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Java对象头里的Mark Word里默认存储对象的HashCode,分代年龄和锁标记位。32位JVM的Mark Word的默认存储结构如下:
|
|
25 bit |
4bit |
1bit 是否是偏向锁 |
2bit 锁标志位 |
| 无锁状态 |
对象的hashCode |
对象分代年龄 |
0 |
01 |
在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。Mark Word可能变化为存储以下4种数据:
| 锁状态 |
25 bit |
4bit |
1bit |
2bit |
||
| 23bit |
2bit |
是否是偏向锁 |
锁标志位 |
|||
| 轻量级锁 |
指向栈中锁记录的指针 |
00 |
||||
| 重量级锁 |
指向互斥量(重量级锁)的指针 |
10 |
||||
| GC标记 |
空 |
11 |
||||
| 偏向锁 |
线程ID |
Epoch |
对象分代年龄 |
1 |
01 |
|
上图里面的GC标记,为11的话,推断应该是准备GC的意思。
在64位虚拟机下,Mark Word是64bit大小的,其存储结构如下:
| 锁状态 |
25bit |
31bit |
1bit |
4bit |
1bit |
2bit |
|
|
|
|
cms_free |
分代年龄 |
偏向锁 |
锁标志位 |
||
| 无锁 |
unused |
hashCode |
|
|
0 |
01 |
|
| 偏向锁 |
ThreadID(54bit) Epoch(2bit) |
|
|
1 |
01 |
||
锁的升级
Java SE1.6为了减少获得锁和释放锁所带来的性能消耗,引入了“偏向锁”和“轻量级锁”,
所以在Java SE1.6里锁一共有四种状态,无锁状态,偏向锁状态,轻量级锁状态和重量级锁状态,它会随着竞争情况逐渐升级。
锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。
这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率,下文会详细分析。

偏向锁
Hotspot的作者经过以往的研究发现大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。 当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID, 以后该线程在进入和退出同步块时不需要花费CAS操作来加锁和解锁,而只需简单的测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁, 如果测试成功,表示线程已经获得了锁,如果测试失败,则需要再测试下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁),如果没有设置, 则使用CAS竞争锁,如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。 偏向锁的撤销:偏向锁使用了一种等到竞争出现才释放锁的机制,所以当其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁。 偏向锁的撤销,需要等待全局安全点(在这个时间点上没有字节码正在执行), 它会首先暂停拥有偏向锁的线程,然后检查持有偏向锁的线程是否活着, 如果线程不处于活动状态,则将对象头设置成无锁状态, 如果线程仍然活着,拥有偏向锁的栈会被执行,遍历偏向对象的锁记录, 栈中的锁记录和对象头的Mark Word要么重新偏向于其他线程,要么恢复到无锁或者标记对象不适合作为偏向锁,最后唤醒暂停的线程。 上面的意思是,先暂停持有偏向锁的线程,尝试直接切换。如果不成功,就继续运行,并且标记对象不适合偏向锁,锁膨胀(锁升级)。 详见,上面有张图中的“偏向锁抢占模式”: 其中提到了mark word中的lock record指向堆栈最近的一个线程的lock record,其实就是按照先来后到模式进行了轻量级的加锁。
上文提到全局安全点:在这个时间点上没有字节码正在执行。
关闭偏向锁:偏向锁在Java 6和Java 7里是默认启用的,但是它在应用程序启动几秒钟之后才激活, 如有必要可以使用JVM参数来关闭延迟-XX:BiasedLockingStartupDelay = 0。 如果你确定自己应用程序里所有的锁通常情况下处于竞争状态,可以通过JVM参数关闭偏向锁-XX:-UseBiasedLocking=false,那么默认会进入轻量级锁状态。
轻量级锁
轻量级锁加锁:线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。
然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
轻量级锁解锁:轻量级解锁时,会使用原子的CAS操作来将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。
如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
注:轻量级锁会一直保持,唤醒总是发生在轻量级锁解锁的时候,因为加锁的时候已经成功CAS操作;而CAS失败的线程,会立即锁膨胀,并阻塞等待唤醒。(详见下图)
下图是两个线程同时争夺锁,导致锁膨胀的流程图。
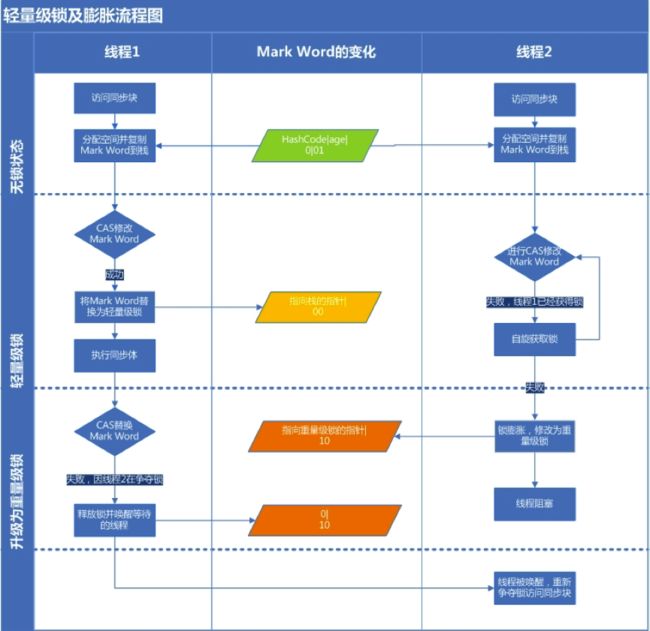
锁不会降级
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。 当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
锁的优缺点对比
| 锁 |
优点 |
缺点 |
适用场景 |
| 偏向锁 |
加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。 |
如果线程间存在锁竞争,会带来额外的锁撤销的消耗。 |
适用于只有一个线程访问同步块场景。 |
| 轻量级锁 |
竞争的线程不会阻塞,提高了程序的响应速度。 |
如果始终得不到锁竞争的线程使用自旋会消耗CPU。 |
追求响应时间。 同步块执行速度非常快。 |
| 重量级锁 |
线程竞争不使用自旋,不会消耗CPU。 |
线程阻塞,响应时间缓慢。 |
追求吞吐量。 同步块执行速度较长。 |
上面这张表格好好看,总结的非常好!
6 参考源码
对象头源码markOop.hpp。偏向锁源码biasedLocking.cpp。以及其他源码ObjectMonitor.cpp和BasicLock.cpp。
上面这篇文章(http://www.infoq.com/cn/articles/java-se-16-synchronized)讲得非常清晰了。下面还有几篇文章之前打开了,看是否有补充。
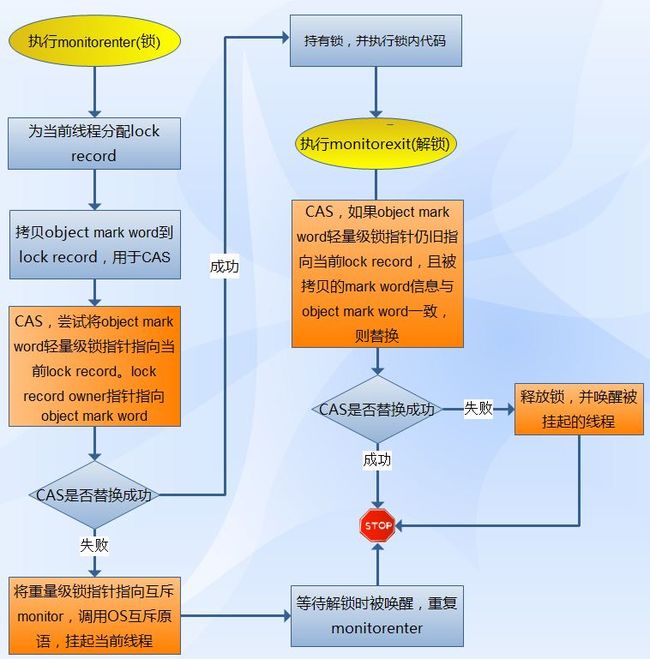
http://blog.csdn.net/wolegequdidiao/article/details/45116141
这篇文章提到:
轻量级锁加锁进行的CAS操作中,是先更新Lock Record指针,然后再更新最后2bit的锁标记位(也不一定,没有明确说。但是各种锁的顺序要一致;注:涉及偏向锁,很可能是先改锁标记位的)。
下面这张图,和上面那张图是一致的:
总结
轻量级锁能提高程序同步性能的依据是“对于绝大部分的锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用CAS操作避免了使用互斥量的开销,但如果存在锁竞争,除了互斥量的开销外,还额外发生了CAS操作,因此在有竞争的情况下,轻量级锁会比传统的重量级锁更慢。
偏向锁
JDK1.6引入
-
- 优点:消除数据在无竞争情况下的同步原语,提高性能。
- 偏向锁与轻量级锁理念上的区别:
- 轻量级锁:在无竞争的情况下使用CAS操作去消除同步使用的互斥量
- 偏向锁:在无竞争的情况下把整个同步都消除掉,连CAS操作都不做了
- 意义:锁偏向于第一个获得它的线程。如果在接下来的执行过程中,该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。
- 相关参数:
- 默认-XX:+UseBiasedLocking=true
- -XX:-UseBiasedLocking=false关闭偏向锁
- 应用程序启动几秒钟之后才激活
- -XX:BiasedLockingStartupDelay = 0关闭延迟
注意:偏向锁的锁标记位和无锁是一样的,都是01,但是有单独一位偏向标记设置是否偏向锁。
再复习一下,轻量级锁00,重量级锁10,GC标记11,无锁 01.
下面这张图做一个复习:

总结
偏向锁可以提高带有同步但无竞争的程序性能。如果程序中大多数的锁总是被多个不同的线程访问,那偏向模式就是多余的。
在具体情形分析下,禁止偏向锁优反而可能提升性能。
看这篇文章的一些笔记 http://www.cnblogs.com/javaminer/p/3889023.html
在jdk1.6中对锁的实现引入了大量的优化,如锁粗化(Lock Coarsening)、锁消除(Lock Elimination)、轻量级锁(Lightweight Locking)、 偏向锁(Biased Locking)、适应性自旋(Adaptive Spinning)等技术来减少锁操作的开销。 锁粗化(Lock Coarsening):也就是减少不必要的紧连在一起的unlock,lock操作,将多个连续的锁扩展成一个范围更大的锁。 锁消除(Lock Elimination):通过运行时JIT编译器的逃逸分析来消除一些没有在当前同步块以外被其他线程共享的数据的锁保护, 通过逃逸分析也可以在线程本地Stack上进行对象空间的分配(同时还可以减少Heap上的垃圾收集开销)。 轻量级锁(Lightweight Locking):这种锁实现的背后基于这样一种假设,即在真实的情况下我们程序中的大部分同步代码一般都处于无锁竞争状态 (即单线程执行环境),在无锁竞争的情况下完全可以避免调用操作系统层面的重量级互斥锁, 取而代之的是在monitorenter和monitorexit中只需要依靠一条CAS原子指令就可以完成锁的获取及释放。 当存在锁竞争的情况下,执行CAS指令失败的线程将调用操作系统互斥锁进入到阻塞状态,当锁被释放的时候被唤醒(具体处理步骤下面详细讨论)。 偏向锁(Biased Locking):是为了在无锁竞争的情况下避免在锁获取过程中执行不必要的CAS原子指令, 因为CAS原子指令虽然相对于重量级锁来说开销比较小但还是存在非常可观的本地延迟(可参考这篇文章)。 适应性自旋(Adaptive Spinning):当线程在获取轻量级锁的过程中执行CAS操作失败时,在进入与monitor相关联的操作系统重量级锁 (mutex semaphore)前会进入忙等待(Spinning)然后再次尝试,当尝试一定的次数后如果仍然没有成功则调用与该monitor关联的semaphore(即互斥锁), 进入到阻塞状态。
注:(适应性)自旋锁,是在从轻量级锁向重量级锁膨胀的过程中使用的,是在进入重量级锁之前进行的。
轻量级锁具体实现: 一个线程能够通过两种方式锁住一个对象:1、通过膨胀一个处于无锁状态(状态位001)的对象获得该对象的锁; 2、对象已经处于膨胀状态(状态位00)但LockWord指向的monitor record的Owner字段为NULL, 则可以直接通过CAS原子指令尝试将Owner设置为自己的标识来获得锁。 从中可以看出,是先检查锁的标识位。
看下面这篇文章的记录:
http://www.cnblogs.com/javaminer/p/3892288.html?utm_source=tuicool&utm_medium=referral
偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令。 其他,这篇文章也没什么需要注意的内容了。
这时候,我突然想到,为什么CAS就不能对标识位和数据一起操作呢,一次操作完成是否可以呢?
CAS应用
CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
下面从分析比较常用的CPU(intel x86)来解释CAS的实现原理。
下面是sun.misc.Unsafe类的compareAndSwapInt()方法的源代码:
public final native boolean compareAndSwapInt(Object o, long offset,
int expected,
int x);
可以看到这是个本地方法调用。这个本地方法在openjdk中依次调用的c++代码为:unsafe.cpp,atomic.cpp和atomicwindowsx86.inline.hpp。
对于32位/64位的操作应该是原子的:
奔腾6和最新的处理器能自动保证单处理器对同一个缓存行里进行16/32/64位的操作是原子的,但是复杂的内存操作处理器不能自动保证其原子性, 比如跨总线宽度,跨多个缓存行,跨页表的访问。但是处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
CAS的缺点
CAS虽然很高效的解决原子操作,但是CAS仍然存在三大问题。ABA问题,循环时间长开销大和只能保证一个共享变量的原子操作 1. ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A, 那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。ABA问题的解决思路就是使用版本号。 在变量前面追加上版本号,每次变量更新的时候把版本号加一,那么A-B-A 就会变成1A-2B-3A。 从Java1.5开始JDK的atomic包里提供了一个类AtomicStampedReference来解决ABA问题。 这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等, 则以原子方式将该引用和该标志的值设置为给定的更新值。 关于ABA问题参考文档: http://blog.hesey.net/2011/09/resolve-aba-by-atomicstampedreference.html 2. 循环时间长开销大。自旋CAS如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升, pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源, 延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。 第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。 3. 只能保证一个共享变量的原子操作。当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作, 但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁, 或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。 从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作。
AtomicReference类的学习可以参考以下
http://www.cnblogs.com/skywang12345/p/3514623.html
简单源码示例如下(已经实际实验验证):
// AtomicReferenceTest.java的源码
import java.util.concurrent.atomic.AtomicReference;
public class AtomicReferenceTest {
public static void main(String[] args){
// 创建两个Person对象,它们的id分别是101和102。
Person p1 = new Person(101);
Person p2 = new Person(102);
// 新建AtomicReference对象,初始化它的值为p1对象
AtomicReference ar = new AtomicReference(p1);
// 通过CAS设置ar。如果ar的值为p1的话,则将其设置为p2。
ar.compareAndSet(p1, p2);
Person p3 = (Person)ar.get();
System.out.println("p3 is "+p3);
System.out.println("p3.equals(p1)="+p3.equals(p1));
}
}
class Person {
volatile long id;
public Person(long id) {
this.id = id;
}
public String toString() {
return "id:"+id;
}
}
运行结果:
p3 is id:102 p3.equals(p1)=false
以上,是关于synchronized, 偏向锁,轻量级锁,重量级锁,自旋锁,CAS等的一些内容和笔记。