【Python行业分析3】BOSS直聘招聘信息获取之爬虫程序分析
今天我们要正式使用程序来爬取BOSS的招聘数据了,我会从最基础的一步一步去完善程序,帮助大家来理解爬虫程序,其中还是有许多问题我没能解决,也希望有大佬可以留言帮助一下
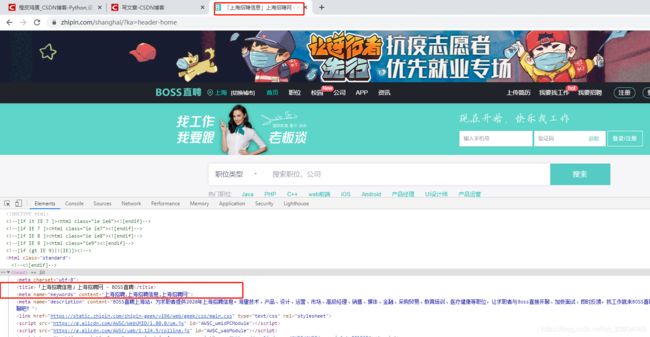
首先我们来访问下页面,看下结果是不是和浏览器访问是一致的
具体的页面返回的信息太多了,我们可以发现访问不同页面的Title是不同的,是按我们的查询条件变化的,那我们暂时可以只关注Title的变化吧
from bs4 import BeautifulSoup as bs
import requests
def de_title(func):
def wrapper(*args, **kwargs):
req = func(*args, **kwargs)
content = req.content.decode("utf-8")
content = bs(content, "html.parser")
print(func.__name__, content.find("title").text)
return wrapper
@de_title
def test1():
req = requests.get('https://www.zhipin.com')
return req
@de_title
def test2():
req = requests.get('https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=100109')
return req
if __name__ == "__main__":
test1()
test2()

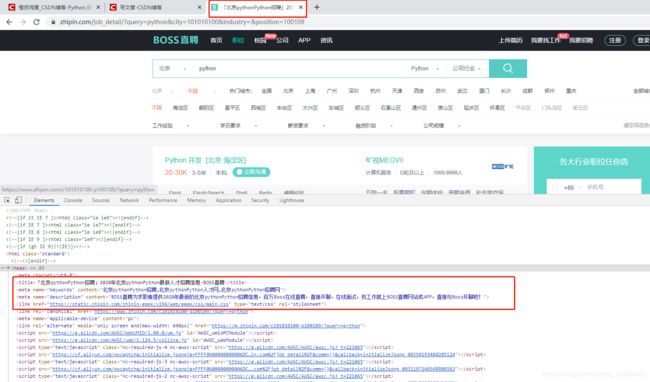
从返回结果可以看到首页是正常返回了,但是查询页的结果和预期是有区别的
我再次到浏览器刷新下查询页,如果你的网络不好的话是也是可以看到会有个请稍等的加载过程
经过百度后了解到,这是在进行cookies的生成
获取Cookies
确实上面的代码很简单,只是去访问,并没有添加cookies信息,boss肯定做了很多防爬功能的。
先分析一波噢,我们可以爬取到首页就说明首页是不需要cookies验证的,我们可以先打开浏览器的F12进入Application看看cookies的样子
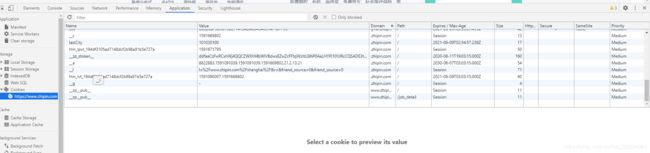
可以看多左侧有个Cookies,然后右击网址可以看到Clear,我们把保存的cookies先清除掉,看到时什么时候生成的
cookies的key有 __c 和 Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a,好像是有效时间,但是实际测试好像并没有1个小时。


在cookies还存在一个加密字段__zp_stoken__再次分析boss的cookies生产机制,我无法触发js生成有效的cookies,且__zp_stoken__加密好难,找到相关文章也表示看不懂,放弃
此时可以想到,既然首页是不需要缓存的,我们可以先访问主页,使用主页生成的cookies继续访问后续页面,这样看似是可以的,但是爬虫和我们用的浏览器的获取过程还是有区别的,在浏览器获取页面后会解析html渲染其中的js、css等,boss生成cookies时,需要js获取当前路由再重定向到特点的路由,经过多次计算后生成的,爬虫是没办直接渲染的,再次放弃、放弃
但是为了能获取到一部分数据,只能从浏览器获取最新的cookies信息,定时刷新浏览器来保持cookies的时效,真low
GO! 从浏览器获取Cookies信息

import os
import json
import base64
import sqlite3
from win32crypt import CryptUnprotectData
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
def get_string(local_state):
with open(local_state, 'r', encoding='utf-8') as f:
s = json.load(f)['os_crypt']['encrypted_key']
return s
def pull_the_key(base64_encrypted_key):
encrypted_key_with_header = base64.b64decode(base64_encrypted_key)
encrypted_key = encrypted_key_with_header[5:]
key = CryptUnprotectData(encrypted_key, None, None, None, 0)[1]
return key
def decrypt_string(key, data):
nonce, cipherbytes = data[3:15], data[15:]
aesgcm = AESGCM(key)
plainbytes = aesgcm.decrypt(nonce, cipherbytes, None)
plaintext = plainbytes.decode('utf-8')
return plaintext
def get_cookie_from_chrome(host):
local_state = os.environ['LOCALAPPDATA'] + r'\Google\Chrome\User Data\Local State'
cookie_path = os.environ['LOCALAPPDATA'] + r"\Google\Chrome\User Data\Default\Cookies"
sql = "select host_key,name,encrypted_value from cookies where host_key='%s'" % host
with sqlite3.connect(cookie_path) as conn:
cu = conn.cursor()
res = cu.execute(sql).fetchall()
cu.close()
cookies = {}
key = pull_the_key(get_string(local_state))
for host_key, name, encrypted_value in res:
if encrypted_value[0:3] == b'v10':
cookies[name] = decrypt_string(key, encrypted_value)
else:
cookies[name] = CryptUnprotectData(encrypted_value)[1].decode()
# print(cookies)
return cookies
if __name__ == "__main__":
print(get_cookie_from_chrome('.zhipin.com'))
# 打印结果
> {'Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a': '1591673534', 'Hm_lvt_194df3105ad7148dcf2b98a91b5e727a': '1591090007,1591669802', '__a': '8822883.1591091039.1591091039.1591669802.22.2.14.22', '__c': '1591669802', '__g': '-', '__l': 'l=%2Fwww.zhipin.com%2Fshanghai%2F&r=&friend_source=0&friend_source=0', '__zp_stoken__': 'ddfaaCzFwRCxhSDdVFyZWXhMbWlVzT3c9XEtcFFtqWzJsClIXOkAaLHYPQU4EVQFRQSADE3tSDRQoX3dkHBwcGUxZKzhQID5pY35mGiMvDT8aR2cvOlt0Ukc5YSoYQitNAxlGbCBbZz9gTSU%3D', 'lastCity': '101020100'}
把Cookies加到请求中
from tp.boss.get_cookies import get_cookie_from_chrome
from bs4 import BeautifulSoup as bs
import requests
@de_title
def test3():
cookie_dict = get_cookie_from_chrome('.zhipin.com')
# 将字典转为CookieJar:
cookies = requests.utils.cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True)
s = requests.Session()
s.cookies = cookies
req = s.get('https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=100109')
return req
if __name__ == "__main__":
test1()
test2()
test3()
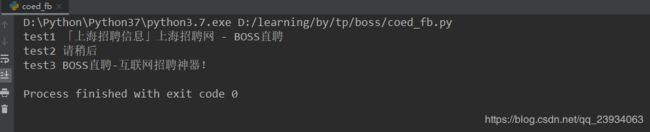
又有状况,这不是查询应该有的Title,但Cookies的问题好像是过去了,打印下详情看看吧

原来是限制的IP,加个header试试吧
from tp.boss.get_cookies import get_cookie_from_chrome
from bs4 import BeautifulSoup as bs
import requests
import random
@de_title
def test4():
user_agent_list = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/61.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15"
]
headers = {
"user-agent": random.choice(user_agent_list)
}
cookie_dict = get_cookie_from_chrome('.zhipin.com')
# 将字典转为CookieJar:
cookies = requests.utils.cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True)
s = requests.Session()
s.cookies = cookies
s.headers = headers
req = s.get('https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=100109')
return req
if __name__ == "__main__":
test1()
test2()
test3()
test4()

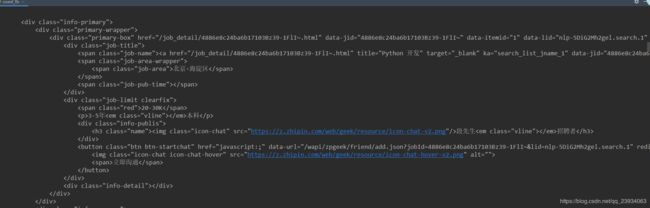
我们终于看到了招聘信息
不行的话 要刷新下浏览器噢 太low了。。。