漫谈Java基本数据类型的自动装拆箱机制
自动拆装箱机制说明
Java对8个基本数据类型有个自动拆装箱机制,使用方式类似如下
int i = new Integer(3); Integer i = 3;
会根据变量的类型对实际的对象做拆箱或者装箱,比如 把 new Integer(3) 拆箱成3 ,把 3 装箱成 Integer(3)。
基本数据类型和包装类型有什么区别
简单了说就是 3 和 Integer(3) 的区别:
int:
如果使用 int i = 3 的形式来定义一个变量,那么这个 3 是在 线程栈 里,用局部变量表来存储:
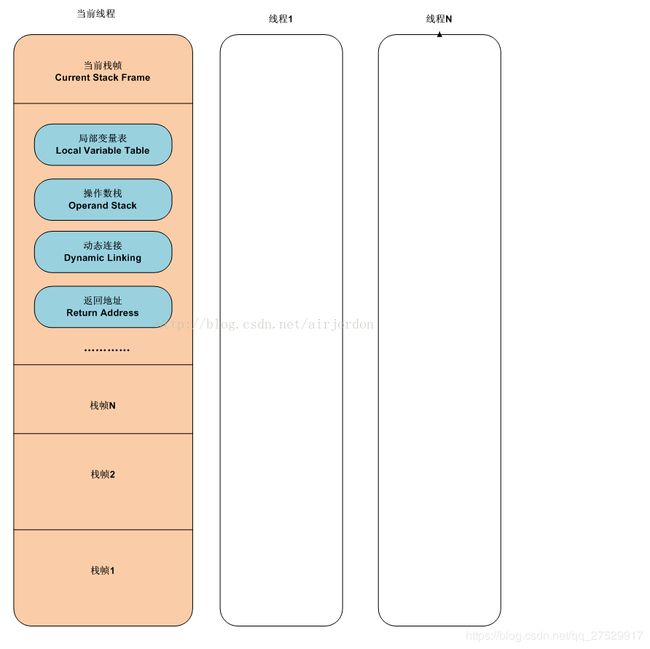
一个方法就是一个栈帧,每帧里有自己的局部变量表,就是说每个方法有自己的局部变量表,数据存储在栈里,没有分配在堆里,也没有分片在堆内的运行时常量池里,无论分配多少个都不会对堆有影响,也就不会有GC相关的问题,但栈里还是会占用空间,至少4个字节(不确定更多)。
因此在方法内部用递归式的循环,且定义很多局部变量时,很容易出现StackOverFlow的 Error,而不是OutOfMemoryError。
一个栈帧退出时,也就是方法结束时,局部变量表会被清空。
Integer:
new Integer(3) 会在堆中分配一个Integer对象,Integer 内部的 3 不会再引用到运行时常量池,直接就是一个int ,4个字节。所以一个Integer 对象占用16个字节。如果Integer对象定义太多,可能会造成OutOfMemoryError。
为什么要对基本数据类型做拆装箱?
数据大小
一个基本为包装过的基本数据类型对象,小则1字节,大则8字节,而包装过的基本数据类型对象,小则16字节,大则24字节。
如果没有简化版的基本数据类型,都用对象,那么实际使用时都分配在堆中,而基本数据类型是用的最多的,很容易造成频繁的GC,降低应用的吞吐量,甚至有OOM的风险。
数据同步
线程在工作时不会直接操作主内存中的数据,而是将数据拷贝到线程栈内,在操作完后同步到主内存中,这样才是CPU能高速运行的前提之一。在堆中分配的基本数据类型对象,在使用时还是要把值拷贝到栈中,那么将对象简化到直接分配在栈中岂不是更好,当然这样的前提是对象都很小,而且对象是不可变的,也就是只能用 “=” 赋值,而不能改变内部的数据,基本数据类型恰好都复合这两点,所以用拆箱的基本数据类型比装箱的在大部分情形下都是好的。
数据不可变
基本数据类型都是不可变的,也就是只能赋值而不能改变其内在的属性,所以在栈中操作时不需要同步到堆内存中,这也自动拆箱的一个额外好处。
堆内对象用到栈内基本类型的局部变量怎么办?
int i = 3;
Map<Integer,String> map = new HashMap<>();
map.put(i,"");
堆里的map对象用到了栈里的 i,这时会发生什么?
之前说了,栈里的局部变量表是针对当前栈帧的,当帧被释放后,表示当前方法结束了,局部变量会失效,也就是 i 会不复存在。 但是 map 对象可能被其他地方引用,也就是在方法结束后map对象能继续存活下去,那么可以肯定此时map 里的 i 不是栈里的局部变量了。
当map.put(i,"") 时,jvm会在堆里面对 i 做一个装箱,生成一个new Integer(3),作为map的key。堆内的对象在操作拆箱的基本数据类型时,且其要作为一个对象存在时,会自动为其重新生成一个装箱过的对象。
Map的key是一个对象,所以自动对基本数据类型做封装,但如果不一定需要对象时,则不会封装,比如以下情形:
int i = 3;
List<Integer> list = new ArrayList<>();
list.add(i);
list 里加入的是一个原始的i,而不是装箱过的Integer。
总结
自动拆装箱机制能够方便定义变量,同时也能减少内存的分配,转而使用栈内的局部变量表,这在一定程度上能提高应用的效率。