初识scrapy框架,安装&简单爬取
Scrapy基础使用
- 一、scrapy安装与环境依赖
- 1.在安装scrapy前需要安装好相应的依赖库, 再安装scrapy, 具体安装步骤如下:
- 2.创建项目
- 3.项目目录介绍
- 4.scrapy框架介绍: 5大核心组件与数据流向
- (1)架构:
- (2).工作流:
- 管道类的注册配置
一、scrapy安装与环境依赖
1.在安装scrapy前需要安装好相应的依赖库, 再安装scrapy, 具体安装步骤如下:
(1).安装lxml库: pip install lxml
(2).安装wheel: pip install wheel
(3).安装twisted: pip install twisted文件路径
(twisted需下载后本地安装,下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted)
(版本选择如下图,版本后面有解释,请根据自己实际选择)
(4).安装pywin32: pip install pywin32
(注意:以上安装步骤一定要确保每一步安装都成功,没有报错信息,如有报错自行百度解决)
(5).安装scrapy: pip install scrapy
(注意:以上安装步骤一定要确保每一步安装都成功,没有报错信息,如有报错自行百度解决)
(6).成功验证:在cmd命令行输入scrapy,显示Scrapy1.6.0-no active project,证明安装成功

2.创建项目
1.手动创建一个目录test
2.在test文件夹下创建爬虫项目为spiderpro: scrapy startproject spiderpro
3.进入项目文件夹: cd spiderpro
4.创建爬虫文件: scrapy genspider 爬虫名 域名
3.项目目录介绍
-spiderpro
----spiderpro # 项目目录
------__init__
------spiders: 爬虫文件目录
--------__init__
--------tests.py: 爬虫文件
------items.py: 定义爬取数据持久化的数据结构
------middlewares.py: 定义中间件
------pipelines.py: 管道,持久化存储相关
------settings.py: 配置文件
venv: 虚拟环境目录
scrapy.cfg: scrapy项目配置文件
说明:
- spiders:其内包含一个个Spider的实现, 每个Spider是一个单独的文件
- items.py:它定义了Item数据结构, 爬取到的数据存储为哪些字段
- pipelines.py:它定义Item Pipeline的实现
- settings.py:项目的全局配置
- middlewares.py:定义中间件, 包括爬虫中间件和下载中间件
- scrapy.cfg:它是scrapy项目的配置文件, 其内定义了项目的配置 路径, 部署相关的信息等
4.scrapy框架介绍: 5大核心组件与数据流向
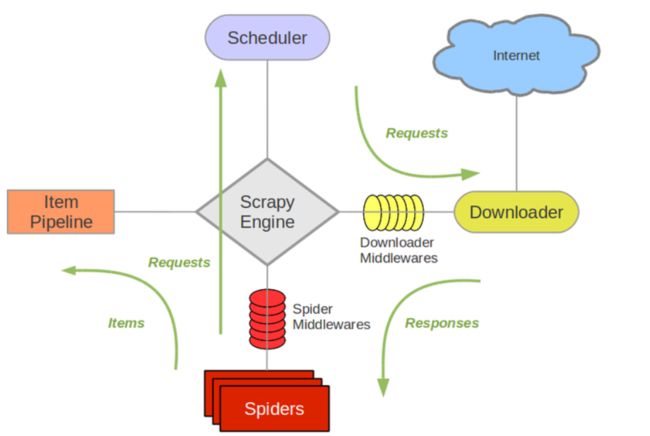
(1)架构:
-
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!
-
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
-
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理
-
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
-
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
-
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
-
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
(2).工作流:
-
spider将请求发送给引擎, 引擎将request发送给调度器进行请求调度
-
调度器把接下来要请求的request发送给引擎, 引擎传递给下载器, 中间会途径下载中间件
-
下载携带request访问服务器, 并将爬取内容response返回给引擎, 引擎将response返回给spider
-
spider将response传递给自己的parse进行数据解析处理及构建item一系列的工作, 最后将item返回给引擎, 引擎传递个pipeline
-
pipe获取到item后进行数据持久化
-
以上过程不断循环直至爬虫程序终止
下面以爬取开源中国博客作为简单的scrapy爬虫实例
# 创建项目:
scrapy startproject kycn # 创建项目
cd kycn # 切换到项目目录
scrapy genspider ky
# item文件定义数据存储的字段:
import scrapy
class KycnItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
brief = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
see = scrapy.Field()
comment = scrapy.Field()
like = scrapy.Field()
typename = scrapy.Field()
imgname = scrapy.Field()
# spider文件中定义解析数据的方法
from ..items import KycnItem
class KySpider(scrapy.Spider):
name = 'ky'
# allowed_domains = ['baidu.com']
start_urls = ['https://www.oschina.net/blog']
def imgdown(self,response):
item=response.meta['item']
# with open("C:/Users/Desktop/images/kyitem2/{}".format(item["imgname"]),"wb") as f :
# f.write(response.body)
yield item
def detailparse(self,response):
typ = response.meta["typ"]
div_list = response.xpath('//div[@class="item blog-item"]')
# print(div_list)
for div in div_list:
title = div.xpath(".//a[@class='header']/@title").extract_first()
brief = div.xpath(".//div[@class='description']/p/text()").extract_first()
author = div.xpath(".//div[@class='ui horizontal list']/div[1]/a/text()").extract_first()
date = div.xpath(".//div[@class='ui horizontal list']/div[2]/text()").extract_first()
see = div.xpath(".//div[@class='ui horizontal list']/div[3]/text()").extract_first()
comment = div.xpath(".//div[@class='ui horizontal list']/div[4]/a/text()").extract_first()
like = div.xpath(".//div[@class='ui horizontal list']/div[5]/text()").extract_first()
typename = typ
img_url = div.xpath(".//a[@class='ui small image']/img/@src").extract_first()
if all([title,brief,author,date,see,comment,like,typename,img_url]):
item = KycnItem()
item["title"]=title
item["brief"]=brief
item["author"]=author
item["date"]=date
item["see"]=see
item["comment"]=comment
item["like"]=like
item["typename"]=typename
item["imgname"] = img_url.split("/")[-1]
yield scrapy.Request(url=img_url,callback=self.imgdown,meta={"item":item})
def parse(self, response):
div = response.xpath('//div[@class="two wide column computer only left-channel"]/div[1]/a/@href').extract()[1:]
title = response.xpath('//div[@class="two wide column computer only left-channel"]/div[1]/a/text()').extract()[1:]
# print(div,title)
for i in div:
yield scrapy.Request(url=i,callback=self.detailparse,meta={"typ":title[div.index(i)]})
# 在pipeline中定义管道类进行数据的存储
import pymongo
class KycnPipeline(object):
conn = pymongo.MongoClient()
db = conn.kycn
table = db.table2
def process_item(self, item, spider):
self.table.insert_one(dict(item))
return item
# 此示例中配置文件中的配置的项, 注意是不是全部的配置, 是针对该项目增加或修改的配置项
# 忽略robots协议
ROBOTSTXT_OBEY = False
# UA伪装
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
# 管道类的注册配置
ITEM_PIPELINES ={
'kycn.pipelines.KycnPipeline': 300,
}
= 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
管道类的注册配置
ITEM_PIPELINES ={
'kycn.pipelines.KycnPipeline': 300,
}