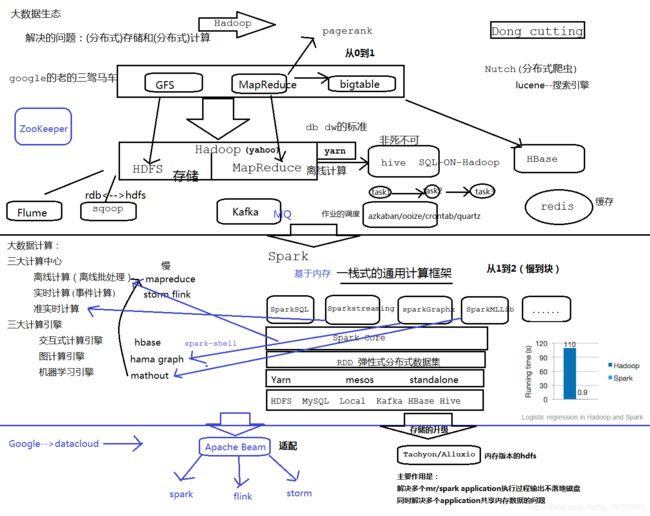
Spark系列01,Spark简介、安装、相关名词解释
Spark系列01,Spark简介、相关名词解释
- 导论
- Spark 概述
- Spark集群的安装
- 本地提交一个Spark的作业
- Spark的安装
- 单机式安装
- 完全分布式的配置
- 修改spark文件夹下conf目录中的spark-env.sh
- 修改slaves配置文件
- 名词解释
- Spark编程相关名词
导论
Spark 概述
Spark就是一款全栈的计算引擎,底层基于RDD(弹性式分布式数据集 Resilient Distributed Dataset),主要是基于内存的计算,官网号称基于磁盘比mr快10倍,基于内存比mr块100倍。具有高速、易用、通用性强、运行环境广的特点。
RDD的解释:
- 弹性:数据主要基于内存存储,如果内存不够,磁盘顶上。
- 数据集:就是一个普通的scala的不可变的集合(Array, Map,Set)
- 分布式:一个完整的RDD数据集,被拆分成多个部分,在不同的机器里面存储。被拆分成的部分称之为该RDD的分区partition,就类似于hdfs中的一个文件file被拆分成多个block块存储一样。
- RDD只是这些partition的抽象ADT(abstract data type),在这个ADT上面我们定义了非常多的操作,比如flatMap、比如map、filter等等高阶函数。
- 真正存储数据的是partition,RDD不存储数据,RDD就是对这个partition的抽象。又因为RDD是一个scala集合,在scala集合上面有非常多个的算子操作,比如flatMap、map、reduce、sum等等。可以理解为是一个ADT(abstract data type抽象数据类型)
Spark集群的安装
下载安装包的地址:http://archive.apache.org/dist/spark
- 安装要求

2.Window运行Spark
启动spark/bin/spark-shell.cmd2
![]()
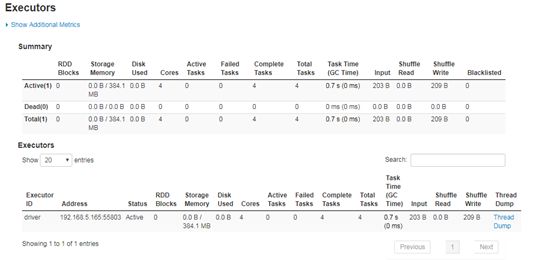
我们可以了解到,每一个Spark应用程序,都会对应一个WebUI,默认的访问端口4040,如果被占用,就依次累加,4041,4042…

本地提交一个Spark的作业
Stage-0

stage-1

由此可见Spark的作业执行是分阶段的
Executor:执行器,在worker node上执行任务的组件,用于启动线程池运行任务。每个Application都拥有一组独立的Executors,这些Executor是在worker节点上启动的进程。
SKey实现Words Key实现Words Count
import org.apache.spark.{SparkConf, SparkContext}
object csdnspark01wc {
def main(args: Array[String]): Unit = {
//Spark的入口
val conf = new SparkConf().setAppName("csdnspark01wc").setMaster("local[2]")
val sc = new SparkContext(conf)
//此处的lines是一个RDD
val lines = sc.textFile("D:/hello.txt")
//对每一行line进行切分
val words = lines.flatMap(line =>line.split("\\s+"))
//给字段添加次数信息,每一个字段天生都是1次
val pairs = words.map(word => (word,1))
//reduceByKey将pairs按照key进行累加
val ret = pairs.reduceByKey((v1,v2)=>v1+v2)
ret.foreach(t=>println(t._1+"======>"+t._2))
}
}
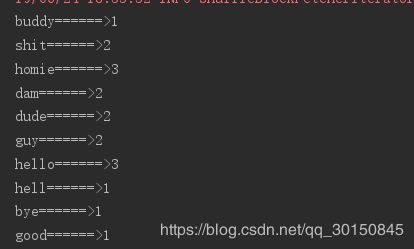
spark作业的执行,只有当这些rdd执行foreach的操作,作业才真正的执行。这里体现spark作业操作的一个特点:lazy懒加载。也就是说上面的这些算子,比如flatMap、map、reduceBykey的真正执行需要foreach的触发。
sparkRDD有两种类型①MapPartitionsRDD②ShuffledRDD这两种操作算子,高阶函数也有两种,一种是lazy延迟加载的,一种是立即执行的,把延迟加载的这些算子称为transformation算子;把立即执行的这些算子称其为action算子。也就是说,spark中的transformation操作都是lazy懒加载的,其运行需要action算子的触发。
Spark的安装
第一步安装scala
解压:~]$ tar -zxvf soft/scala-2.11.8.tgz
重命名:~]$ mv scala-2.11.8 scala
配置到环境变量:
export SCALA_HOME=/home/bigdata/app/scala
export PATH=$PATH:$SCALA_HOME/bin
单机式安装
解压重命名spark安装包到/home/bigdata/app
配置环境变量:
export SPARK_HOME=/home/bigdata/app
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
完全分布式的配置
修改spark文件夹下conf目录中的spark-env.sh
1、cd /home/bigdata/app/spark/conf
2、cp spark-env.sh.template spark-env.sh
3、vi spark-env.sh
export JAVA_HOME=/opt/jdk
export SCALA_HOME=/home/bigdata/app/scala
--- 主节点的master的ip地址或者hostname
export SPARK_MASTER_HOST=hadoop01
---7077的作业就相当于hdfs中9000
export SPARK_MASTER_PORT=7077
--- 从节点中每一个worker的cpu core的个数
export SPARK_WORKER_CORES=1
---在slaves配置中配置的每一台机器上面启动的worker的个数
每一个worker的内存资源,配置不要超过当前机器的内存资源,建议不要低于500m
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/bigdata/app/hadoop/etc/hadoop
修改slaves配置文件
部署到bigdata02和bigdata03这两台机器上(这两台机器需要提前安装scala)
scp -r /home/bigdata/app/scala bigdata@bigdata02:/home/bigdata/app
scp -r /home/bigdata/app/scala bigdata@bigdata03:/home/bigdata/app
----
scp -r /home/bigdata/app/spark bigdata@bigdata02:/home/bigdata/app
scp -r /home/bigdata/app/spark bigdata@bigdata03:/home/bigdata/app
---在bigdata02和bigdata03上加载好环境变量,需要source生效
scp ~/.bash_profile bigdata@bigdata02:/home/bigdata
scp ~/.bash_profile bigdata@bigdata03:/home/bigdata
启动
修改事宜
为了避免和hadoop中的start/stop-all.sh脚本发生冲突,将spark/sbin/start/stop-all.sh重命名
sbin]# mv start-all.sh start-all-spark.sh
sbin]# mv stop-all.sh stop-all-spark.sh
启动
sbin/start-all-spark.sh
会在我们配置的主节点master上启动一个进程Master
会在我们配置的从节点bigdata02上启动一个进程Worker
会在我们配置的从节点bigdata03上启动一个进程Worker
简单的验证
启动spark-shell
bin/spark-shell
scala> sc.textFile("hdfs://ns1/data/hello").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_+_).collect.foreach(println)
我们发现spark非常快速的执行了这个程序,计算出我们想要的结果
一个端口:8080/4040
8080-->spark集群的访问端口,类似于hadoop中的50070和8080的综合
4040-->sparkUI的访问地址
7077-->hadoop中的9000端口
=====================================================================
基于Zookeeper的HA的配置
最好在集群停止的时候来做
第一件事
注释掉spark-env.sh中两行内容
#export SPARK_MASTER_IP=bigdata01
#export SPARK_MASTER_PORT=7077
第二件事
在spark-env.sh中加一行内容
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata01:2181,bigdata02:2181,bigdata03:2181 -Dspark.deploy.zookeeper.dir=/spark"
解释
spark.deploy.recoveryMode设置成 ZOOKEEPER
spark.deploy.zookeeper.urlZooKeeper URL
spark.deploy.zookeeper.dir ZooKeeper 保存恢复状态的目录,缺省为 /spark
重启集群
在任何一台spark节点上启动start-spark-all.sh
手动在集群中其他从节点上再启动master进程:sbin/start-master.sh -->在bigdata02
通过浏览器方法 bigdata01:8080 /bigdata02:8080–>Status: STANDBY Status: ALIVE
验证HA,只需要手动停掉master上spark进程Master,等一会slave01上的进程Master状态会从STANDBY编程ALIVE
在spark集群中部署spark作业,加载hdfs文件的时候:
Caused by: java.net.UnknownHostException: ns1
解决之道:
将 S P A R K H O M E / c o n f / s p a r k − d e f a u l t . c o n f . t e m p l a t e c p 成 为 SPARK_HOME/conf/spark-default.conf.template cp成为 SPARKHOME/conf/spark−default.conf.templatecp成为SPARK_HOME/conf/spark-default.conf
然后在该文件的最后一行添加一句话:
spark.files H A D O O P H O M E / e t c / h a d o o p / h d f s − s i t e . x m l , HADOOP_HOME/etc/hadoop/hdfs-site.xml, HADOOPHOME/etc/hadoop/hdfs−site.xml,HADOOP_HOME/etc/hadoop/core-site.xml
spark-on-yarn
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
名词解释
ClusterManager:在Standalone模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器。
Worker:从节点,负责控制计算节点,启动Executor。在YARN模式中为NodeManager,负责计算节点的控制。
Driver:运行Application的main()函数并创建SparkContext。
Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
SparkContext:整个应用的上下文,控制应用的生命周期。
RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
DAG Scheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
TaskScheduler:将任务(Task)分发给Executor执行。
Stage:一个Spark作业一般包含一到多个Stage。
Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
Transformations:转换(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
Actions:操作(Actions) (如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内创建并包含如下一些重要组件的引用。
MapOutPutTracker:负责Shuffle元信息的存储。
BroadcastManager:负责广播变量的控制与元信息的存储。
BlockManager:负责存储管理、创建和查找块。
MetricsSystem:监控运行时性能指标信息。
SparkConf:负责存储配置信息。
Spark编程相关名词
- ClusterManager:在Standalone(spark自身集群模式)模式中即为Master(主节点),控制整个集群,监控Worker。在YARN模式中为资源管理器Resourcemanager。
Spark集群的管理,管理spark集群的资源(cpu core、内存),yarn中的话就是ResourceManager。 - Worker:从节点,负责控制计算节点,启动Executor。在YARN模式中为NodeManager,负责计算节点的控制。
- Driver:运行Application的main()函数并创建SparkContext。
负责向ClusterManager提交spark作业,组织spark作业,然后和spark集群中的executor进行交互。
Driver最重要的工作,就是创建SparkContext,而SparkContext就是Spark Application的入口。 - Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。
这些executor是在worker节点上面启动的进程。 - SparkContext:整个应用的上下文,控制应用的生命周期。
- RDD:Spark的基本计算单元,一组RDD可形成执行的有向无环图RDD Graph。
RDD,是一个抽象的概念,是弹性式分布式数据集。
弹性:既可以在内存,优先在内存存储并计算,如果内存不够,拿磁盘顶上。
数据集:就是一个普通的scala的不可变的集合。
分布式:一个完整的RDD数据集,被拆分成多个部分,在不同的机器里面存储。被拆分成的部分称之为该RDD的分区partition,就类似于hdfs中的一个文件file被拆分成多个block块存储一样。
真正存储数据的是partition,RDD不存储数据,RDD就是对这个partition的抽象。又因为RDD是一个scala集合,在scala集合上面有非常多个的算子操作,比如flatMap、map、reduce、sum等等。可以理解为是一个ADT(abstract data type抽象数据类型)
7) DAG Scheduler:实现将Spark作业分解成一到多个Stage,每个Stage根据RDD的Partition个数决定Task的个数,然后生成相应的Task set放到TaskScheduler中。
非常重要的作业就是进行stage阶段的划分。
8) TaskScheduler:将任务(Task)分发给Executor执行。
将DAGScheduler划分的stage(task的形式)任务,交付给executor去干活。
9) Stage:一个Spark作业一般包含一到多个Stage。
每次提交的是一个stage阶段的任务。
10) Task:一个Stage包含一到多个Task,通过多个Task实现并行运行的功能。
11) Transformations:转换(Transformations) (如:map, filter, groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
又称为转换算子
12) Actions:操作(Actions) (如:count, collect, save,foreach等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
又称为行动算子。
13) SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。SparkEnv内创建并包含如下一些重要组件的引用。
MapOutPutTracker:负责Shuffle元信息的存储。
BroadcastManager:负责广播变量的控制与元信息的存储。
BlockManager:负责存储管理、创建和查找块。
14) MetricsSystem:监控运行时性能指标信息。
15) SparkConf:负责存储配置信息。
可以理解为MR编程中的Configuration。当前应用程序的配置信息。SparkContext的构建离不开SparkConf。