C++ 引用变量,函数默认值,函数重载,函数模板,auto和decltype关键字
目录
一、引用变量
1、引用变量声明
2、引用变量作为函数入参
3、引用变量作为函数返回值
4、反汇编看引用变量使用
二、函数参数默认值
三、函数重载
1、重载函数定义
2、名称修饰
四、函数模板
1、函数模板定义
2、具体化和显示实例化
五、auto和decltype类型推断
1、auto 关键字
2、decltype关键字
3、函数模板应用
一、引用变量
引用变量相当于不可变指针的语法糖,在汇编层面引用变量的变量名等同于*p,p是指向原变量的不可变指针,修改引用变量等同于修改原变量,程序依然会将引用变量当指针一样为其分配独立的内存,但是无法通过&获取分配给引用变量的内存地址;当作为参数传递到方法或者函数时,传递的是原变量的地址,其行为跟传递原变量的不可变指针一样。引用与指针的区别如下:
- 不存在空引用,引用必须连接到一块合法的内存,而允许空指针
- 引用必须在声明时初始化指向一个变量,且不能改变所指向的变量,二次赋值实际是对所指向的变量赋值而不是对引用变量本身赋值。而指针在声明时可以不初始化,可以在任何时候指向到另一个对象。
- 指针代表着地址,而引用代表着变量。sizeof 指针,是指针的大小,sizeof 变量,是变量的大小
1、引用变量声明
基本类型变量,指针,数组,结构和类变量都可以声明对应的引用变量
#include
#include
int main() {
using namespace std;
int rats = 101;
//int &表示声明一个指向int变量的引用变量,rodents可以与rats等价使用
//引用变量相当于不可变指针的语法糖,rodents等价于*pt,但是程序不会给rodents分配内存,只是语义层面rats的一个别名
int & rodents = rats;
int* const pt = &rats;
//必须在声明时初始化引用变量
// int & a;
// a=rats;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
rodents++;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
rats++;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
(*pt)++;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
int a2 = 10;
//引用变量不能二次赋值,只能在声明时赋值,二次赋值表示对所引用的变量rats赋值
rodents = a2;
cout << "rats = " << rats;
cout << ", rodents = " << rodents << endl;
//rats和rodents内存地址相同,a2同rodents不同
cout << "rats address = " << &rats;
cout << ", rodents address = " << &rodents << endl;
cout << ", a2 address = " << &a2 << endl;
//同const指针,表示不能通过引用变量a3修改被引用变量a2的值
const int & a3=a2;
//编译报错
// a3=2;
a2=10;
cout << "a2 = " << a2;
cout << ", a3 = " << a3 << endl;
//声明指针变量的引用变量
int* const &q = pt;
cout << "pt address = " << &pt;
cout << ", q address = " << &q << endl;
//声明数组变量的引用变量
int rats2[4] = { 1, 2 };
int (&rodents2)[4] = rats2;
cout << "rats2[1] address = " << &rats2[1];
cout << ", rodents2[1] address = " << &rodents2[1] << endl;
struct user {
int age;
char name[5];
};
//c++中可以省略关键字struct,相当于编译器做了typedef
user u={12,"test"};
//声明结构变量的引用变量
user & u2=u;
cout << "u.name address = " << &u.name;
cout << ", u2.name address = " << &u2.name << endl;
string s="shl";
//声明类变量的引用变量
string & s2=s;
cout << "s address = " << &s;
cout << ", s2 address = " << &s2 << endl;
return 0;
} 2、引用变量作为函数入参
引用变量作为入参时同指针作为入参一样,可以减少变量复制的性能损耗和内存占用,提高函数调用性能,但是会函数对变量的修改会作用于原来的变量,而普通的值传递时传递到函数中的是原变量的副本,函数对变量的修改不会影响原变量。另外引用变量作为入参时同指针,相比值传递,对变量类型有严格校验,如果是1,"test"这类字面常量或者a+1这类表达式作为入参时会因类型不符报错,如果要求的是int & 或者int *,但是传递的是long &或者long *,一样因类型不符报错。C++为了增加引用变量的适用性,如果函数定义中引用变量入参是const,则编译器会自动为这类类型不符的变量创建一个符合入参类型要求的临时变量,将字面常量或者表达式的值赋值给临时变量,必要时做类型转换如将long转成int,然后将临时变量的引用变量作为入参传递到函数中。
#include
using namespace std;
void swapr(int & a, int & b); // a, b are aliases for ints
void swapp(int * p, int * q); // p, q are addresses of ints
void swapv(int a, int b); // a, b are new variables
void swapr2(const int & a);
int main() {
int wallet1 = 300;
int wallet2 = 350;
cout << "wallet1 = $" << wallet1;
cout << " wallet2 = $" << wallet2 << endl;
cout << "Trying to use passing by value:\n";
//值传递,函数使用值的副本,不会对原来的变量产生影响
swapv(wallet1, wallet2);
cout << "wallet1 = $" << wallet1;
cout << " wallet2 = $" << wallet2 << endl;
cout << "Using pointers to swap contents again:\n";
//指针传递,本质还是值传递,不过是指针的值
swapp(&wallet1, &wallet2);
cout << "wallet1 = $" << wallet1;
cout << " wallet2 = $" << wallet2 << endl;
cout << "Using references to swap contents:\n";
//引用传递,本质是指针传递,会修改原来的变量
swapr(wallet1, wallet2);
cout << "wallet1 = $" << wallet1;
cout << " wallet2 = $" << wallet2 << endl;
//编译报错,类型不符,1是字面常量,a+1是表达式,这两个都是右值,即无法被引用的数据对象
//无法被引用可以通俗理解无法用&获取该数据对象的内存地址
// swapr(1,2);
//指针一样报错
// swapp(1,2);
int a=1,b=2;
// swapr(a+1,b+2);
// swapp(a+1,b+2);
long a2=1,b2=12;
//编译报错,类型不符,编译器不会无法将指向long的引用变量强转成指向int的引用变量
// swapr(a2,b2);
//指针传递,一样报错,不能对指针类型强制转换
// swapp(&a2,&b2);
//但是如果引用变量入参被声明成const,则编译器会创建一个临时变量并初始化为对应的值,然后将该临时变量
//的引用变量传递到函数中
swapr2(1);
swapr2(a+1);
swapr2(a2);
//即使指针声明成const,一样报错类型不符
//如果是指传递,则不存在问题,编译器会自动做类型转换,自动计算表达式的值,将结果作为参数传递到函数中
// swapp2(1,2);
// swapp2(a+1,b+2);
// swapp2(&a2,&b2);
return 0;
}
void swapr(int & a, int & b) {
int temp;
temp = a;
a = b;
b = temp;
}
void swapp(int * p, int * q) {
int temp;
temp = *p;
*p = *q;
*q = temp;
}
void swapv(int a, int b) {
int temp;
temp = a;
a = b;
b = temp;
}
//const表明函数执行过程中不会修改变量a
void swapr2(const int & a) {
cout << "a=" < 3、引用变量作为函数返回值
同指针,如果返回的引用变量指向一个方法内局部变量,该局部变量在方法执行完毕会自动销毁,通过引用变量访问这个已经销毁的变量就会报错Segmentation fault,导致程序崩溃退出。因此当引用变量或者指针作为返回值时需要确保其指向一个当前方法执行完毕时不会销毁的变量,如作为函数入参的引用变量。
#include
#include
struct free_throws {
std::string name;
int made;
int attempts;
float percent;
};
void display(const free_throws & a);
//返回引用变量
free_throws & accumulate(free_throws &target, const free_throws &source);
free_throws & accumulate2(free_throws &target, const free_throws &source);
free_throws * accumulate3(free_throws * target, const free_throws * source);
int main() {
free_throws one = { "Ifelsa Branch", 13, 14 };
free_throws three = { "Minnie Max", 7, 9 };
free_throws four = { "Whily Looper", 5, 9 };
free_throws team = { "Throwgoods", 0, 0 };
accumulate(team, one);
accumulate(accumulate(team, three), four);
display(team);
//不访问accumulate2的返回值不会报错
accumulate2(team, one);
// accumulate2(accumulate2(team, three), four);
display(team);
accumulate3(&team, &one);
// accumulate3(accumulate3(&team, &three), &four);
display(team);
return 0;
}
void display(const free_throws & a) {
using namespace std;
cout << "name=" << a.name << ",made=" << a.made << ",attempts="
<< a.attempts << endl;
}
free_throws & accumulate(free_throws & target, const free_throws & source) {
target.attempts += source.attempts;
target.made += source.made;
return target;
}
free_throws & accumulate2(free_throws & target, const free_throws & source) {
//编译警告:reference to local variable ‘temp’ returned,实际执行报错Segmentation fault
//因为temp是方法内的临时变量,方法执行完毕会自动释放,调用者通过引用访问不存在的变量就报错
free_throws temp = target;
temp.attempts += source.attempts;
temp.made += source.made;
return temp;
}
free_throws * accumulate3(free_throws * target, const free_throws * source) {
//同accumulate2,返回的指针指向一个已经销毁的变量然后报错
free_throws temp = *target;
temp.attempts += source->attempts;
temp.made += source->made;
return &temp;
}
4、反汇编看引用变量使用
测试代码:
#include
int cube(int* a);
int refcube(int &ra);
int main ()
{
int x = 3.0;
int & x2=x;
int * x3=&x;
x2=4;
*x3=5;
cube(x3);
refcube(x2);
return 0;
}
int cube(int* a)
{
(*a)= (*a)*(*a);
return *a;
}
int refcube(int &ra)
{
ra *= ra * ra;
return ra;
}
movl $0x3,-0x14(%rbp) 将离rbp栈帧指针14个字节的起始位置之后的4字节初始化为3,即变量x的初始化
引用变量x2的初始化是下面两行指令:
lea -0x14(%rbp),%rax 获取变量x的内存偏移量并复制到rax寄存器中,因为不是完整的内存地址,所以只占2字节
mov %rax,-0x10(%rbp) 将rax寄存器中变量x的内存地址拷贝到离rbp栈帧指针10个字节的起始位置之后的2字节
指针x3的初始化同上,如下:
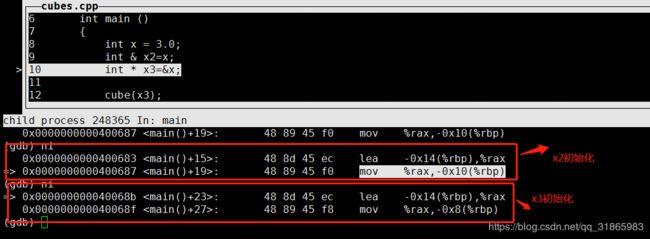
通过x2修改x变量值时,指令如下:
mov -0x10(%rbp),%rax 将变量x的内存偏移地址拷贝到rax中
movl $0x4,(%rax) 将4拷贝到rax中内存偏移地址对应的变量,即x
通过x3修改x变量时,指令同上,如下图:
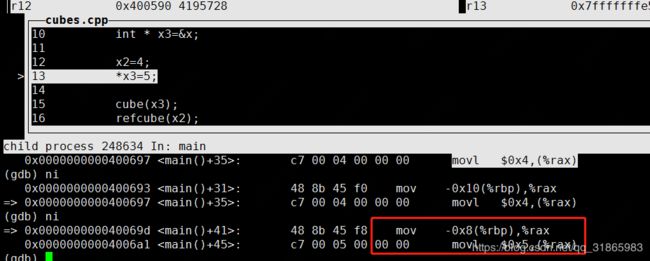
进入cube函数调用时, 指令如下:
mov -0x8(%rbp),%rax 把之前保存的x3复制到rax中
mov %rax,%rdi 把rax中的x3变量拷贝到rdi寄存器,作为函数调用的参数
执行乘法计算的指令如下:
mov -0x8(%rbp),%rax 之前的一步指令将入参拷贝到距离栈帧指针8个字节的起始位置后2两个字节,这一步是将函数入参,即变量x的内存偏移量x3拷贝到rax中
mov (%rax),%edx 将x3指向的变量x的值拷贝到edx中
mov -0x8(%rbp),%rax 同上
mov (%rax),%eax 将x3指向的变量x的值拷贝到eax中
imul %eax,%edx 将eax中的值同edx中的值相乘,结果保存在edx中
mov -0x8(%rbp),%rax 同上
mov %edx,(%rax) 将edx中值拷贝到变量x3指向的变量x中
进入refcube函数调用时,指令同指针:
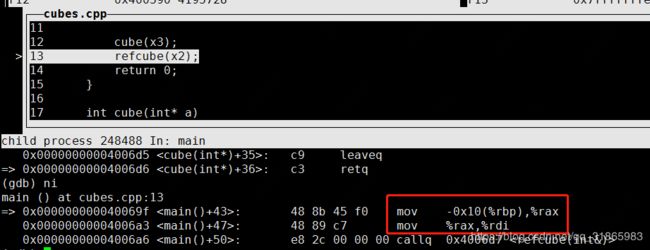
执行计算的指令也跟指针相同,如下
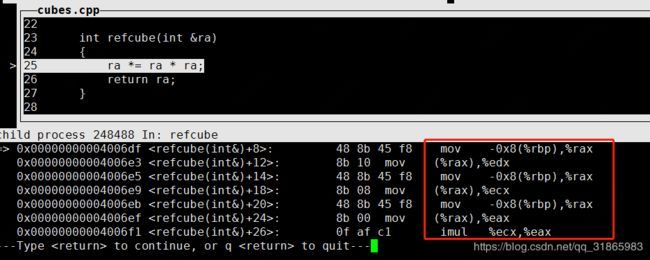
综上,从汇编上看引用变量和指针是一样的。
二、函数参数默认值
通过函数的原型声明说明某个参数的默认值,调用函数时如果未传递该参数,则编译器自动使用默认值代替,可大幅减少方法重载的数量,代码更简洁。C和Java都不支持参数默认值,Java可以通过方法重载实现,C中函数不允许同名无法实现。
#include
//通过函数原型声明函数默认值,调用函数时没有传递带默认值的形参时使用默认值
void left(const char * str, int n = 1,int m=4);
//带默认值的参数必须是最后一个参数
//void left2(const char * str, int n = 1,int m);
int main()
{
left("test");
//按顺序匹配,不能跳过
left("test",2);
// left("test",,5);
left("test",2,5);
return 0;
}
void left(const char * str, int n,int m)
{
using namespace std;
cout << str << ",n=" << n <<",m=" << m < 三、函数重载
C中不允许函数同名,C++允许函数同名,但是要求同名函数的特征标不同,定义同名但是特征标不同的多个函数就称为函数重载。函数的参数数量、参数类型和参数的顺序称为函数的特征标,注意函数的返回类型、参数名、const限定符都不属于特征标,指针类型,引用类型和对应的类型属于不同的特征标。因为调用重载函数时可能因为会匹配多个函数而报错,所以应当确保重载函数的特征标比较明显,不要滥用函数重载。
1、重载函数定义
#include
using namespace std;
int test(int a,double b){
return 0;
}
//函数定义不报错,调用test方法时因为匹配到了多个函数,所以报错'test' is ambiguous
//函数的返回值不是特征标
//double test(int a,double b){
// return 1;
//}
//函数定义报错,Invalid redefinition of 'test'
//参数名不是特征标
//int test(int a2,double b2){
// return 2;
//}
//函数定义报错,Invalid redefinition of 'test'
//const限定符不是特征标,报错Invalid redefinition of 'test'
//int test(const int a,const double b2){
// return 3;
//}
//函数定义不报错,但是部分情况下函数调用因匹配到了多个函数而报错
int test(int & a,double b){
return 4;
}
//参数的顺序是特征标
int test(double b,int a){
return 5;
}
//参数的类型是特征标
int test(int b,int a){
return 6;
}
//指针类型与原来的类型属于不同的特征标
int test(int* b,int* a){
return 6;
}
int main()
{
//'test' is ambiguous
//不会有匹配问题,因为常量表达式只适用于return 0的test,不匹配return 4的test
//有匹配问题,同时匹配return 4和return 0两个test
// int i=test(1,2);
// cout << "i=" < 2、名称修饰
为何C++中允许函数重载了?因为C++编译器结合函数的特征标按照编译器特定的算法对函数名做了名称修饰。上述代码通过g++ -S生成反汇编文件,其中main方法的汇编指令如下:
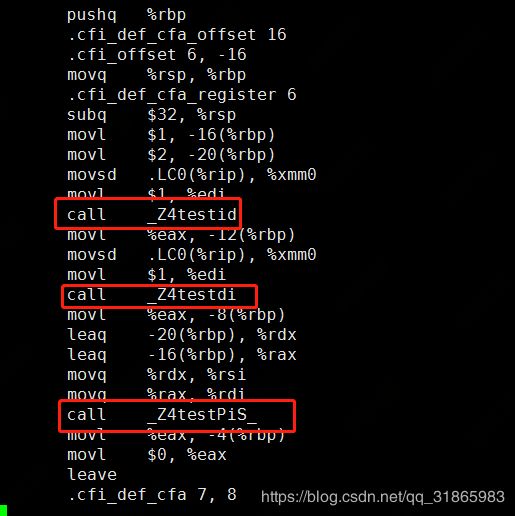
三个test方法分别生成了三个不同的名字。
四、函数模板
函数模板就是Java中的泛型方法,编译器会根据定义的函数模板和实际调用的参数类型生成该参数类型下的函数定义,编译后的二进制代码中不包含任何模板函数。生成的函数定义称为模板实例,根据实际调用的参数类型自动生成这种方式称为隐式实例化,C++同时支持显示实例化和显示具体化,注意当存在匹配参数类型的同名非模板函数或者显示具体化函数时,编译器优先使用非模板函数,且不会生成该参数类型下的函数定义。
1、函数模板定义
template表示声明一个模板,typename定义模板中用到的泛型类型名,允许有多个泛型类型名,早期使用class,与typename等价,注意每个函数模板前都需要加上template和typename,否则报错无法解析泛型类型。
#include
//template表示声明模板,typename表示T是一个数据类型名,早期使用class,与typename等价
template
void Swap(T &a, T &b);
template
void Swap(T *a, T *b, int n);
template
void Show(T a[], E b[], int n);
template
T add(T a[], int n);
const int Lim = 8;
int main() {
using namespace std;
int d1[Lim] = { 0, 7, 0, 4, 1, 7, 7, 6 };
int d2[Lim] = { 0, 7, 2, 0, 1, 9, 6, 9 };
cout << "Original arrays:\n";
Show(d1, d2, Lim);
Swap(d1, d2, Lim);
cout << "Swapped arrays:\n";
Show(d1, d2, Lim);
cout<< "add result:"<< add(d1,Lim) << endl;
int (*addp)(int a[], int n);
double (*addp2)(double a[], int n);
addp=add;
addp2=add;
//cout打印指针时,必须显示转换成const void *,因为<<操作符只对这种情况下作了重载
//两个指向同一个add,但是地址不同
cout<< "addp address:" <<(const void *)addp <<",addp2 address:" << (const void *)addp2 <
void Swap(T &a, T &b) {
T temp;
temp = a;
a = b;
b = temp;
}
template
void Swap(T a[], T b[], int n) {
T temp;
for (int i = 0; i < n; i++) {
Swap(a[i], b[i]);
}
}
template
void Show(T a[], E b[], int n) {
using namespace std;
cout << "T:";
for (int i = 0; i < n; i++) {
cout << a[i] << ",";
}
cout << endl;
cout << "E:";
for (int i = 0; i < n; i++) {
cout << b[i] << ",";
}
cout << endl;
}
template
T add(T a[], int n) {
T b = a[0];
for (int i = 1; i < n; i++) {
b += a[i];
}
return b;
} 2、具体化和显示实例化
具体化就是定义函数模板的时候指定具体的参数类型,并可以制定不同于函数模板的特定实现,效果等价于普通的非模板函数。显示实例化就是在调用模板函数时显示指定参数类型,不需要编译器去推断识别参数类型。
具体化和显示实例化的示例如下:
#include
//编译器会根据模板函数实际调用时传入的参数类型自动生成对应参数类型的函数定义,最终生成的二进制代码不包含任何模板
//生成的函数定义称为模板实例,这种根据实际参数类型生产模板实例的方式称为隐式实例化
template
void Swap(T &a, T &b);
//非模板函数
//void Swap(int & a,int & b);
//显示具体化函数,两种写法等价
template <> void Swap(int &a, int &b);
//template <> void Swap(int &a, int &b);
int main()
{
using namespace std;
//显示实例化,与显示具体化的区别在于后面没有<>,GNU不支持
// template void Swap(int &a, int &b);
int i = 10;
int j = 20;
cout << "i, j = " << i << ", " << j << ".\n";
cout << "Using compiler-generated int swapper:\n";
// Swap(i,j); // generates void Swap(int &, int &)
//第二种显示实例化
Swap(i,j);
cout << "Now i, j = " << i << ", " << j << ".\n";
double x = 24.5;
double y = 81.7;
cout << "x, y = " << x << ", " << y << ".\n";
cout << "Using compiler-generated double swapper:\n";
Swap(x,y); // generates void Swap(double &, double &)
cout << "Now x, y = " << x << ", " << y << ".\n";
return 0;
}
//同名且相同特征标的模板函数与非模板函数,优先调用非模板函数
//void Swap(int & a,int & b){
// a=1;
// b=2;
//}
//同名且相同特征标的显示具体化模板函数和模板函数,优先调用显示具体化模板函数
template <> void Swap(int &a, int &b){
a=2;
b=3;
}
//函数模板的定义
template
void Swap(T &a, T &b)
{
T temp;
temp = a;
a = b;
b = temp;
} 定义方法时应尽量确保编译器可以很快的找到唯一一个匹配的方法,既能提高代码的可读性,也能规避编译器推断匹配方法时自身复杂规则带来的潜在问题。
五、auto和decltype类型推断
1、auto 关键字
auto关键字告诉编译器,由编译器根据变量的值自动推断变量类型,使用时相当于一个普通的数据类型名如int,如果auto后跟着多个变量,且变量推断出类型不一致则编译报错,注意auto关键字只适用于变量标识符,不适用于表达式。C中auto关键字表示当前变量是一个自动存储期的变量,会覆盖外层同名的全局变量定义,跟C++中的用法完全不同。
#include
#include
using namespace std;
int main() {
//auto关键字是告诉编译器,让编译器自己去推断变量类型,程序本身不需要明确类型
auto value1 = 1;
auto value2 = 2.33;
auto value3 = 'a';
//value11 和value22推断出两种类型,int和double,编译报错
// auto value11=1,value22=2.33;
cout << "value1 的类型是 " << typeid(value1).name() << endl;
cout << "value2 的类型是 " << typeid(value2).name() << endl;
cout << "value3 的类型是 " << typeid(value3).name() << endl;
} 2、decltype关键字
decltype关键字跟auto一样也是告诉编译器,由编译器自动退款变量类型,decltype不支持根据变量值推断类型,支持对变量标识符对应变量的类型或者表达式的结果的类型推断类型,也能识别const关键字,识别指针和引用类型。注意一个变量标识符如果加上括号返回的就是改变量类型的引用类型,如果不加返回该变量类型。
#include
#include
using namespace std;
string func(){
return "Hello World!";
}
int main() {
//语法错误
// decltype value4=1;
decltype(func()) a;
int i=1,*p=&i,&r=i;
decltype(i) b;
decltype(value1+value2) c;
//变量i加引号就返回变量i所属类型的引用类型,如果未赋值报错引用未被初始化
decltype((i)) d=i;
//e是跟r一样的引用类型
decltype(r) e=i;
//f是指针类型,跟p一样
decltype(p) f;
//h是引用类型
decltype(*p) h=i;
const int i2=1;
//decltype能够识别const关键字,这里a2就是const in类型的,编译报错常量未初始化
decltype(i2) a2=2;
cout << "a 的类型是 " << typeid(a).name() << endl;
cout << "b 的类型是 " << typeid(b).name() << endl;
cout << "c 的类型是 " << typeid(c).name() << endl;
cout << "d 的类型是 " << typeid(d).name() << endl;
cout << "e 的类型是 " << typeid(e).name() << endl;
cout << "f 的类型是 " << typeid(f).name() << endl;
cout << "h 的类型是 " << typeid(h).name() << endl;
cout << "a2 的类型是 " << typeid(a2).name() << endl;
return 0;
} 3、函数模板应用
auto和decltype关键字很重要的应用场景就是函数模板,很多场景下无法确定函数的返回类型,这时就需要借助decltype了,但是decltype依赖的表达式中参数类型尚未声明,编译报错,需要跟auto配合使用。
#include
#include
using namespace std;
template
//这种情形下无法预知t1+t2结果的类型,就把类型留给编译器去推断了
//如果把decltype(t1 + t2)作为返回类型,因为这时t1,t2尚未声明报错无法解析变量
//C++制定了这种特殊语法,表示返回类型是decltype(t1 + t2)
auto compose(T1 t1, T2 t2) -> decltype(t1 + t2)
{
return t1+t2;
}
int main() {
auto a=compose(1,1.2);
auto a2=compose(1.2,1.2);
auto a3=compose(1,1);
cout << "a 的类型是 " << typeid(a).name() << endl;
cout << "a2 的类型是 " << typeid(a2).name() << endl;
cout << "a3 的类型是 " << typeid(a3).name() << endl;
return 0;
}
参考:C++ 11 学习1:类型自动推导 auto和decltype
C++11新特性— auto 和 decltype 区别和联系
C++ decltype类型说明符