原
Tensorflow下用自己的数据集对Faster RCNN进行训练和测试(二)
2018年08月21日 22:20:38 子季鹰才
阅读数:1811
对于Tensorflow版本的Faster RCNN网络,网上包括github上都有不同的源码版本,本人之前也在进行不同版本的运行测试,可以说是每个版本都有不同的错误,在解决这些错误时可谓道阻且长。而对于用自己的数据集来训练和测试Faster RCNN网络,本人在之前的博客https://blog.csdn.net/hitzijiyingcai/article/details/81808091中已经成功实验了一次,之前的那篇博客采用的是github上的此源码https://github.com/endernewton/tf-faster-rcnn。但是本人发现网上很多关于源码的解析都是基于另一个github代码:https://github.com/smallcorgi/Faster-RCNN_TF,对于此代码的demo的基本运行及可能遇到的错误,可以参看本人之前的博客:https://blog.csdn.net/hitzijiyingcai/article/details/81747148,因此,本人就打算基于此源码进行自己的数据集的训练和测试,基于此源码的过程可谓是困难重重,遇到的各个错误有时并不能完全搜到,在这里记录下整个过程。
一、运行demo
1、获取代码
git clone --recursive https:
NB:在下载了整个文件夹之后,要自己手动新建几个文件夹,否则后面会报错,一个是在根目录下新建一个output文件夹,另一个是在experiments文件夹下新建一个logs文件夹。
2、建立cyphon模块
在下载的Faster RCNN的lib目录下make
-
-
3、下载预训练模型
在这里提供一个百度云下载地址: 链接:https://pan.baidu.com/s/1zNWzMxBwQ6qVoXXvN89Peg 密码:0rtb
下载完成之后,在tools文件夹下新建一个名称为model的文件夹,把下载好的模型放进去。
4、运行demo
在Faster RCNN根目录下执行:
python ./tools/demo.py --model /share2/home/qingdong/sharedir/Faster-RCNN_TF/tools
至此,可以得到运行demo的结果,在这期间会遇到一些错误,具体可参看在文章开头提供的本人之前博客的地址中的内容。
二、下载数据并预训练
1、下载 VOCdevkit的训练验证和测试集
-
wget
http:/
/host.robots.ox.ac.uk/pascal
/VOC/voc2007/VOCtrainval_06-Nov-
2007.tar
-
wget
http:/
/host.robots.ox.ac.uk/pascal
/VOC/voc2007/VOCtest_06-Nov-
2007.tar
-
wget
http:/
/host.robots.ox.ac.uk/pascal
/VOC/voc2007/VOCdevkit_08-Jun-
2007.tar
2、解压上面下载的三个压缩包
-
tar
xvf
VOCtrainval_06-Nov-2007
.tar
-
tar
xvf
VOCtest_06-Nov-2007
.tar
-
tar
xvf
VOCdevkit_08-Jun-2007
.tar
严格按照命令解压,这样解压后的文件嵌套形式不会变。
三个压缩文件解压后文件存储在一个文件夹VOCdekit下,这个文件夹下包含VOCcode和VOC2007等文件夹,结构如下:
-
-
-
-
3、重命名
手动将下载的数据集文件夹VOCdevkit修改名字为VOCdevkit2007放入faster rcnn目录下的Data文件夹里。也可以通过以下代码实现,改名字是因为代码中是VOCdevkit2007
-
-
ln -s
$VOCdevkit VOCdevkit2007
4、下载预训练模型
此处下载的目的是将其参数作为我们训练模型的初始化参数:
下载地址:https://drive.google.com/open?id=0ByuDEGFYmWsbNVF5eExySUtMZmM或
https://www.dropbox.com/s/po2kzdhdgl4ix55/VGG_imagenet.npy?dl=0
此处为下载VGG_imagenet.npy,需要,本人也是费了点力气才下载成功,下载完成之后在faster rcnn目录下的data文件夹下新建文件夹pretrain_model,将下载好的预训练模型VGG_imagenet.npy放进去。
5、训练模型
在根目录下:
./experiments/scripts/faster_rcnn_end2end.sh gpu 0 VGG16 pascal_voc
在这里要注意,源码中的迭代次数为70000次,为了节约时间完成对源码的运行测试,可将experiments/scripts/faster_rcnn_end2end.sh文件、lib/fast_rcnn/config.py文件中的迭代次数此改为小一点数(具体格式可参看后文)。本人将其修改为了200。
NB:训练和测试模型中遇到的错误:
(1)训练完模型后会出现如下错误

这是因为tensorflow问题并没有在/output/faster_rcnn_end2end/voc_2007_trainval 中生成VGGnet_fast_rcnn_iter_70000.ckpt文件。
解决方法:
在FASTER-RCNN_TF/lib/fast_rcnn/train.py 文件中:
将saver = tf.train.Saver(max_to_keep=100)改为:
saver = tf.train.Saver(max_to_keep=100,write_version=saver_pb2.SaverDef.V1)
同时,在文件开头加上:from tensorflow.core.protobuf import saver_pb2
在这里要注意,上述修改后,再次训练时,会出现如下提示:

这是在保存迭代文件时提示V1版本过低建议使用V2,此时千万不要改为V2,否则在修改完之后会持续提示:
Waiting for ../output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fast_rcnn_iter_200.ckpt to exist...
这是没法生成ckpt文件,即使在output文件夹下可以看到生成了一些结果文件,但是没法生成ckpt文件,因此上述不要改成V2。
(2)在训练测试时出现如下错误:

这个错误真的是费了九牛二虎之力,在百度后发现根本没有切实可行的方法,最后还是使用Google解决了问题,发现在运行代码时候在lib文件夹下面执行make操作的时候需要将make.sh文件以及setup.py文件进行修改,将arch参数从sm_37改为sm_61。此处是我在服务器上的参数,在这里附上一张参考图,大家可以根据自己的电脑配置自行查找相应参数进行修改。

重新训练完成后在$Faster-RCNN_TF/output/faster_rcnn_end2end/voc_2007_trainval中生成VGGnet_fast_rcnn_iter_200.ckpt文件。
6、测试模型
在修改完上述错误之后,运行如下代码进行测试:
python ./tools/test_net.py --device gpu --device_id 0 --weights output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fast_rcnn_iter_200.ckpt --imdb voc_2007_test --cfg experiments/cfgs/faster_rcnn_end2end.yml --network VGGnet_test
测试结果:

可以看到在测试结果中出现了负值,这是完全不对的,这是由于迭代次太少的原因,因此又将迭代次数进行了修改,改为了2000,得到了如下结果:

可以看出,AP仍然非常小,但是作为测试运行代码来说,是正确的结果就可以了。
三、用自己的数据集进行训练、测试
1、制作数据集
此部分内容可以参考本人之前的博客,有详细介绍:https://blog.csdn.net/hitzijiyingcai/article/details/81636455。
制作完成之后替换掉data下的VOCdevkit2007下相应的数据即可。
2.修改代码
(1)lib/datatsets/pascal_voc.py

修改为自己的类别,由于本人的图片为png格式,因此也将图片读取格式一并修改。
(2)lib/datasets/imdb.py
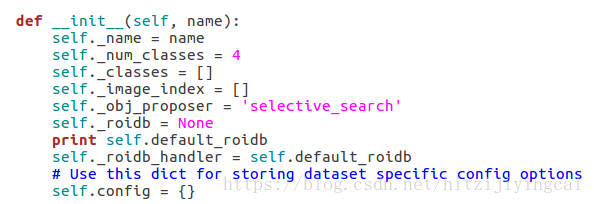
这里将num_classes改为自己的类别数+1,本人定义了3类,因此是4。
(3)lib/networks/VGGnet_train.py

将类别数改为4。同理,VGGnet_test.py修改同上
(4)tools/demo.py

为了测试demo.py的方便,所以也把tools/demo.py中的类别改成自己的类别。
(5)修改迭代次数等参数
这里大家根据自己的计算,选择合适的迭代次数以及学习率等, 个人认为,初试学习率0.001,如果不收敛再减小一个量级,另外,70000次在gpu(看自己的gpu性能,我的是1080)上跑,也只是需要半天多的时间,所以还是可以接受的迭代次数,至于选择多少迭代次数合适,可以根据不同次数训练好的模型,测试验证。此次为了测试运行代码且由前为了得到正确的结果,将迭代次数设为2000。
首先在experiments/scripts/faster_rcnn_end2end.sh文件中修改迭代次数:
 (在ITERS中修改成自己想要的参数)
(在ITERS中修改成自己想要的参数)
然后,我们进入lib/fast_rcnn/config.py,对config.py进行修改:

其中,第一项,就是学习率,STEPSIZE就是你对训练步长的修改,这里一定要小于等于前面训练文件的ITERS参数。其他大家可以选择保持一致,对于动量和伽马参数不用修改,当然,对于训练每隔多少次显示,大家根据自己情况修改,这里是10次一显示。
除此,我们可以修改batch的大小,

第一个参数是每次输入faster-rcnn网络中图片数量,第二个参数就是训练batch的大小。
关于模型保存问题:

这里,第一个参数是训练时,每迭代多少次保存一次模型;第二个参数是保存时模型的名字。
另外,大家要在训练的时候,可以将rpn检测目标设置为True:

NB:在这里需要注意的是,以上在修改每一个py文件的时候,会发现相应的文件夹中也有一个同名的pyc文件,在修改之前要将其删除。在修改完上述py文件后要进入lib文件夹重新进行make。
3、训练数据
进入你的Faster-rcnn文件夹根目录,然后直接输入:
./experiments/scripts/faster_rcnn_end2end.sh gpu 0 VGG16 pascal_voc
训练完成之后,Faster-RCNN-TF会将训练好的模型保存在output文件夹下,具体如下,这里是自己训练的一个模型 ,前面为迭代次数保存的模型,最终的模型为以2000为后缀名的:

若训练时遇到文件夹权限问题,可以参考这篇博客https://blog.csdn.net/qq_39531954/article/details/78865452。
4、测试数据
对于需要调整参数进行优化的我们来讲,我们最好对于不同迭代次数产生的模型都进行测试,能够让我们很好的找到一个合适的迭代次数。
训练完成后,会产生许多数据的计算值,并保存了下来,但是在单独测试(单独)时,我们就要将这些文件删除了,以免会产生错误,如下图:


另外,在测试前,最好进入自己数据集中的ImageSet/Main文件夹下,重新看一下自己的训练、验证、测试集编号和数量,确认没有问题。
对于测试代码可以根据tool文件夹里的test_net.py文件能够得到我们的测试语句,如下图:

这里,根据自己的情况进行修改,其中default中的值就是默认值,如果你在测试时,在终端输入时对这部分不赋值,那么就会按照default中默认值进行赋值。如果你想压缩在终端时的赋值语句,就完全可以把这部分的default值全部按照自己要输入的值修改好。
本次使用的语句为:
python ./tools/test_net.py
这里,采用gpu,weights就是我们训练好的模型位置。cfg就选择你测试的方式,这里使用的就是端到端的方式,即由输入直接得到结果。networks就是你使用的网络结构,当然,如果你有自己的网络结构,可以使用自己的,只是自己需要重新修改定义。
最后,可以运行demo看看实际框出的效果图:
python ./tools/demo.py --model output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fast_rcnn_iter_2000.ckpt

在这里附上效果较好的一张图片,可以看出,本次是定义了三类且迭代了2000次,跟源码当中迭代70000此相比效果虽没那么好,但是对于迭代2000次来说,已经能够达到一定的效果,后续会增加次数相信会有更好的结果。
本文为博主原创,转载请注明出处:https://blog.csdn.net/hitzijiyingcai/article/details/81914200
})()
“股市三板斧”坚持只看1指标 赢数千万身家! 中资 · 顶新

这样的错误!还请解答一下(2个月前#3楼)举报回复
python ./tools/test_net.py --device gpu --device_id 0 --weights output/faster_rcnn_end2end/voc_2007_trainval/VGGnet_fast_rcnn_iter_200.ckpt --imdb voc_2007_test --cfg experiments/cfgs/faster_rcnn_end2end.yml --network VGGnet_test
出现了
UnknownError (see above for traceback): exceptions.NameError: global name ‘gpu_nms’ is not defined
Traceback (most recent call last):
File “/usr/local/lib/python2.7/dist-packages/tensorflow/python/ops/script_ops.py”, line 206, in call
ret = func(*args)
File “/root/faster_rcnn1/Faster-RCNN_TF-master/tools/…/lib/rpn_msr/proposal_layer_tf.py”, line 127, in proposal_layer
keep = nms(np.hstack((proposals, scores)), nms_thresh)
File “/root/faster_rcnn1/Faster-RCNN_TF-master/tools/…/lib/fast_rcnn/nms_wrapper.py”, line 19, in nms
return gpu_nms(dets, thresh, device_id=cfg.GPU_ID)
NameError: global name ‘gpu_nms’ is not defined
[[Node: PyFunc = PyFunc[Tin=[DT_FLOAT, DT_FLOAT, DT_FLOAT, DT_STRING, DT_INT32, DT_INT32], Tout=[DT_FLOAT], token=“pyfunc_0”, _device="/job:localhost/replica:0/task:0/device:CPU:0"](rpn_cls_prob_reshape/_95, rpn_bbox_pred/rpn_bbox_pred-0-1-TransposeNCHWToNHWC-LayoutOptimizer/_97, _arg_Placeholder_1_0_1, PyFunc/input_3, PyFunc/input_4, PyFunc/input_5)]](3个月前#2楼)查看回复(1)举报回复
bash make.sh
make.sh: line 14: nvcc: command not found
g++: error: roi_pooling_op.cu.o: No such file or directory这个错误怎么办呀 (3个月前 #1楼) 查看回复(1)举报回复
windows下使用自己制作的数据集训练faster-rcnn(tensorflow版)用于目标检测
01-10 阅读数 4593
步骤一下载配置windows下tensorflow版faster-rcnn,参考博客:windows10下运行tensorflow版的faster-Rcnn步骤二制作自己的数据集参考博客:http:/... 博文 来自: 把岁月化成歌 留在博客