深入理解spark的工作机制,spark任务提交和执行流程
spark的工作机制:
用户在client端提交作业后,会由Driver运行main方法并创建spark context上下文。 SparkContext向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动StandaloneExecutorbackend, Executor向SparkContext申请Task。SparkContext将应用程序分发给Executor,SparkContext构建成DAG有向无环图,将DAG有向无环图分解成Stage、将Taskset发送给Task Scheduler,最后由TaskScheduler将Task发送给Executor运行,Task在Executor上运行,运行完释放所有资源
spark中的核心组件:
Driver:spark驱动节点,负责实际代码的执行。
Driver在spark作业执行主要负责:
1.将用户程序转化为job
2.在Executor之间调度任务(task)
3.跟踪Executor的执行情况
4.通过ui界面可以查询运行情况
Executor:executor是一个jvm进程,负责spark作业中执行具体的任务,spark启动时,executor节点被同时启动,如何当前executor节点发生故障,spark应用(Application)也可以继续执行,会将出错节点的任务调度到其他executor节点执行。
Executor在spark作业执行中的核心功能:
1.负责运行组成spark应用的任务,将结果返回给Driver
2.通过自身的Block Manager为用户程序缓存RDD,这样任务可以在运行时充分利用缓存数据来加速计算
spark运行模式:
spark的运行模式是哪一种取决于传递给sparkContext的master的值
| master URL | 解释 |
| local | 本地运行,只有一个工作进程,无并行计算 |
| local(n) | 本地运行,有N个工作进程 |
| local(*) | 本地运行,工作进程数等于该机器的CPU核心数 |
| spark://host:port | standalone模式运行,这是spark自带的运行模式,默认作业提交端口号为:7077 |
| yarn-client | yarn集群运行,Driver进程在本地,work进程在yarn集群 |
| yarn-cluster | 在yarn集群运行,Driver进程在yarn集群上,worke进程也在yarn集群上 |
用户在提交任务给spark处理的时候,由以下两个参数共同决定了spark的运行方式
--master MASTER_URL:决定spark任务提交给那种集群处理
--deploy-mode DEPLOY_MODE:Driver以何种方式运行,client还是cluster
spark作业提交方式和执行流程:
第一种:基于standalone-client提交任务

在Standalone Client模式下,Driver在任务提交的本地机器上运行,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源,至少可以启动一个Executor的Worker,然后这些worker之间分配Executor.Worker上的Executor启动后会向Driver反向注册,所有的Executor注册完成之后,Driver开始执行main函数,之后执行到Action算子,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
第二种:standalone Cluster模式

在standalone cluster模式下,任务提交后,master会找到一个worker启动Driver进程,Driver启动后向Master注册应用程序,Master根据submit脚本的资源需求找到内部资源,至少可以启动一个Executor的Worker,然后这些worker之间分配Worker上的Executor。Executor启动后会向Driver反向注册,所有的Executor注册完成之后,Driver开始执行main函数,之后执行到Action算子,开始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行。
第三种:yarn Cluster模式
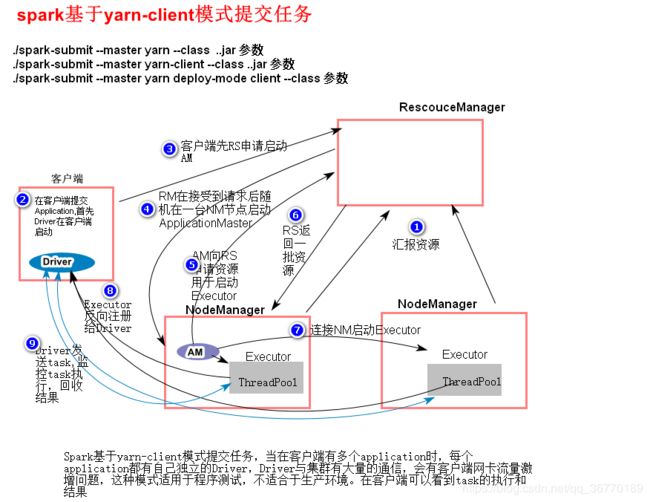
在yarn client模式下,Driver在任务提交的本地机器上运行,Driver启动后会向ResourceManager申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存。
ResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Exectutor进程启动会会向Driver反向注册,Executor全部注册完成后,Driver开始执行main,之后执行到Action算子,触发一个job,并根据宽窄依赖划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。
第四种:yarn cluster模式
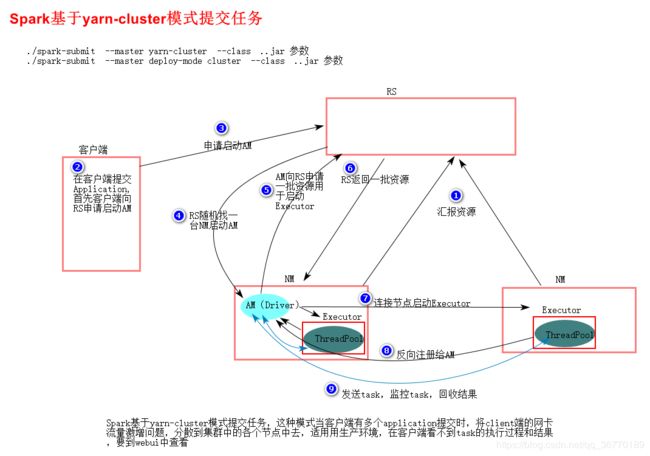
在yarn cluster模式下,客户端会向ResourceManager申请启动ApplicationMaster,随后ResourceManager分配container,在合适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的就是Driver。
Driver启动后向ResourceManage申请资源。rResourceManager接到ApplicationMaster的资源申请后会分配container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程,Exectutor进程启动会会向Driver反向注册,Executor全部注册完成后,Driver开始执行main,之后执行到Action算子,触发一个job,并根据宽窄依赖划分stage,每个stage生成对应的TaskSet,之后将task分发到各个Executor上执行。