Spark项目的创建&Spark-shell用法
Spark 2.2.0 is built and distributed to work with Scala 2.11 by default. (Spark can be built to work with other versions of Scala, too.) To write applications in Scala, you will need to use a compatible Scala version (e.g. 2.11.X).
如何创建一个Spark项目:
To write a Spark application, you need to add a Maven dependency on Spark. Spark is available through Maven Central at:
org.apache.spark
spark-core_2.11
2.2.0
Finally, you need to import some Spark classes into your program. Add the following lines:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConfSpark项目(IDEA):The appName parameter is a name for your application to show on the cluster UI. master is a Spark, Mesos or YARN cluster URL, or a special “local” string to run in local mode. In practice, when running on a cluster, you will not want to hardcode master in the program, but rather launch the application with spark-submit and receive it there. However, for local testing and unit tests, you can pass “local” to run Spark in-process.
package com.ruozedata.spark
import org.apache.spark.{SparkConf, SparkContext}
object SparkContextApp {
def main(args: Array[String]): Unit = { //不要这么写,用推荐方法
val sparkConf=new SparkConf().setAppName("SparkContextApp").setMaster("local[2]")
val sc=new SparkContext(sparkConf)
//项目需求
sc.stop()
}
}
local模式用法:![]()
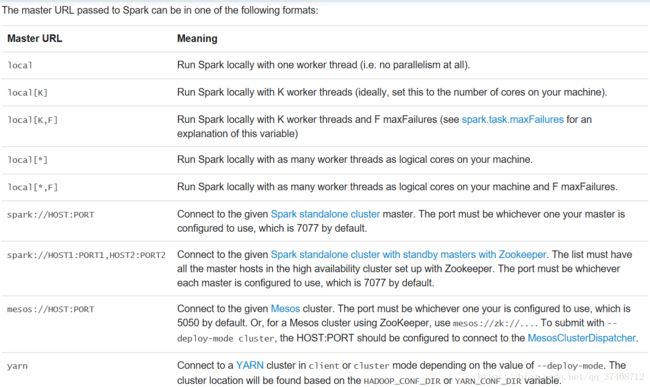
HADOOP_CONF_DIR,YARN_CONF_DIR所指的目录:![]()
Spark-shell:通过--help了解命令
Usage: ./bin/spark-shell [options]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of local jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Spark standalone with cluster deploy mode only:
--driver-cores NUM Cores for driver (Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone and Mesos only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone and YARN only:
--executor-cores NUM Number of cores per executor. (Default: 1 in YARN mode,
or all available cores on the worker in standalone mode)
YARN-only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
--principal PRINCIPAL Principal to be used to login to KDC, while running on
secure HDFS.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above. This keytab will be copied to
the node running the Application Master via the Secure
Distributed Cache, for renewing the login tickets and the
delegation tokens periodically.Spark-shell用法:In the Spark shell, a special interpreter-aware SparkContext is already created for you, in the variable called sc. Making your own SparkContext will not work. You can set which master the context connects to using the --master argument, and you can add JARs to the classpath by passing a comma-separated list to the --jars argument. You can also add dependencies (e.g. Spark Packages) to your shell session by supplying a comma-separated list of Maven coordinates to the --packages argument. Any additional repositories where dependencies might exist (e.g. Sonatype) can be passed to the --repositories argument. For example, to run bin/spark-shell on exactly four cores, use: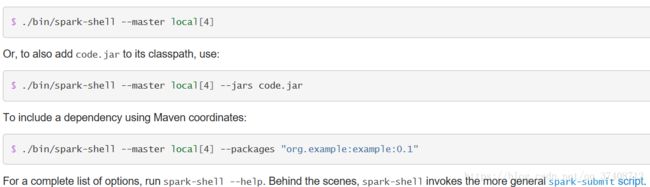
打开spark后可进入4040端口查看详情