Seaborn第三方绘图
Seaborn第三方绘图
关系型绘图
Seaborn介绍
Seaborn是一个基于matplotlib且数据结构与pandas统一的统计图制作库。他提前已经定义好了一套自己的风格。然后也封装了一系列的方便的绘图函数,之前通过matplotlib需要很大代码才能完成绘图,使用seaborn可能是一行代码的事情。
Seaborn是基于matplotlib的Python数据可视化库。它提供了用于绘制引人入胜且内容丰富的统计图形的高级界面。
Seaborn的绘图
- 关系型绘图
- 分类型绘图
- 分布型绘图
- 线性绘图
Seaborn安装
pip install seaborn
学习文档
- 官网 :http://seaborn.pydata.org/
- 中文学习文档 :https://www.cntofu.com/book/172/docs/1.md
- 数据集地址 :https://github.com/mwaskom/seaborn-data
关系型绘图
这个函数功能非常强大,可以用来表示多个变量之间的关联关系。默认情况下是绘制散点图,也可以绘制线性图,具体绘制什么图形是通过seaborn.relplot(kind=None)里面的kind参数来决定的。实际上以下两个函数就是relplot的特征:
- 散点类型 :scatterplot - relplot(kind=“scatter”)
- 线性类型 : lineplot - relplot(kind=“line”)
seaborn.relplot(x=None,y=None,data=None,hue=None,col=None, row=None,kind=None,style=None)
- x : 为x轴的数据
- y : 为y轴的数据
- data : 为数据集,当传入了x,y之后还需要传入data数据
- hue : 将该数据进行分组并展示不同的颜色,并会自动添加上图例
- col,row : 为列名,则根据列的类别展示数据(该列的值有多少种,则将图以多少列显示)
- kind : 为设置绘制的图形
- style : 为指定样式
# sns 为网上固定的写法,按照官网的标准
# seaborn 是基于matplotlib的封装
import seaborn as sns
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
# 读取csv文件
df = pd.read_csv('seaborn-data-master/tips.csv')
# relplot 默认情况下绘制散点图
sns.relplot(x='total_bill',y='tip',data=df,hue='day',col='time',row='sex')
# 为什么可以使用plt.show来释放,因为seaborn也是基于matplotlib来实现
plt.show()

散点图
sns.scatterplot(x=None,y=None,hue=None,data=None)
- x : 为x轴数据
- y : 为y轴数据
- hue : 将数据进行不同颜色的分组
- data : 传入的数据集
import seaborn as sns
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
df = pd.read_csv('seaborn-data-master/tips.csv')
sns.scatterplot(x='total_bill',y='tip',data=df,hue='day')
plt.show()

折线图
绘制折线图方法一
import seaborn as sns
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np
df = pd.read_csv('seaborn-data-master/fmri.csv')
# kind 为指定绘制的图形
sns.relplot(x='timepoint', y='signal',data=df,kind='line',hue='region')
plt.show()

- 指定参数
col = event

绘制折线图的方法二
import seaborn as sns
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv('seaborn-data-master/fmri.csv')
sns.lineplot(x='timepoint', y='signal',data=df,hue='region',style='event')
# 展示图例
plt.show()
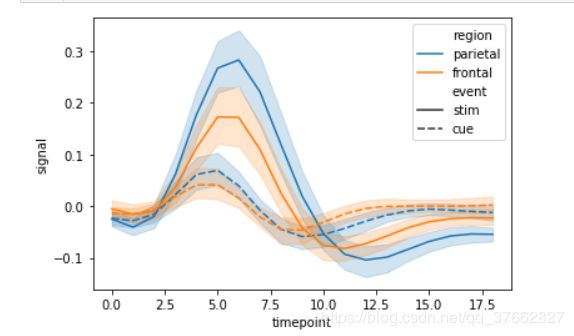
relplot 与 lineplot或scatterplot 的区别
- 无kind参数
- 无col参数
分类绘制
分类图的绘制,采用的是sns.catplot来实现的。cat是categroy的简写。这个方法默认绘制的分类散点图,如果想要绘制其他类型的图,同样也是可以通过kind参数来指定。
图形的分类
- 分类散点图
- 分类分布图
- 分类统计图
seaborn.replot 与 seaborn.catplot
seaborn.replot
- 用于将关系图绘制到FacetGrid上的图形级界面。
- 此功能提供对几个不同轴级功能的访问,这些功能通过子集的语义映射显示两个变量之间的关系。该
kind参数选择要使用的基础轴级功能:scatterplot()(带有kind="scatter";默认值)lineplot()(带有kind=line)
seaborm.catplot
-
seaborn.catplot 是一个将分类图绘制到FacetGrid上图级别接口。
-
这个函数可以访问多个轴级功能,这些轴级功能通过不同的可视化图表展示数字和一个或多个分类变量的关系。
kind参数可以选择的轴级基础函数有:分类散点图
stripplot()(带有kind="strip";默认值)swarmplot()(带有kind="swarm")
分类分布图
boxplot()(带有kind="box")violineplot()(带有kind="violin")boxenplt()(带有kind="boxen")
分类估计图
pointplot()(带有kind="point")barplot()(带有kind="bar")countplot()(带有kind="count")
分类图的绘制
sns.catplot(x=None,y=None,data=None,row=None,col=None,kind=‘strip’)
- x : 为x轴数据
- y : 为y轴数据
- data : 数据集
- row,col : data中的变量,分类变量将决定网格的分面
- kind : 默认为strip分类散点图 (选项包括:“点”,“条形”,“条形”,“群”,“框”,“小提琴”或“盒子”)。
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
df = pd.read_csv('seaborn-data-master/tips.csv')
# 日期 与 total_bill 之间的关系
sns.catplot(x='day',y='total_bill',data=df,hue='sex')
分类散点图
sns.stripplot(x=None,y=None,data=None,hue=None)
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
df = pd.read_csv('seaborn-data-master/tips.csv')
sns.catplot(x='day',y='total_bill',data=df,hue='sex')

分簇散点图
sns.swarpmply(x=None,y=None,hue=None,data=None)
sns.swarmplot(x='day',y='total_bill',data=df,hue='sex')
plt.show()

分类分布图
分类分布图,主要是根据分类来看,然后再每个分类下数据的分布情况。也是通过catplot来实现,以下三个方法分别是不同的kind参数
- 箱型图 :boxplot() (with kind=“box”)
- 小提琴图 : violinplot() (with kind=“violin”)
箱型图
boxplot(x=None,y=None,data=None, palette=None,hue=None)
- x,y : DataFrame中的列名
- data : DataFrame的数据
- palette : 调色板
- hue : DataFrame的列名,按照列名中的值分类的条形图
import seaborn as sns
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv('athlete_events.csv')
countries = {
'CHN':'中国',
'JPN':'日本',
'KOR':'日本',
'USA':'美国',
'CAN':'加拿大',
'BRA':'巴西',
'GBR':'英国',
'FRA':'法国',
'ITA':'意大利',
'ETH':'埃塞俄比亚',
'KEN':'肯尼亚',
'NIG':'尼日利亚'
}
# 判断在countries国家的数据
# 判断国家在countries中则选择出来
# isin判断值是否在countries当中
# 布尔索引筛选出数据
my_ath = df[df['NOC'].isin(list(countries.keys()))]
# 绘制箱型图
plt.figure(figsize=(16,8))
sns.boxplot(x='NOC',y='Height',data=my_ath)
plt.show()

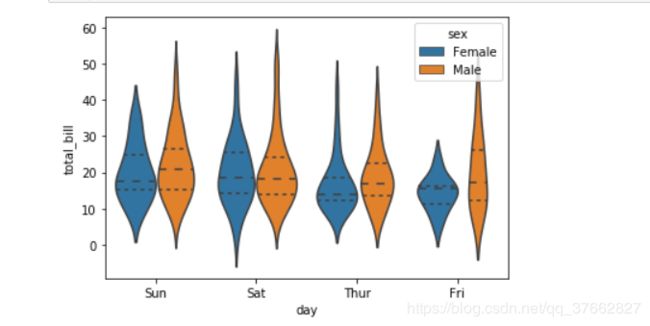
小提琴图
violinplot(x=None,y=None,data=None,inner=None)
- x,y : DataFrame中的列名
- data : DataFrame的数据
- inner : 参数选择{“box”, “quartile”, “point”, “stick”, None}
- inner : 控制小提琴图内部数据点的表示。若为
box,则绘制一个微型箱型图。若为quartiles,则显示四分位数线。若为point或stick,则显示具体数据点或数据线。使用None则绘制不加修饰的小提琴图。
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
# 读取数据
tips = pd.read_csv('seaborn-data-master/tips.csv')
# 绘制小提琴图
# 中间 默认箱型图 inner-->quartile 四分位数
sns.violinplot(x='day',y='total_bill',inner="quartile",data=tips,hue='sex')
plt.show()
分类统计图
分类统计图,则是根据分类,统计每个分类下的数据的个数或者比例。
- 条形图 :
barplot() (with kind="bar") - 柱状图 :
countplot() (with kind="count") - 点线图 :
pointplot() (with kind="point")
将点估计和置信区间显示为矩形条
seaborn中的条线图具有统计功能,可以统计出比例,平均数,也可以按照你想要的统计函数来统计。
import seaborn as sns
import pandas as pd
import numpy as np
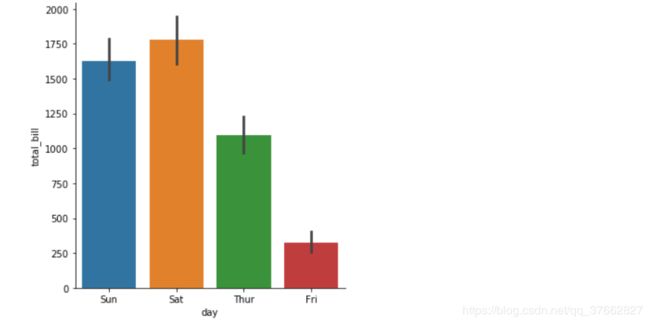
# 直观体现 total_bill 与 day 的统计平均数
tips = pd.read_csv('seaborn-data-master/tips.csv')
tips.head()
# 黑线 置信区间 线条越高 说明数据是比较离散的
# 默认情况下是采用平均数来进行
# estimator : 默认情况下采用平均数,我们可以指定为sum来查看数值
sns.catplot(x='day',y='total_bill',data=tips,kind='bar',estimator=sum)
plt.show()

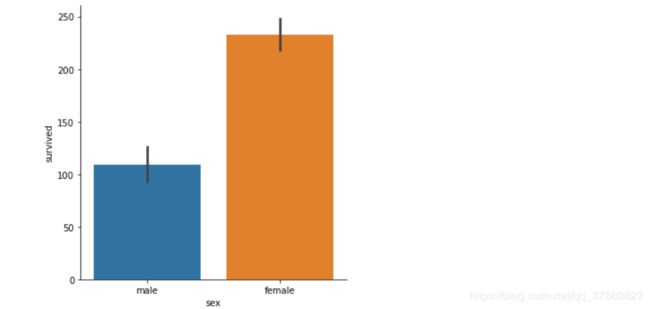
分析泰坦尼克号获救的男女比例
titanic = pd.read_csv('seaborn-data-master/titanic.csv')
titanic.head()
# 绘制直方图查看数据
# survived : 代表着获救的人数
# 可通过estimator来指定人数
sns.catplot(x='sex',y='survived',data=titanic,kind='bar',estimator=sum)
plt.show()
使用条形图显示每个分类箱中的观测值
titanic.head()
# count :代表为单个分类中显示值的个数
# kind = 'count' :
# 当为count的时候,只能指定x或y单个值
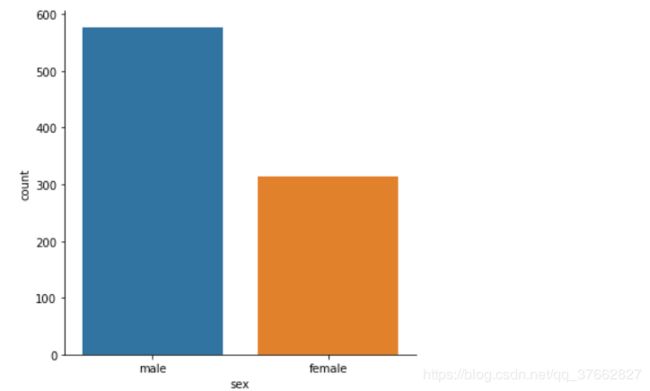
sns.catplot(x='sex',data=titanic,kind='count')
使用散点图字形显示点估计和置信区间
# 舱为 与 营救男女获救关系
# hue分组
# class 为舱位
sns.catplot(x='sex',y='survived',data=titanic,kind='point',hue='class')

分布绘图
分布绘图主要分为单变量分布以及二变量分布和pairplot
单变量分布
单一变量主要就是通过直方图来绘制。在seaborn中直方图的绘制采用的是distplot,其中dist是distribution的简写,不是histogram的简写。
seaborn.distplot(a,bins=None,kde=True,hist=True,rug=False)
- a : Series 、一维数组或者列表
- bins : (参数值)直方图bins(柱)的数目,若填None,则默认使用Freedman-Diaconis规则指定柱的数目
- hist : (布尔值)是否绘制标准化直方图
- kde : (布尔值)是否绘制核密度线
- rug : (布尔值) 是否在横线上绘制观测值竖线
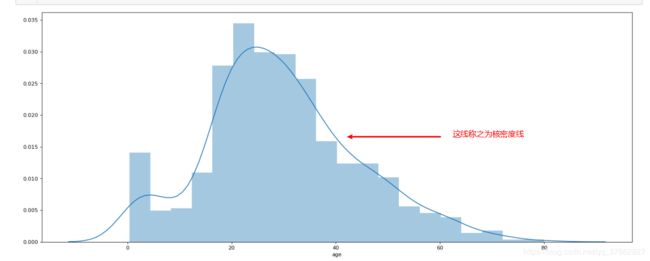
# 传入一维的数组
plt.figure(figsize=(20,8),dpi=80)
sns.distplot(titanic['age'])
plt.show()
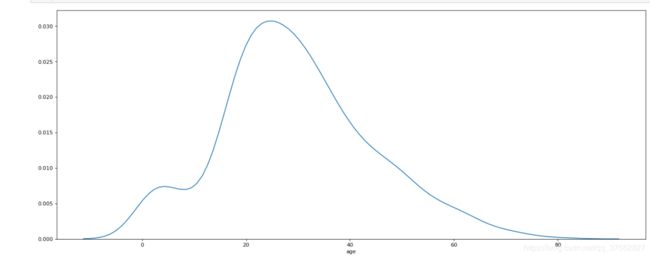
# 传入一维的数组
plt.figure(figsize=(20,8),dpi=80)
# 当不绘制直方图时,指定hits
# 当绘制直方图,不绘制高密度曲线时 ,指定kde
sns.distplot(titanic['age'],bins=30,hist=False)
plt.show()
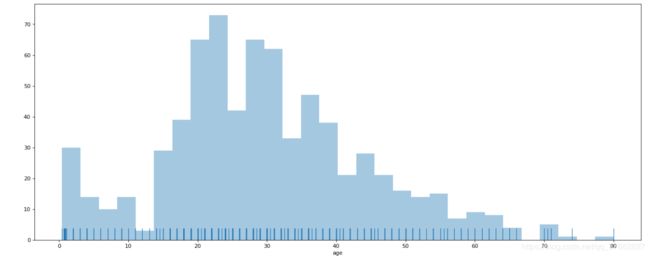
# 传入一维的数组
plt.figure(figsize=(20,8),dpi=80)
# 当不绘制直方图时,指定hits
# 当绘制直方图,不绘制高密度曲线时 ,指定kde
sns.distplot(titanic['age'],bins=30,hist=True,kde=False)
plt.show()

# 传入一维的数组
plt.figure(figsize=(20,8),dpi=80)
# 当不绘制直方图时,指定hits
# 当绘制直方图,不绘制高密度曲线时 ,指定kde
sns.distplot(titanic['age'],bins=30,hist=True,kde=False,rug=True)
plt.show()
二变量分布
多变量分布图可以看出两个变量之间的分布关系。一般都是采用多个图进行表示。多变量分布图采用的函数是jointplot。
seaborn.jointplot(x,y,data=None,kind=‘scatter’, color=None,height=5,ratio=5,space=0.2,dropna=True)
- x,y,data : 绘制图的数据
- kind :
scatter、reg、resid、kde、hex - color : 绘制元素的颜色
- height : 图的大小,图会是一个正方形
- ratio : 主图和副图的比例,只能为一个整型
- space : 主图与副图的间距。
- dropna : 是否需要删除x或者y值出现了nan的值
# 多变量绘图
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
# 读取数据
tips =pd.read_csv('seaborn-data-master/tips.csv')
sns.jointplot(x='total_bill',y='tip',data=tips,height=6)

添加回归和核密度拟合
sns.jointplot(x='total_bill',y='tip',data=tips,height=6,kind='reg')
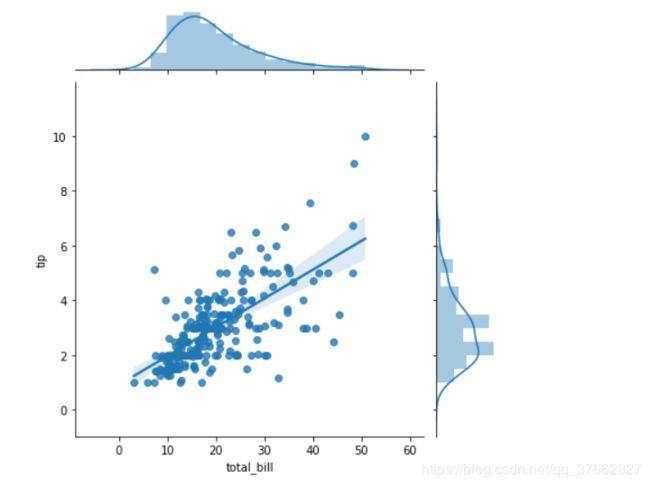
使用六边形箱将散点图替换为联合直方图
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
ath_data = pd.read_csv('athlete_events.csv')
# 筛选出NOC为中国数据进行比较身高数据
ath_china = ath_data[ath_data['NOC']=='CHN']
# grisize : 指定六边形的大小
# 数据对比 :中国的体重和身高集中图
sns.jointplot(x='Height',y='Weight',data=ath_china,kind='hex',gridsize=20,height=7)

# grisize : 指定六边形的大小
# 数据对比 :中国的体重和身高集中图
# kind='hex':代表为六边形
# gridsize : 为六边形的大小
# height : 图片大小
# color : 为颜色
# ration : 为子图的大小
# marginal_kws : 绘图组件的其他参数位置
# rug : rug越密集显示的数据越多
# kde : 核密度曲线
sns.jointplot(x='Height',y='Weight',data=ath_china,kind='hex',gridsize=20,height=7,color='r',ratio=2,marginal_kws={'rug':True,'kde':True})

在数据集中绘制成对关系
seaborn.pairplot(data,hue=None,vars=None)
- data : 数据
- hue : 字符串变量名
- vars : 变量名列表
默认情况下,此函数将创建一个轴网格,以便每个变量在data单行的y轴和单列的x轴上共享。对角轴的处理方式有所不同,绘制了一个图以显示该列中变量的数据的单变量分布。
也可以显示变量的子集或行和列上绘制不同的变量
import pandas as pd
import numpy as np
import seaborn as sns
# 读取画的数据
iris = pd.read_csv('seaborn-data-master/iris.csv')
iris.head()
# 绘制成对关系图
sns.pairplot(iris)

当指定数据集
sns.pairplot(vars=['sepal_length','sepal_width'],data=iris)

对单变量使用核密度估计
sns.pairplot(vars=['sepal_length','sepal_width'],data=iris,diag_kind='kde')
