Tensorflow 笔记 XIV——生成时对抗网络:GAN 与 CGAN
文章目录
- 一、引言
- 深度学习模型
- 二、生成式模型
- 研究意义
- 常用方法
- 生成式对抗网络
- 应用
- 生成方法
- 生成原理
- GAN的训练
- GAN模型结构
- 生成器模型
- 判别器模型
- 三、数据集
- 四、GANTensorFLow 2.x 高阶 API Keras实现
- 导入必要的包
- 读取数据
- 生成器模型定义
- 判别器模型定义
- 训练设置
- 判别器损失函数
- 生成器损失函数
- 两者优化器
- 定义超参数
- 产生随机种子
- 定义单次训练过程
- 生成和保存图片
- 训练函数定义
- 可视化
- 显示单张图
- 定义动图函数
- 五、CGANTensorFLow 2.x 高阶 API Keras实现
- 导入必要的包
- 数据读取
- 生成器模型定义
- 判别器模型定义
- 训练设置
- 判别器损失函数
- 生成器损失函数
- 两者优化器
- 定义超参数
- 产生随机种子
- 定义单次训练过程
- 生成和保存图片
- 训练函数定义
- 可视化
- 显示单张图
- 定义动图函数
- 六、GAN and CGANTensorFLow 1.x 低阶 API实现
- 特别说明
- 黑胡桃社区
- 函数文件
- notebook示例
- 七、总结
一、引言
深度学习模型
深度学习模型可分为如下两类:判别式模型,生成式模型
| 判别式模型 | 生成式模型 |
|---|---|
| 通过模型进行分类预测,例如图像分类,目标检测,电影情感分析等 | 通过模型生成数据,例如图像数据,声音数据等 |
| GoogLeNet | GAN |
| ResNet | CGAN |
| Faster RCNN | DCGAN |
| YOLO | intoGAN |
| … | … |
| VGG系列 | WGAN |
二、生成式模型

研究意义
➢是对我们处理高维数据和复杂概率分布的能力很好的检测
➢当面临缺乏数据或缺失数据时,我们可以通过生成模型来补足。比如,用在半监督学习中。
➢可以输出多模态(multimodal)结果
➢等等
常用方法
➢最大似然估计法:以真实样本进行最大似然估计,参数更新直接来自于样本数据,导致学习到的生成模型受到限制。
➢近似法:由于目标函数难解一般只能在学习过程中逼近目标函数的下界,并不是对目标函数的逼近。
➢马尔科夫链方法:计算复杂度高
生成式对抗网络
应用




生成方法
➢设数据集 x 1 x_1 x1, … \ldots …, x n x_n xn作为真实数据分布的样本 p ( x ) p(x) p(x),其分布如下图蓝色区域所示(这个分布函数是通过设定阈值所达到的高概率分布),其中黑色小点代表样本点 x x x
➢其中粉色区域代表单位高斯噪声
➢黄色区域是我们的生成式模型
➢绿色区域是服从数据描述为 p ^ θ ( x ) \hat{p}_{\theta}(x) p^θ(x)的分布域,这个分布区域则是粉色区域(随机高斯噪声)通过黄色区域(生成式模型)映射而来
➢我们的目的则是通过调整参数 θ \theta θ来修正生成式模型,使得通过生成式模型映射绿色区域无限逼近蓝色区域,使两者的分布函数逐渐相等,即 lim θ → θ n p ( x ) = p ^ θ ( x ) \mathop {\lim }\limits_{\theta \to {\theta _n}}p(x)=\hat{p}_{\theta}(x) θ→θnlimp(x)=p^θ(x),其中 θ n {\theta _n} θn为理想值
生成原理
原理可由下图简单描述,其中输入的数据为随机噪声或高斯噪声等:

是一个三维噪声的三维高斯图【图对不对我也不知道,因为我懒得化,随便在网上找了一个噪声的matlab图,手动滑稽】
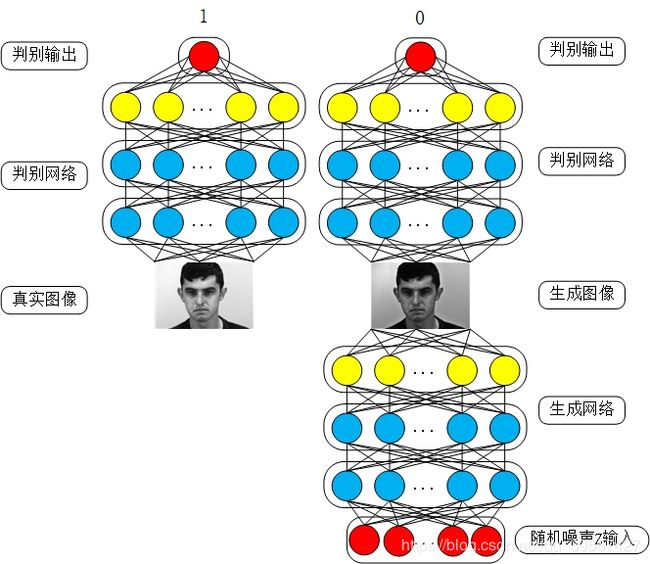
从原理的示意图种可以看出,随机输入的噪声通过生成网络生成一张图,然后将生成的图像送入判别网络,判别网络再判别图像是真实图像还是生成图像,其输出则是判别的结果,对于生成图,判别网络试图输出0,对于真实图判别网络试图输出1,而生成网络则是不断优化自己将生成的图让判别网络能够输出1,而判别网络则是不断优化自己让自己能够区分生成图与判别图。
简单来说,生成网络与判别网络之间存在一个军备竞赛,生成网络不断提高生成能力(造假能力),判别网络不断提高鉴别能力(识别真假)
GAN的核心思想来源于博弈论的纳什均衡,它设定参与游戏双方分别为一个生成器和一个判别器,生成器的目的是尽量去学习真实的数据分布,而判别器的目的是尽量正确判别输入数据是来自真实数据还是来自生成器;为了取得游戏胜利,两个参与者需要不断优化,各自提高自己的生成能力和判别能力,这个学习的优化过程就是寻找二者之间的一个纳什均衡。
GAN的训练
➢在给定生成器 G G G,优化判别器 D D D
O b j D = − 1 2 E x − p d a t a ( x ) [ log D ( x ) ] − 1 2 E z − p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] Ob{j^D} = - \frac{1}{2}{E_{x-{p_{data}}(x)}}[\log D(x)] - \frac{1}{2}{E_{z-{p_z}(z)}}[\log (1 - D(G(z)))] ObjD=−21Ex−pdata(x)[logD(x)]−21Ez−pz(z)[log(1−D(G(z)))]
其中 x x x采样于真实数据分布 p d a t a ( x ) {p_{data}}(x) pdata(x), z z z采样于先验分布 p z ( z ) {p_z}(z) pz(z)(例如高斯噪声)。在连续空间上式可写成:
O b j D = − 1 2 ∫ x p d a t a ( x ) log ( D ( x ) ) d x − 1 2 ∫ z p z ( z ) log ( 1 − D ( g ( z ) ) ) d z = − 1 2 ∫ x [ p d a t a ( x ) log ( D ( x ) ) d x + p g ( x ) log ( 1 − D ( x ) ) ] d x Ob{j^D} = - \frac{1}{2}\int_x {{p_{data}}(x)\log (D(x))dx - } \frac{1}{2}\int_z {{p_z}(z)\log (1 - D(g(z)))dz}=-\frac{1}{2}\int_x {[{p_{data}}(x)\log (D(x))dx + {p_g}(x)\log (1 - D(x))]dx} ObjD=−21∫xpdata(x)log(D(x))dx−21∫zpz(z)log(1−D(g(z)))dz=−21∫x[pdata(x)log(D(x))dx+pg(x)log(1−D(x))]dx
上式在 D G ∗ ( x ) = p d a t a ( x ) p d a t a ( x ) + p g ( x ) D_G^*(x) = \frac{{{p_{data}}(x)}}{{{p_{data}}(x) + {p_g}(x)}} DG∗(x)=pdata(x)+pg(x)pdata(x)处取得最小值,此即为判别器的最优解。由此可知,GAN估计的是两个概率分布密度的比值,这也是和其它基于下界优化或者马尔科夫链方法的关键不同之处。
➢生成器 G G G的损失函数: O b j G = − O b j D Ob{j^G}=-Ob{j^D} ObjG=−ObjD
➢所以,GAN的优化问题是一个极小-极大化问题,GAN的目标函数:
min G max D V ( D , G ) = E x − p d a t a ( x ) [ log D ( x ) ] + E z − p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \mathop {\min }\limits_G \mathop {\max }\limits_D V(D,G) = {E_{x-{p_{data}}(x)}}[\log D(x)] + {E_{z-{p_z}(z)}}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex−pdata(x)[logD(x)]+Ez−pz(z)[log(1−D(G(z)))]
➢采用交替优化的方法:
先固定生成器G,优化判别器D,使得D的判别准确率最大化;然后固定判别器D,优化生成器G,使得判别准确率最小化。
➢当且仅当 p d a t a = p g p_data=p_g pdata=pg时,达到全局最优。
GAN模型结构
生成器模型
判别器模型

判别器可以视作一个CNN分类器,将输入的图像数据进行卷积后输出预测值,判别器的目的是尽量正确判别输入数据是真实数据还是来自生成器!
三、数据集
Fashion-MNIST数据集描述与其他信息参见 Fashion-MNIST,在此篇Tensorflow 笔记 ⅩⅢ——“百无聊赖”:深挖 mnist 数据集与 fashion-mnist 数据集的读取原理,经典数据的读取你真的懂了吗?中详细讲解了Fashion-MNIST与MNIST数据集的几种读取方式,这里就不再赘述

Fashion-MNIST是一个替代MNIST手写数字集的图像数据集。 它是由Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自10种类别的共7万个不同商品的正面图片。Fashion-MNIST的大小、格式和训练集/测试集划分与原始的MNIST完全一致。60000/10000的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。
这个数据集的样子大致如上图,embeding 动图在此
四、GANTensorFLow 2.x 高阶 API Keras实现
导入必要的包
import tensorflow as tf
print('TensorFlow Version', tf.__version__)
print('GPU is ', 'available.' if tf.test.is_gpu_available() else 'NOT AVAILABLE!')
TensorFlow Version 2.0.0
GPU is available.
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import time
import glob
from IPython import display
读取数据
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5
buffer_size = 60000
batch_size = 256
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(buffer_size).batch(batch_size).prefetch(1)
生成器模型定义
def make_generator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(7 * 7 * 256, use_bias=False, input_shape=(100,)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256)
model.add(tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
generator = make_generator_model()
generator.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12544) 1254400
_________________________________________________________________
batch_normalization (BatchNo (None, 12544) 50176
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 12544) 0
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 7, 7, 128) 819200
_________________________________________________________________
batch_normalization_1 (Batch (None, 7, 7, 128) 512
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 64) 204800
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 1) 1600
=================================================================
Total params: 2,330,944
Trainable params: 2,305,472
Non-trainable params: 25,472
_________________________________________________________________
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
plt.show()

判别器模型定义
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2),
padding='same', input_shape=[28, 28, 1]))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1))
return model
discriminator = make_discriminator_model()
discriminator.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 64) 1664
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 128) 204928
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 6273
=================================================================
Total params: 212,865
Trainable params: 212,865
Non-trainable params: 0
_________________________________________________________________
decision = discriminator(generated_image)
print(decision)
tf.Tensor([[0.00091151]], shape=(1, 1), dtype=float32)
训练设置
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
判别器损失函数
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
生成器损失函数
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
两者优化器
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
checkpoint_dir = './training_checkpoints'
if not os.path.exists(checkpoint_dir):
os.mkdir(checkpoint_dir)
checkpoint_prefix = os.path.join(checkpoint_dir, 'ckpt')
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer = discriminator_optimizer,
generator = generator,
discriminator = discriminator)
定义超参数
epochs = 20
noise_dim = 100
num_examples_to_generate = 16
产生随机种子
seed = tf.random.normal([num_examples_to_generate, noise_dim])
定义单次训练过程
@tf.function 注解使函数被“编译”为计算图/静态图模式
@tf.function
def train_step(images):
noise = tf.random.normal([batch_size, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
生成和保存图片
def generate_and_save_images(model, epoch, test_input):
if not os.path.exists('./generate_images'):
os.mkdir('./generate_images')
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('./generate_images/image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
训练函数定义
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
display.clear_output(wait=True)
generate_and_save_images(generator, epoch + 1, seed)
if (epoch + 1) % 5 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Time for epoch {} is {} sec'.format(epoch + 1, time.time() - start))
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
利用 %%time 获取 cell 每运行一次所花费的时间
%%time
train(train_dataset, epochs)

Time for epoch 20 is 44.1142475605011 sec
Wall time: 14min 5s
可视化
显示单张图
def display_image(epoch_no):
return PIL.Image.open('./generate_images/image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(epochs)
定义动图函数
import imageio
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('./generate_images/image*.png')
filenames = sorted(filenames)
last = -1
for i, filename in enumerate(filenames):
frame = 2 * (i ** 0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
display.Image(filename=anim_file)

五、CGANTensorFLow 2.x 高阶 API Keras实现
导入必要的包
import tensorflow as tf
print('TensorFlow Version', tf.__version__)
print('GPU is ', 'available.' if tf.test.is_gpu_available() else 'NOT AVAILABLE!')
TensorFlow Version 2.0.0
GPU is available.
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import time
import glob
from IPython import display
数据读取
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5
train_labels = tf.one_hot(train_labels, depth=10)
train_labels = tf.cast(train_labels, tf.float32)
buffer_size = 60000
batch_size = 256
train_dataset = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).shuffle(buffer_size).batch(batch_size).prefetch(1)
生成器模型定义
def make_generator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(7 * 7 * 256, use_bias=False, input_shape=(110,)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256)
model.add(tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
generator = make_generator_model()
generator.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12544) 1379840
_________________________________________________________________
batch_normalization (BatchNo (None, 12544) 50176
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 12544) 0
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 7, 7, 128) 819200
_________________________________________________________________
batch_normalization_1 (Batch (None, 7, 7, 128) 512
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 64) 204800
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 1) 1600
=================================================================
Total params: 2,456,384
Trainable params: 2,430,912
Non-trainable params: 25,472
_________________________________________________________________
以标签 0 为例
noise = tf.random.normal([1, 100])
labels = [0]
labels = tf.one_hot(labels, depth=10)
labels = tf.cast(labels, tf.float32)
noise = tf.concat([noise, labels], 1)
print('noise.shape:', noise.shape)
noise.shape: (1, 110)
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
plt.show()

generated_image.shape
TensorShape([1, 28, 28, 1])
labels_input = tf.reshape(labels, [1, 1, 1, 10])
generated_input = tf.concat([generated_image, labels_input * tf.ones([1, 28, 28, 10])], 3)
generated_input.shape
TensorShape([1, 28, 28, 11])
判别器模型定义
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Conv2D(64, (5, 5), strides=(2, 2),
padding='same', input_shape=[28, 28, 11]))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Dropout(0.3))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1))
return model
discriminator = make_discriminator_model()
discriminator.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 14, 14, 64) 17664
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 7, 7, 128) 204928
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 6273
=================================================================
Total params: 228,865
Trainable params: 228,865
Non-trainable params: 0
_________________________________________________________________
decision = discriminator(generated_input)
print(decision)
tf.Tensor([[-0.06202808]], shape=(1, 1), dtype=float32)
训练设置
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
判别器损失函数
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
生成器损失函数
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
两者优化器
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
checkpoint_dir = './Ctraining_checkpoints'
if not os.path.exists(checkpoint_dir):
os.mkdir(checkpoint_dir)
checkpoint_prefix = os.path.join(checkpoint_dir, 'ckpt')
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer = discriminator_optimizer,
generator = generator,
discriminator = discriminator)
定义超参数
epochs = 20
noise_dim = 100
num_examples_to_generate = 100
产生随机种子
seed = tf.random.normal([num_examples_to_generate, noise_dim])
labels = [i % 10 for i in range(num_examples_to_generate)]
labels = tf.one_hot(labels, depth=10)
labels = tf.cast(labels, tf.float32)
seed = tf.concat([seed, labels], 1)
print(seed.shape)
(100, 110)
定义单次训练过程
@tf.function 注解使函数被“编译”为计算图/静态图模式
@tf.function
def train_step(data_batch):
images = data_batch[0]
labels = data_batch[1]
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
noise = tf.random.normal([images.get_shape()[0], noise_dim])
noise_input = tf.concat([noise, labels], 1)
generated_images = generator(noise_input, training=True)
labels_input = tf.reshape(labels, [images.get_shape()[0], 1, 1, 10])
images_input = tf.concat([images, labels_input * tf.ones([images.get_shape()[0], 28, 28, 10])], 3)
generated_input = tf.concat([generated_images, labels_input * tf.ones([images.get_shape()[0], 28, 28, 10])], 3)
real_output = discriminator(images_input, training=True)
fake_output = discriminator(generated_input, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
生成和保存图片
def generate_and_save_images(model, epoch, test_input):
if not os.path.exists('./Cgenerate_images'):
os.mkdir('./Cgenerate_images')
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(10, 10))
for i in range(predictions.shape[0]):
plt.subplot(10, 10, i + 1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('./Cgenerate_images/image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
训练函数定义
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for data_batch in dataset:
train_step(data_batch)
display.clear_output(wait=True)
generate_and_save_images(generator, epoch + 1, seed)
if (epoch + 1) % 5 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print('Time for epoch {} is {} sec'.format(epoch + 1, time.time() - start))
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
利用 %%time 获取 cell 每运行一次所花费的时间
%%time
train(train_dataset, epochs)

Time for epoch 20 is 48.72547435760498 sec
Wall time: 16min 4s
可视化
显示单张图
def display_image(epoch_no):
return PIL.Image.open('./Cgenerate_images/image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(epochs)

定义动图函数
import imageio
anim_file = 'Cdcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('./Cgenerate_images/image*.png')
filenames = sorted(filenames)
last = -1
for i, filename in enumerate(filenames):
frame = 2 * (i ** 0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
display.Image(filename=anim_file)
六、GAN and CGANTensorFLow 1.x 低阶 API实现
特别说明
本次实验采用的浙江大学城市学院的黑胡桃社区进行训练,这是浙江大学城市学院提供的一个学习平台,可以在线预约GPU训练环境进行学习
黑胡桃社区
点击此处进入黑胡桃社区首页,黑胡桃社区首页如下,需要注册才能使用
函数文件
函数文件我将会上传至我的GitHub

notebook示例
!nvidia-smi
Sat May 30 12:31:42 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.43 Driver Version: 418.43 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 105... Off | 00000000:89:00.0 Off | N/A |
| 21% 24C P8 N/A / 75W | 0MiB / 4040MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
安装 imageio 库
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ imageio
Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple/
Requirement already satisfied: imageio in /opt/conda/lib/python3.6/site-packages (2.8.0)
Requirement already satisfied: numpy in /opt/conda/lib/python3.6/site-packages (from imageio) (1.16.2)
此处省略部分输出
安装 tensorflow-gpu==1.15.2,默认为 TensorFlow 2.x版本
!pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ tensorflow-gpu==1.15.2
Looking in indexes: https://pypi.mirrors.ustc.edu.cn/simple/
Requirement already satisfied: tensorflow-gpu==1.15.2 in /opt/conda/lib/python3.6/site-packages (1.15.2)
Requirement already satisfied: google-pasta>=0.1.6 in /opt/conda/lib/python3.6/site-packages (from tensorflow-gpu==1.15.2) (0.2.0)
此处省略部分输出
import tensorflow as tf
tf.__version__
'1.15.2'
cd TensorFlow1.x_GAN_and_CGAN
/home/jovyan/TensorFlow1.x_GAN_and_CGAN
ls
CGAN.py [0m[01;34mdataset_download[0m/ GAN.py main.py ops.py [01;34m__pycache__[0m/ utils.py
GAN 生成
!python main.py --dataset fashion_mnist --gan_type GAN --epoch 20 --batch_size 64
[*] Reading checkpoints...
[*] Success to read GAN.model-21861
[*] Load SUCCESS
[*] Training finished!
[*] Testing finished!
CGAN 生成
!python main.py --dataset fashion_mnist --gan_type CGAN --epoch 20 --batch_size 64
[*] Reading checkpoints...
[*] Success to read CGAN.model-21861
[*] Load SUCCESS
[*] Training finished!
[*] Testing finished!
返回父级目录
cd ..
/home/jovyan
ls
TensorFlow1.x_GAN_and_CGAN/ TensorFlow1.x_GAN_and_CGAN.ipynb
定义压缩函数
import os
import zipfile
def zipDir(dirpath, outFullName):
'''
压缩指定文件夹
:param dirpath: 目标文件夹路径
:param outFullName: 压缩文件保存路径+XXXX.zip
:return: 无
'''
zip = zipfile.ZipFile(outFullName, 'w', zipfile.ZIP_DEFLATED)
for path, dirnames, filenames in os.walk(dirpath):
# 去掉目标和路径,只对目标文件夹下边的文件及文件夹进行压缩(包括父文件夹本身)
this_path = os.path.abspath('.')
fpath = path.replace(this_path, '')
for filename in filenames:
zip.write(os.path.join(path, filename), os.path.join(fpath, filename))
zip.close()
开始压缩,方便下载文件
zipDir('TensorFlow1.x_GAN_and_CGAN', 'download.zip')
七、总结
前后几个月,终于完成 TensorFlow 笔记系列,十分感谢 TensorFlow 开源社区的支持,感谢 Google 提供的 Colab 训练环境,感谢中国大学 MOOC,感谢浙江大学城市学院吴明辉老师开设的课程——深度学习应用开发-TensorFlow实践,最后需要整理所有代码跟文件,上传 GitHub。完结,撒花!★,°:.☆( ̄▽ ̄)/$:.°★ 。