五、Hadoop核心组件之HDFS
上篇博客介绍了Hadoop的本地模式和伪分布式,本篇主要介绍Hadoop的核心组件HDFS,关注专栏《from zero to hero(Hadoop篇)》查看相关系列的文章~
目录
一、HDFS的产生背景
二、HDFS的定义
三、HDFS的优缺点
3.1 HDFS的优点
3.2 HDFS的缺点
四、HDFS的架构
4.1 HDFS架构图
4.2 数据默认存储方式
4.3 NameNode的启动流程
4.4 元数据的合并流程
4.5 HDFS的读写流程
4.5.1 写流程
4.5.2 读流程
五、HDFS的Shell命令
5.1 简述
5.2 示例
六、HDFS的API操作
一、HDFS的产生背景
随着数据量越来越大,一个操作系统存不下所有的数据,那么就需要分配到更多的操作系统中,但是这样不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统,而HDFS正式分布式文件管理系统中的一种。
二、HDFS的定义
HDFS(Hadoop Distributed File System)是运行在普通硬件之上具备高吞吐量支持大数据集的分布式文件系统。它适合一次写入多次读出的场景且不支持文件的修改。
三、HDFS的优缺点
3.1 HDFS的优点
(1)处理超大文件,通常是指数百MB、数百TB大小的文件。
(2)流式的访问数据,一次写入,多次读取,一个数据集一旦由数据源生成就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务的请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,所以对于HDFS来说请求读取整个数据集要比读取某条记录更高效。
(3)运行于廉价的商用机器集群,对硬件要求低,这也就要求设计HDFS时要充分考虑数据的可靠性、安全性以及高可用性。
3.2 HDFS的缺点
(1)不适合低延迟数据访问,HDFS是为高数据吞吐量而设计的,这就要求以高延迟为代价。
(2)无法高效存储大量小文件,因为NameNode把文件系统的原数据放在内存中,所以文件系统所能容纳的文件数目是由NameNode的内存大小来决定的。
(3)不支持多用户写入及任意修改文件,HDFS中的一个文件只有一个写入者,而且写操作只能在文件末尾完成,也就是追加写入。
四、HDFS的架构
4.1 HDFS架构图
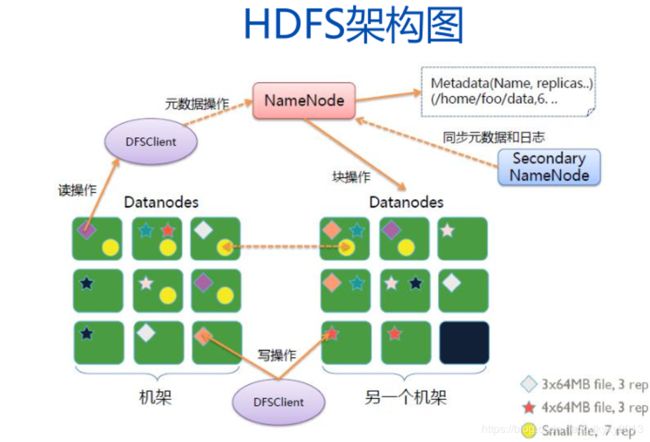
(1)NameNode:接收用户操作请求,维护文件系统的目录结构,管理文件与block之间的关系,block与DataNode之间的关系。一个集群只有一个处于active,用来存储文件和元数据信息,它将元数据信息保存在内存中,同时会在硬盘上保留一份。如:文件名、文件目录结构、文件属性(生成时间、副本数、文件权限等),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode:在本地文件系统存储文件块数据,以及块数据的校验和。在HDFS上保存的数据副本数默认是3个,副本数可以设置。
(3)Secondary NameNode:用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS的元数据的快照。
4.2 数据默认存储方式
数据在第一个DataNode节点写成功后,会自己保留一个副本,然后向同一机架的不同节点拷贝一份,最后向另外机架的不同节点再拷贝一份,保证副本数。保存在同一机架不同节点,是为了保证传输速度,同一机架的不同节点之间网络链路相对最短。保存在不同机架的不同节点的原因在于考虑到不同机架出现故障的几率比较小,可以保证数据安全。
4.3 NameNode的启动流程
(1)NameNode启动时首先将fsimage载入内存并执行编辑日志editlog的各项操作。
(2)一旦在内存中建立文件系统元数据映射,则创建一个新的fsimage文件和一个空的editlog。
(3)在安全模式下,DataNode会向NameNode发送块列表的最新情况。
(4)此刻NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
(5)NameNode开始监听RPC和HTTP的请求。
(6)系统中数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。
(7)在系统的正确操作期间,NameNode会在内存中保留所有块信息的映射信息。
4.4 元数据的合并流程
NameNode的元数据会先往edits文件中写,当edits文件达到一定的阈值的时候,开启合并流程:
(1)当开始合并的时候,SecondaryNameNode会把edits和fsimage拷贝到自己的内存中,开始合并,合并生成一个名为fsimage.ckpt的文件。
(2)将fsimage.ckpt拷贝到NameNode上以后,删除原有的fsimage并将fsimage.ckpt改为fsimage。
(3)当SecondaryNameNode把edits和fsimage拷贝走之后,NameNode会立即生成一个edits.new文件,用于记录新来的原数据,当合并完成之后,原有的edits才会被删除,并将edits.new改名为edits,开启新一轮的流程。
4.5 HDFS的读写流程
4.5.1 写流程
将数据存入HDFS中的时候会把数据分成一个个的block,默认大小是128M,将block1分成一个个的package,将package1发送给DN1,DN1接收完package1,自己存一份,再将package1发送给同一机架不同节点的DN2,DN2接收完之后,自己存一份,再将package1发送给不同机架不同节点的DN4……以此类推,当block1接收完成后,DN1,DN2,DN4向NN汇报消息,然后再通知客户端block1接收完毕,于是客户端开始发送block2……
4.5.2 读流程
(1)client会向NameNode发送读取数据请求,NameNode会将元数据查询出来,把每一个数据存在的位置发送给client。
(2)client会优先从本地读取数据,如果本地不存在数据,会从元数据记录的第一个存储位置DN开始读取,读取完毕开始按照block的顺序读取最近的DN上的数据。
(3)将各个block按顺序读取完毕,形成整个文件。
(4)关闭输入输出流。
五、HDFS的Shell命令
5.1 简述
这里需要注意的是在Linux上执行hdfs dfs 与hadoop fs是同等效果,dfs是fs的实现类。
[root@node2 ~]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile ... ]
[-cat [-ignoreCrc] ...]
[-checksum ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] ... ]
[-copyToLocal [-p] [-ignoreCrc] [-crc] ... ]
[-count [-q] [-h] ...]
[-cp [-f] [-p | -p[topax]] ... ]
[-createSnapshot []]
[-deleteSnapshot ]
[-df [-h] [ ...]]
[-du [-s] [-h] ...]
[-expunge]
[-find ... ...]
[-get [-p] [-ignoreCrc] [-crc] ... ]
[-getfacl [-R] ]
[-getfattr [-R] {-n name | -d} [-e en] ]
[-getmerge [-nl] ]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [ ...]]
[-mkdir [-p] ...]
[-moveFromLocal ... ]
[-moveToLocal ]
[-mv ... ]
[-put [-f] [-p] [-l] ... ]
[-renameSnapshot ]
[-rm [-f] [-r|-R] [-skipTrash] ...]
[-rmdir [--ignore-fail-on-non-empty] ...]
[-setfacl [-R] [{-b|-k} {-m|-x } ]|[--set ]]
[-setfattr {-n name [-v value] | -x name} ]
[-setrep [-R] [-w] ...]
[-stat [format] ...]
[-tail [-f] ]
[-test -[defsz] ]
[-text [-ignoreCrc] ...]
[-touchz ...]
[-truncate [-w] ...]
[-usage [cmd ...]]
Generic options supported are
-conf specify an application configuration file
-D use value for given property
-fs specify a namenode
-jt specify a ResourceManager
-files specify comma separated files to be copied to the map reduce cluster
-libjars specify comma separated jar files to include in the classpath.
-archives specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
5.2 示例
(1)-help:输出这个命令参数
[root@node2 ~]# hadoop fs -help rm
-rm [-f] [-r|-R] [-skipTrash] ... :
Delete all files that match the specified file pattern. Equivalent to the Unix
command "rm "
-skipTrash option bypasses trash, if enabled, and immediately deletes
-f If the file does not exist, do not display a diagnostic message or
modify the exit status to reflect an error.
-[rR] Recursively deletes directories
(2)-ls: 显示目录信息
[root@node2 ~]# hadoop fs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2020-05-20 03:08 /files
drwxr-xr-x - root supergroup 0 2020-05-20 05:12 /output
drwx------ - root supergroup 0 2020-05-20 05:11 /tmp
(3)-mkdir:在HDFS上创建目录
[root@node2 ~]# hadoop fs -mkdir -p /xzw/files
[root@node2 ~]# hdfs dfs -ls /xzw
Found 1 items
drwxr-xr-x - root supergroup 0 2020-05-27 14:43 /xzw/files
(4)-moveFromLocal:从本地剪切粘贴到HDFS
[root@node2 files]# ll
total 4
-rw-r--r-- 1 root root 32 May 20 03:07 text
[root@node2 files]# hdfs dfs -moveFromLocal ./text /xzw/files/
[root@node2 files]# hdfs dfs -ls /xzw/files
Found 1 items
-rw-r--r-- 3 root supergroup 32 2020-05-27 14:45 /xzw/files/text
(5)-appendToFile:追加一个文件到已经存在的文件末尾
[root@node2 files]# ll
total 4
-rw-r--r-- 1 root root 16 May 27 14:47 cs
[root@node2 files]# hdfs dfs -appendToFile ./cs /xzw/files/test
[root@node2 files]# hdfs dfs -cat /xzw/files/test
aaa bbb
ccc ddd
(6)-cat:显示文件内容
[root@node2 files]# hdfs dfs -cat /xzw/files/test
aaa bbb
ccc ddd
aaa bbb
ccc ddd
(7)-chgrp 、-chmod、-chown:修改文件所属权限
[root@node2 files]# hdfs dfs -chmod -R 777 /xzw
[root@node2 files]# hdfs dfs -ls /
Found 4 items
drwxr-xr-x - root supergroup 0 2020-05-20 03:08 /files
drwxr-xr-x - root supergroup 0 2020-05-20 05:12 /output
drwx------ - root supergroup 0 2020-05-20 05:11 /tmp
drwxrwxrwx - root supergroup 0 2020-05-27 14:43 /xzw
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[root@node2 files]# ll
total 4
-rw-r--r-- 1 root root 16 May 27 14:47 cs
[root@node2 files]# hdfs dfs -copyFromLocal ./cs /xzw/files
[root@node2 files]# hdfs dfs -ls /xzw/files/
Found 3 items
-rw-r--r-- 3 root supergroup 16 2020-05-28 09:03 /xzw/files/cs
-rwxrwxrwx 3 root supergroup 32 2020-05-27 14:51 /xzw/files/test
-rwxrwxrwx 3 root supergroup 32 2020-05-27 14:45 /xzw/files/text
(9)-copyToLocal:从HDFS拷贝到本地
[root@node2 files]# ll
total 4
-rw-r--r-- 1 root root 16 May 27 14:47 cs
[root@node2 files]# hdfs dfs -copyToLocal /xzw/files/text ./
[root@node2 files]# ll
total 8
-rw-r--r-- 1 root root 16 May 27 14:47 cs
-rw-r--r-- 1 root root 32 May 28 09:06 text
(10)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
[root@node2 files]# hdfs dfs -cp /xzw/files/cs /files
[root@node2 files]# hdfs dfs -ls /files
Found 2 items
-rw-r--r-- 3 root supergroup 16 2020-05-28 09:08 /files/cs
-rw-r--r-- 3 root supergroup 32 2020-05-20 03:08 /files/text
(11)-mv:在HDFS目录中移动文件
[root@node2 files]# hdfs dfs -mv /xzw/files/test /files/(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
[root@node2 files]# ls
cs text
[root@node2 files]# hdfs dfs -get /files/test ./
[root@node2 files]# ls
cs test text
(13)-getmerge:合并下载多个文件
[root@node2 files]# hdfs dfs -getmerge /files/* ./aaa
[root@node2 files]# cat aaa
aaa bbb
ccc ddd
aaa bbb
ccc ddd
aaa bbb
ccc ddd
xzw lzq lyq
lzq lyq yxy
yxy xzw
(14)-put:等同于copyFromLocal
[root@node2 files]# hdfs dfs -put ./aaa /files/(15)-tail:显示一个文件的末尾
[root@node2 files]# hdfs dfs -tail /files/test
aaa bbb
ccc ddd
aaa bbb
ccc ddd
(16)-rm:删除文件或文件夹
[root@node2 ~]# hdfs dfs -ls /xzw/files/
Found 2 items
-rw-r--r-- 3 root supergroup 16 2020-05-28 09:03 /xzw/files/cs
-rwxrwxrwx 3 root supergroup 32 2020-05-27 14:45 /xzw/files/text
[root@node2 ~]# hdfs dfs -rm -r /xzw/files/text
20/05/28 14:15:58 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /xzw/files/text
[root@node2 ~]# hdfs dfs -ls /xzw/files/
Found 1 items
-rw-r--r-- 3 root supergroup 16 2020-05-28 09:03 /xzw/files/cs
(17)-rmdir:删除空目录
[root@node2 ~]# hdfs dfs -mkdir /aaa
[root@node2 ~]# hdfs dfs -rmdir /aaa
(18)-du统计文件夹的大小信息
[root@node2 ~]# hdfs dfs -rmdir /aaa
[root@node2 ~]# hdfs dfs -du -s -h /xzw/files
16 /xzw/files
[root@node2 ~]# hdfs dfs -du -h /xzw/files
16 /xzw/files/cs
[root@node2 ~]# hdfs dfs -du -h /files
80 /files/aaa
16 /files/cs
32 /files/test
32 /files/text
(19)-setrep:设置HDFS中文件的副本数量
[root@node2 ~]# hdfs dfs -setrep 5 /xzw/files/cs
Replication 5 set: /xzw/files/cs

这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到5台时,副本数才能达到5。
六、HDFS的API操作
1、新建Maven项目,添加如下依赖。
junit
junit
RELEASE
org.apache.logging.log4j
log4j-core
2.8.2
org.apache.hadoop
hadoop-common
2.7.2
org.apache.hadoop
hadoop-client
2.7.2
org.apache.hadoop
hadoop-hdfs
2.7.2
2、在resources目录下添加log4j.properties。
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3、新建Client类。
package com.xzw.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
/**
* @author: xzw
* @create_date: 2020/5/13 22:35
* @desc: HDFS客户端
* @modifier:
* @modified_date:
* @desc:
*/
public class HDFSClient {
//定义文件系统
private FileSystem fs;
/**
* 运行程序之前,先运行before方法
*
* @throws IOException
* @throws InterruptedException
*/
@Before
public void before() throws IOException, InterruptedException {
//获取一个hdfs的抽象封装对象
fs = FileSystem.get(URI.create("hdfs://master:9000"), new Configuration(), "root");
}
/**
* 从本地上传文件到hdfs
*
* @throws IOException
* @throws InterruptedException
*/
@Test
public void put() throws IOException, InterruptedException {
//设置副本数(优先级:程序设置>配置文件>默认)
//configuration.setInt("dfs.replication", 1);
fs.copyFromLocalFile(new Path("C:\\Users\\Machenike\\Desktop\\file\\xzw.txt"),
new Path("/xzw"));
}
/**
* 从hdfs上下载文件
*
* @throws IOException
* @throws InterruptedException
*/
@Test
public void get() throws IOException, InterruptedException {
fs.copyToLocalFile(new Path("/files/file.txt"),
new Path("C:\\Users\\Machenike\\Desktop\\file\\"));
}
/**
* 重命名hdfs上的文件
*
* @throws IOException
* @throws InterruptedException
*/
@Test
public void rename() throws IOException, InterruptedException {
fs.rename(new Path("/files/file.txt"), new Path("/files/file"));
}
/**
* 删除目录
*
* @throws IOException
*/
@Test
public void delete() throws IOException {
boolean delete = fs.delete(new Path("/files"), true);
if (delete) {
System.out.println("删除成功!");
} else {
System.out.println("删除失败!");
}
}
/**
* 追加内容到hdfs
*
* @throws IOException
*/
@Test
public void appendToHDFS() throws IOException {
FSDataOutputStream append = fs.append(new Path("/xzw/xzw.txt"), 1024);
FileInputStream open = new FileInputStream("C:\\Users\\Machenike\\Desktop\\file\\xzw.txt");
IOUtils.copyBytes(open, append, 1024, true);
}
/**
* 列出目录相关信息
*
* @throws IOException
*/
@Test
public void listInfo() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/xzw"));
for (FileStatus fileStatus : fileStatuses) {
if (fileStatus.isFile()) {
System.out.println("以下是这个文件的相关信息:");
System.out.println(fileStatus.getPath());
System.out.println(fileStatus.getLen());
} else {
System.out.println("这是一个文件夹");
System.out.println(fileStatus.getPath());
}
}
}
/**
* 获取文件的信息
*
* @throws IOException
*/
@Test
public void listFiles() throws IOException {
RemoteIterator files = fs.listFiles(new Path("/xzw"), true);
while (files.hasNext()) {
LocatedFileStatus file = files.next();
System.out.println(file.getPath());
System.out.println("块信息:");
BlockLocation[] blockLocations = file.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
String[] hosts = blockLocation.getHosts();
System.out.println("块在");
for (String host : hosts) {
System.out.println(host + " ");
}
}
}
}
/**
* 程序运行结束后执行的方法
*
* @throws IOException
*/
@After
public void after() throws IOException {
//关闭文件系统
fs.close();
}
}
4、HDFS的I/O流操作。
通过输入输出流实现上述HDFS的API操作。
package com.xzw.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author: xzw
* @create_date: 2020/5/30 10:27
* @desc: 输入输出流实现HDFS API
* @modifier:
* @modified_date:
* @desc:
*/
public class HDFSAPi {
/**
* 本地资源上传到HDFS
*
* @param localPath 本地资源路径
* @param hdfsPath hdfs上传路径
* @throws URISyntaxException
* @throws IOException
* @throws InterruptedException
*/
public void localToHDFS(String localPath, String hdfsPath) throws URISyntaxException, IOException,
InterruptedException {
//1、获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), configuration, "root");
//2、创建输入流
FileInputStream fileInputStream = new FileInputStream(new File(localPath));
//3、获取输出流
FSDataOutputStream fsDataOutputStream = fs.create(new Path(hdfsPath));
//4、流对拷
IOUtils.copyBytes(fileInputStream, fsDataOutputStream, configuration);
//5、关闭资源
IOUtils.closeStream(fsDataOutputStream);
IOUtils.closeStream(fileInputStream);
fs.close();
}
/**
* hdfs下载文件到本地
*
* @param hdfsPath hdfs路径
* @param localPath 本地路径
* @throws URISyntaxException
* @throws IOException
* @throws InterruptedException
*/
public void hdfsToLocal(String hdfsPath, String localPath) throws URISyntaxException, IOException,
InterruptedException {
//1、获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), configuration, "root");
//2、获取输入流
FSDataInputStream fsDataInputStream = fs.open(new Path(hdfsPath));
//3、获取输出流
FileOutputStream fileOutputStream = new FileOutputStream(new File(localPath));
//4、流对拷
IOUtils.copyBytes(fsDataInputStream, fileOutputStream, configuration);
//5、关闭资源
IOUtils.closeStream(fileOutputStream);
IOUtils.closeStream(fsDataInputStream);
fs.close();
}
public static void main(String[] args) throws InterruptedException, IOException, URISyntaxException {
//本地上传文件到hdfs
new HDFSAPi().localToHDFS("C:\\Users\\Machenike\\Desktop\\file\\file.txt", "/xzw/file");
//hdfs下载文件到本地
new HDFSAPi().hdfsToLocal("/xzw/file", "C:\\Users\\Machenike\\Desktop\\file\\file");
}
}
本文到此也就结束了,在次过程中你们遇到什么问题,欢迎留言,让我看看你们都遇到了哪些问题~