详述 Java NIO 以及 Socket 处理粘包和断包方法
文章目录
- Java NIO
- 通道
- 缓冲区
- 代码示例
- 第一部分
- 第二部分
- 选择器
- Socket 处理粘包 & 断包问题
- 第一个问题:对于粘包问题的解决
- 第二个问题:对于断包问题的解决
- 示例代码
Java NIO
NIO 是 New I/O 的简称,是 JDK 1.4 新增的功能,之所以称其为 New I/O,原因在于它相对于之前的 I/O 类库是新增的。由于之前老的 I/O 类库是阻塞 I/O,New I/O 类库的目标就是要让 Java 支持非阻塞 I/O,所以也有很多人喜欢称其为 Non-block I/O,即非阻塞 I/O。
NIO 的文件读写设计颠覆了传统 IO 的设计,采用『通道』+『缓存区』使得新式的 I/O 操作直接面向缓存区。NIO 弥补了原来同步阻塞 I/O 的不足,它在标准 Java 代码中提供了高速的、面向块的 I/O。通过定义包含数据的类,以及通过以块的形式处理这些数据,NIO 不用使用本机代码就可以利用低级优化,这是原来的 I/O 包所无法做到的。
通道
在 NIO 中,通道用Channel表示,网络数据通过Channel读取和写入。通道与流的不同之处在于通道是双向的,流只是在一个方向上移动(一个流必须是InputStream或者OutputStream的子类),而通道可以用于读、写或者二者同时进行。因为Channel是全双工的,所以它可以比流更好地映射底层操作系统的 API。特别地,在 UNIX 网络编程模型中,底层操作系统的通道都是全双工的,同时支持读写操作。通道的工作模式大致如下:
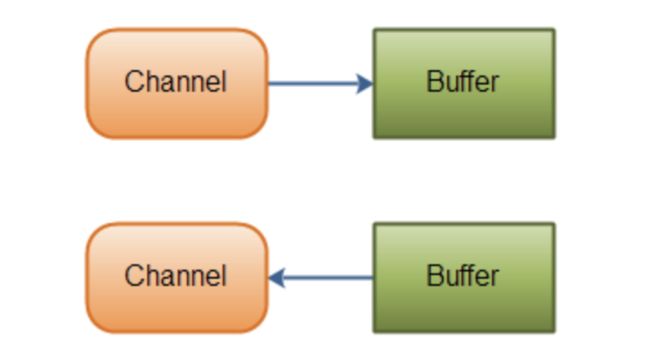
在这里,我们要明白一点,通道和流都是需要基于物理文件的,而每个流或者通道都通过文件指针操作文件,这里说的「通道是双向的」也是有前提的,那就是通道基于随机访问文件RandomAccessFile的可读可写文件指针。RandomAccessFile是既可读又可写的,所以基于它的通道是双向的,所以「通道是双向的」这句话是有前提的,不能断章取义。基本的通道类型包括:
FileChannelDatagramChannelSocketChannelServerSocketChannel
其中,FileChannel是基于文件的通道,SocketChannel和ServerSocketChannel用于网络 TCP 套接字数据报读写的通道,DatagramChannel是用于网络 UDP 套接字数据报读写的通道。
通道不能单独存在,它永远需要绑定一个缓存区,所有的数据只会存在于缓存区中,无论你是写或是读,必然是缓存区通过通道到达磁盘文件,或是磁盘文件通过通道到达缓存区,即缓存区是数据的起点也是终点。
缓冲区
在 NIO 中,缓冲区用Buffer表示,它包含一些要写入或者要读出的数据。Buffer是所有具体缓存区的基类,是一个抽象类,它的实现类有很多,包含各种类型数据的缓存。
ByteBufferCharBufferShortBufferIntBufferLongBufferFloatBufferDoubleBufferMappedByteBuffer
在 NIO 类库中加入Buffer对象,体现了新库与老 I/O 的一个重要区别。在面向流的 I/O 中,可以将数据直接写入或者将数据直接读到Stream对象中。在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的;在写入数据时,写入到缓冲区中。任何时候访问 NIO 中的数据,都是通过缓冲区进行操作。缓冲区实质上是一个数组,但它不仅仅是一个数组,缓冲区提供了对数据的结构化访问以及维护读写位置等信息。
我们以ByteBuffer为例进行学习,其余的缓存区也都是基于字节缓存区的,只不过多了一步字节转换过程而已,MappedByteBuffer是一个特殊的缓存方式,稍后单独介绍。Buffer中有几个重要的成员属性,我们先来了解一下:
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
long address;
其中,mark属性用于重复读;capacity描述缓存区容量,即整个缓存区最大能存储多少数据量;address用于操作直接内存,区别于 JVM 内存。而position和limit,可以用下面这张图解释:
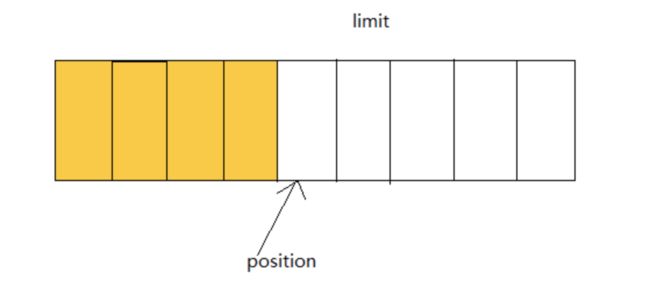
由于缓存区是读写共存的,所以不同的模式下,这两个变量的值也具有不同的意义。
- 写模式下,所谓写模式就是将缓存区中的内容写入通道。
position代表下一个字节应该被写出去的字节在缓存区中的位置,limit表示最后一个待写字节在缓存区的位置。 - 读模式下,所谓读模式就是从通道读取数据到缓存区。
position代表下一个读出来的字节应当存储在缓存区的位置,limit等于capacity。
对于 JVM 我们有一个共识,那就是内存可以划分为栈和堆,但其实划分给 JVM 的还有一块堆外内存,也就是直接内存。这是一块物理内存,专门用于 JVM 和 I/O 设备打交道,Java 底层使用 C 语言的 API 调用操作系统与 I/O 设备进行交互。
例如,Java 内存中有一个字节数组,现在调用流将它写入磁盘文件,那么 JVM 首先会将这个字节数组先拷贝一份到堆外内存中,然后调用 C 语言 API 指明将某个连续地址范围的数据写入磁盘。读操作也是类似,而 JVM 额外做的拷贝工作也是有意义的,因为 JVM 是基于自动垃圾回收机制运行的,所有内存中的数据会在 GC 时不停的被移动,如果你调用系统 API 告诉操作系统将内存某某位置的内存写入磁盘,而此时发生 GC 移动了该部分数据,GC 结束后操作系统是不是就写错数据了。
所以,JVM 对于与外围 I/O 设备交互的情况下,都会将内存数据复制一份到堆外内存中,然后调用系统 API 间接的写入磁盘,读也是类似的。由于堆外内存不受 GC 管理,所以用完之后一定要记得释放。
代码示例
// Step 1
RandomAccessFile file = new RandomAccessFile("C:\\Users\\niogeek\\Desktop\\testNIO.txt","rw");
FileChannel channel = file.getChannel();
// Step 2
ByteBuffer buffer = ByteBuffer.allocate(1024);
channel.read(buffer);
// Step 3
buffer.flip();
byte[] res = new byte[1024];
buffer.get(res, 0, buffer.limit());
System.out.println(new String(res));
// Step 4
channel.close();
我们看这么一段代码,这段代码大致分成了四个部分,第一部分用于获取文件通道,第二部分用于分配缓存区并完成读操作,第三部分用于将缓存区中数据进行打印,第四部分为关闭通道连接。
第一部分
getChannel方法用于获取一个文件相关的通道实例,具体实现如下:
public final FileChannel getChannel() {
synchronized (this) {
if (channel == null) {
channel = FileChannelImpl.open(fd, path, true, rw, this);
}
return channel;
}
}
public static FileChannel open(FileDescriptor var0, String var1, boolean var2, boolean var3, Object var4) {
return new FileChannelImpl(var0, var1, var2, var3, false, var4);
}
getChannel方法会调用FileChannelImpl的工厂方法构建一个FileChannelImpl实例,FileChannelImpl是抽象类FileChannel的一个子类实现。
构成FileChannelImpl实例所需的必要参数有,该文件的文件指针,该文件的完整路径,读写权限等。
第二部分
Buffer的基本结构我们已经介绍过了,这里不再赘述,所谓的缓存区,本质上就是字节数组。
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
return new HeapByteBuffer(capacity, capacity);
}
ByteBuffer实例的构建是通过工厂模式产生的,必须指定参数capacity作为内部字节数组的容量。HeapByteBuffer是虚拟机的堆上内存,所有数据都将存储在堆空间,还有一个相对的DirectByteBuffer,它被分配在堆外内存中。这个HeapByteBuffer的构造情况我们不妨跟进去看看:
HeapByteBuffer(int cap, int lim) {
super(-1, 0, lim, cap, new byte[cap], 0);
}
调用父类的构造方法,初始化我们在ByteBuffer中提过的一些属性值,如position、capacity、mark、limit、offset以及字节数组hb。接着,我们看看这个read方法的调用链:
public int read(ByteBuffer var1) throws IOException {
this.ensureOpen();
if(!this.readable) {
throw new NonReadableChannelException();
} else {
Object var2 = this.positionLock;
synchronized(this.positionLock) {
int var3 = 0;
int var4 = -1;
byte var5;
try {
this.begin();
var4 = this.threads.add();
if(this.isOpen()) {
do {
var3 = IOUtil.read(this.fd, var1, -1L, this.nd);
} while(var3 == -3 && this.isOpen());
int var12 = IOStatus.normalize(var3);
return var12;
}
var5 = 0;
} finally {
this.threads.remove(var4);
this.end(var3 > 0);
assert IOStatus.check(var3);
}
return var5;
}
}
}
这个read方法是子类FileChannelImpl对父类FileChannel.read方法的重写。这个方法不是读操作的核心,我们简单概括一下,该方法首先会拿到当前通道实例的锁,如果没有被其他线程占有,那么占有该锁,并调用IOUtil的read方法。
static int read(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
if(var1.isReadOnly()) {
throw new IllegalArgumentException("Read-only buffer");
} else if(var1 instanceof DirectBuffer) {
return readIntoNativeBuffer(var0, var1, var2, var4);
} else {
ByteBuffer var5 = Util.getTemporaryDirectBuffer(var1.remaining());
int var7;
try {
int var6 = readIntoNativeBuffer(var0, var5, var2, var4);
var5.flip();
if(var6 > 0) {
var1.put(var5);
}
var7 = var6;
} finally {
Util.offerFirstTemporaryDirectBuffer(var5);
}
return var7;
}
}
IOUtil的read方法内部也调用了很多方法,有的甚至是本地方法,这里只简单介绍一下整个read方法的大体逻辑,具体细节留待大家自行学习。
- 首先判断我们的
ByteBuffer实例是不是一个DirectBuffer,也就是判断当前的ByteBuffer实例是不是被分配在直接内存中,- 如果是,那么将调用
readIntoNativeBuffer方法从磁盘读取数据直接放入ByteBuffer实例所在的直接内存中。 - 否则,虚拟机将在直接内存区域分配一块内存,该内存区域的首地址存储在
var5实例的address属性中。
- 如果是,那么将调用
- 接着从磁盘读取数据放入
var5所代表的直接内存区域中。 - 最后,
put方法会将var5所代表的直接内存区域中的数据写入到var1所代表的堆内缓存区并释放临时创建的直接内存空间。
这样,我们传入的缓存区中就成功的被读入了数据。写操作是相反的,大家可以自行类比,反正堆内数据想要到达磁盘就必定要经过堆外内存的复制过程。
第三第四部分比较简单,这里就不再赘述了。提醒一下,想要更好的使用这个通道和缓存区进行文件读写操作,我们就一定得对缓存区的几个变量的值时刻把握住,position和limit当前的值是什么,大致什么位置,一定得清晰,否则这个读写共存的缓存区可能会让我们晕头转向。
选择器
Selector是 Java NIO 的一个组件,它用于监听多个Channel的各种状态,用于管理多个Channel。但本质上由于FileChannel不支持注册选择器,所以Selector一般被认为是服务于网络套接字通道的。
而大家口中的「NIO 是非阻塞的」,准确来说,指的是网络编程中客户端与服务端连接交换数据的过程是非阻塞的。普通的文件读写依然是阻塞的,和 IO 是一样的,这一点可能很多初学者会懵,需要好好理解。
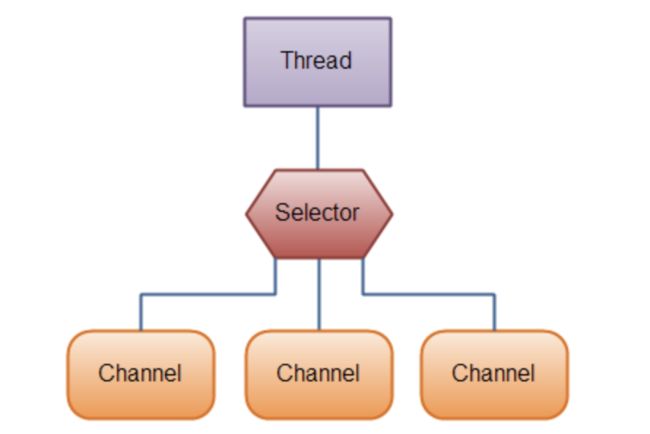
创建一个选择器一般是通过Selector的工厂方法,Selector.open:
Selector selector = Selector.open();
而一个通道想要注册到某个选择器中,必须调整模式为非阻塞模式,例如:
//创建一个 TCP 套接字通道
SocketChannel channel = SocketChannel.open();
//调整通道为非阻塞模式
channel.configureBlocking(false);
//向选择器注册一个通道
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
以上代码是注册一个通道到选择器中的最简单版本,支持注册选择器的通道都有一个register方法,该方法就是用于注册当前实例通道到指定选择器的。该方法的第一个参数就是目标选择器,第二个参数其实是一个二进制掩码,它指明当前选择器感兴趣当前通道的哪些事件。以枚举类型提供了以下几种取值:
int OP_READ = 1 << 0;int OP_WRITE = 1 << 2;int OP_CONNECT = 1 << 3;int OP_ACCEPT = 1 << 4;
这种用二进制掩码来表示某些状态的机制,和虚拟机类文件结构类似,它就是用一个二进制位来描述一种状态。
register方法会返回一个SelectionKey实例,该实例代表的就是选择器与通道的一个关联关系。我们可以调用它的selector方法返回当前相关联的选择器实例,也可以调用它的channel方法返回当前关联关系中的通道实例。
除此之外,SelectionKey的readyOps方法将返回当前选择感兴趣当前通道中事件中准备就绪的事件集合,依然返回的一个整型数值,也就是一个二进制掩码。例如:
int readySet = selectionKey.readyOps();
假如readySet的值为13,二进制为0000 1101,从后向前数,第一位为1,第三位为1,第四位为1,那么说明选择器关联的通道,读就绪、写就绪,连接就绪。所以,当我们注册一个通道到选择器之后,就可以通过返回的SelectionKey实例监听该通道的各种事件。
当然,一旦某个选择器中注册了多个通道,我们不可能一个一个的记录它们注册时返回的SelectionKey实例来监听通道事件,选择器的selectedKeys方法可以返回所有注册成功的通道相关的SelectionKey实例。
Set<SelectionKey> keys = selector.selectedKeys();
selectedKeys方法会返回选择器中注册成功的所有通道的SelectionKey实例集合。我们通过这个集合的SelectionKey实例,可以得到所有通道的事件就绪情况并进行相应的处理操作。下面我们以一个简单的客户端服务端连接通讯的实例应用一下上述理论知识:

服务端代码:

这段小程序的运行的实际效果是这样的,客户端建立请求到服务端,待请求完全建立,客户端会去检查服务端是否有数据写回,而服务端的任务就很简单了,接受任意客户端的请求连接并为它写回一段数据。
别看整个过程很简单,但只要我们有一点模糊的地方,这个功能就不可能实现。这其实也算一个最最简单的服务器客户端请求模型了,理解了这一点相信会有助于理解浏览器与 Web 服务器的工作原理。
想必大家也能发现,加了选择器的代码会复杂很多,也并不一定高效于原来的代码,这其实是因为我们的功能比较简单,并不涉及大量通道处理,逻辑一旦复杂起来,选择器给我们带来的好处会非常明显。
Socket 处理粘包 & 断包问题
NIO Socket 是非阻塞的通讯模式,与 IO 阻塞式的通讯不同点在于 NIO 的数据要通过Channel放到一个缓存池ByteBuffer中,然后再从这个缓存池中读出数据,而 IO 的模式是直接从InputStream中read。所以对于 NIO,由于存在缓存池的大小限制和网速的不均匀会造成一次读的操作放入缓存池中的数据不完整,便形成了断包问题。同理,如果一次性读入两个及两个以上的数据,则无法分辨两个数据包的界限问题,也就造成了粘包。
对于 NIO 的SocketChannel每次触发OP_READ事件时,发送端不一定仅仅写入了一次,同理,发送端如果一次发送数据包过大,那么发送端的一次写入也可能会被拆分成两次OP_READ事件,所以OP_READ事件和发送端的OP_WRITE事件并不是一一对应的。
第一个问题:对于粘包问题的解决
粘包问题主要是由于数据包界限不清,所以这个问题比较好解决,最好的解决办法就是在发送数据包前事先发送一个int型数据,该数据代表将要发送的数据包的大小,这样接收端可以每次触发OP_READ的时候先接受一个int大小的数据段到缓存池中,然后,紧接着读出后续完整的大小的包,这样就会处理掉粘包问题。因为channel.read()方法不能给读取数据的大小的参数,所以无法手动指定读取数据段的大小。但每次调用channel.read()返回的是他实际读取的大小。
这样,思路就有了:首先调整缓存池的大小固定为要读出数据段的大小,这样保证不会过量读出。由于OP_READ和OP_WRITE不是一一对应的,所以一次OP_READ可以while循环调用channel.read()不停读取Channel中的数据到缓存池,并捕获其返回值,当返回值累计达到要读取数据段大小时break掉循环,这样保证数据读取充足。所以这样就完美解决粘包问题。
第二个问题:对于断包问题的解决
断包问题主要是由于数据包过量读入时,缓存池结尾处只有半个数据包,Channel里还有半个数据包,这样造成了这个包无法处理的问题。这个问题的解决思路是保证每次不过量读入,这样也就不存在断包了。还是因为channel.read()的读取不可控的原因,所以无法从read函数中控制读取大小,还是从缓存池入手。方法是调整缓存池的大小为要读数据的大小,这样就不会断包。
示例代码
- 发送端
private void sendIntoChannel() {
Runnable run = new Runnable() {
@Override
public void run() {
try {
ByteArrayOutputStream bOut;
ObjectOutputStream out;
CBaseDataBean cbdb;
ByteBuffer bb = ByteBuffer.allocate(MemCache);
while (true) {
cbdb = CloudServer.cdsq.read();//Blocking Method
//处理自我命令:断开连接 退出线程
if (cbdb.getDataType() == CMsgTypeBean.MSG_TYPE_CUTDOWN) {
break;
}
bOut = new ByteArrayOutputStream();
out = new ObjectOutputStream(bOut);
out.writeObject(cbdb);
out.flush();
//构造发送数据:整型数据头+有效数据段
byte[] arr = bOut.toByteArray();
final int ObjLength = arr.length; //获取有效数据段长度
bb.clear();
bb.limit(IntLength + ObjLength); //调整缓存池大小
bb.putInt(ObjLength);
bb.put(arr);
bb.position(0); //调整重置读写指针
SocketChannel channel = (SocketChannel) key.channel();
channel.write(bb);
out.close();
bOut.close();
}
} catch (IOException ex) {
}
}
};
CloudServer.cstp.putNewThread(run);
}
- 接收端
/**
* 开辟线程分发消息
*/
private void Dispatcher() {
Runnable run = new Runnable() {
@Override
public void run() {
try {
while (true) {
selector.selectNow();
Thread.sleep(100);
Iterator<SelectionKey> itor = selector.selectedKeys().iterator();
while (itor.hasNext()) {
SelectionKey selKey = itor.next();
itor.remove();
if (selKey.isValid() && selKey.isAcceptable()) {
finshAccept(selKey);
}
if (selKey.isValid() && selKey.isReadable()) {
//消息分发
Processer();
}
}
}
} catch (IOException | InterruptedException ex) {
System.out.println(ex.toString());
}
}
};
CloudServer.cstp.putNewThread(run);
}
/**
* 消息处理器
*/
private void Processer() {
ByteBuffer bbInt = ByteBuffer.allocate(IntLength); //读取INT头信息的缓存池
ByteBuffer bbObj = ByteBuffer.allocate(MemCache); //读取OBJ有效数据的缓存池
SocketChannel channel = (SocketChannel)key.channel();
ByteArrayInputStream bIn;
ObjectInputStream in;
CBaseDataBean cbdb;
//有效数据长度
int ObjLength;
//从NIO信道中读出的数据长度
int readObj;
try {
//读出INT数据头
while (channel.read(bbInt) == IntLength) {
//获取INT头中标示的有效数据长度信息并清空INT缓存池
ObjLength = bbInt.getInt(0);
bbInt.clear();
//清空有效数据缓存池设置有效缓存池的大小
bbObj.clear();
bbObj.limit(ObjLength);
//循环读满缓存池以保证数据完整性
readObj = channel.read(bbObj);
while (readObj != ObjLength) {
readObj += channel.read(bbObj);
}
bIn = new ByteArrayInputStream(bbObj.array());
in = new ObjectInputStream(bIn);
cbdb = (CBaseDataBean) in.readObject();
switch (cbdb.getDataType()) {
case CMsgTypeBean.MSG_TYPE_COMMAND:
rcv_msg_command(cbdb);
break;
case CMsgTypeBean.MSG_TYPE_CUTDOWN:
rcv_msg_cutdown();
break;
case CMsgTypeBean.MSG_TYPE_VERIFYFILE:
rcv_msg_verifyfile(cbdb);
break;
case CMsgTypeBean.MSG_TYPE_SENDFILE:
rcv_msg_sendfile(cbdb);
break;
case CMsgTypeBean.MSG_TYPE_DISPATCHTASK:
rcv_msg_dispchtask(cbdb);
break;
}
in.close();
}
} catch (ClassNotFoundException | IOException ex) {
}
}
参考文献:
- Java NIO详解
- 详解 Java NIO
- 关于java NIO socket处理粘包 断包问题