
凌云时刻 · 技术


导读:这篇笔记我们来看看决策树的另一种划分方式基尼系数和决策树中的超参数,以及决策树的缺陷。
作者 | 计缘
来源 | 凌云时刻(微信号:linuxpk)
基尼系数

在一开始我们使用Scikit Learn中提供的决策树分类器时,DecisionTreeClassifier有一个参数criterion,我们之前传入了entropy,也就是表示此时决策树使用信息熵方式。由此可知,决策树应该不止信息熵一种方式,所以这一节来看看决策树的另一种方式,基尼系数。
其实基尼系数和信息熵的思路基本是一致的,只是判定数据随机性度量的公式不一样,那么基尼系数的公式为:
同样用之前的例子代入公式看一下:
将上面的数据类别占比信息代入公式后可得:
再换一组数据类别占比信息:
代入公式后可得:
可见基尼系数同样反应了数据不确定性的度量。这里就不再使用代码对基尼系数的方式进行模拟了,其实只需要将信息熵的公式换成基尼系数的既可。
信息熵和基尼系数的比较
信息熵和基尼系数都是决策树中根节点划分的依据,本质上这两种方式没有太大的差别,具体的比较在这列一下:
决策树中的超参数
在信息熵那一节中,我们使用代码模拟了决策树的根节点划分过程,从中可以可知道决策树最极端的就是每个叶子节点的不确定性都为0,也就是每个叶子节点都是包含一种类别的数据。这样一来虽然对样本数据的分类准确度非常高,但是却是典型的过拟合情况,或者说模型的泛化能力非常差。
另外一点是如果做到极端情况,那么模型训练过程的时间复杂度也会非常高,达到了 , 是样本数据行数,是样本数据行数, 是样本数据特征数。
综上,我们期望训练出的模型泛化能力要好,并且训练时间复杂度要适中,所以关键就是要对决策树剪枝,从而降低复杂度,解决过拟合问题。这就需要用到决策树的超参数。
在之前我们使用Scikit Learn中的决策树时用到了一个参数max_depth,既决策树深度,就是限定了决策数的层数,这就是一种可以剪枝的超参数。除此之外,还有一些超参数可以达到剪枝作用,我们一一来看一看。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 构建样本数据
X, y = datasets.make_moons(noise=0.25, random_state=666)
# 绘制样本数据
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
|
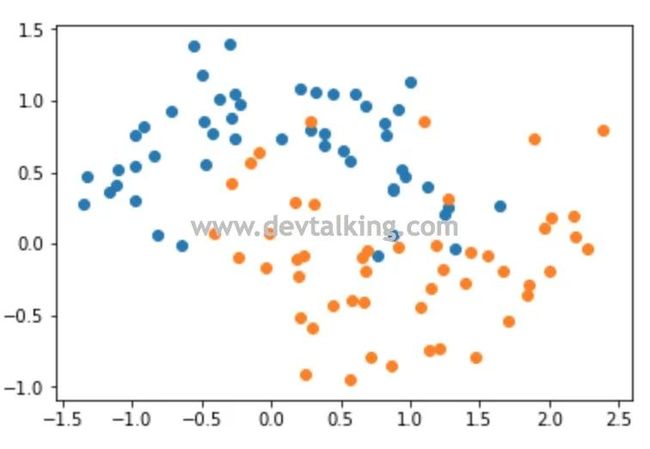
from sklearn.tree import DecisionTreeClassifier
# 不传入任何参数,既criterion默认使用gini,决策树深度划分到不能划分为止
dt_clf = DecisionTreeClassifier()
dt_clf.fit(X, y)
def plot_decision_boundary(model, axis):
# meshgrid函数用两个坐标轴上的点在平面上画格,返回坐标矩阵
X0, X1 = np.meshgrid(
# 随机两组数,起始值和密度由坐标轴的起始值决定
np.linspace(axis[0], axis[1], int((axis[1] - axis[0]) * 100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3] - axis[2]) * 100)).reshape(-1, 1),
)
# ravel()方法将高维数组降为一维数组,c_[]将两个数组以列的形式拼接起来,形成矩阵
X_grid_matrix = np.c_[X0.ravel(), X1.ravel()]
# 通过训练好的逻辑回归模型,预测平面上这些点的分类
y_predict = model.predict(X_grid_matrix)
y_predict_matrix = y_predict.reshape(X0.shape)
# 设置色彩表
from matplotlib.colors import ListedColormap
my_colormap = ListedColormap(['#EF9A9A', '#40E0D0', '#FFFF00'])
# 绘制等高线,并且填充等高区域的颜色
plt.contourf(X0, X1, y_predict_matrix, linewidth=5, cmap=my_colormap)
# 绘制决策边界
plot_decision_boundary(dt_clf, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
|
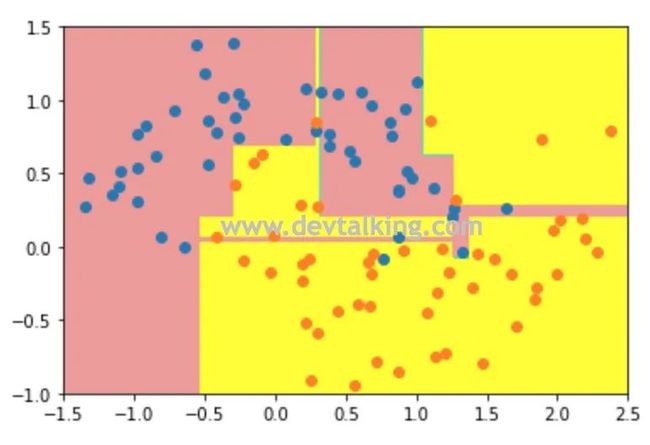
从上图的决策边界可以看出,模型是明显处于过拟合的状态,既能为了个别点就开辟出分界区域,泛化能力是很差的。下面当我们对决策树的深度做限制后看看效果是怎样的:
# 限定决策树深度为2
dt_clf2 = DecisionTreeClassifier(max_depth=2)
dt_clf2.fit(X, y)
# 绘制决策边界
plot_decision_boundary(dt_clf2, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
|
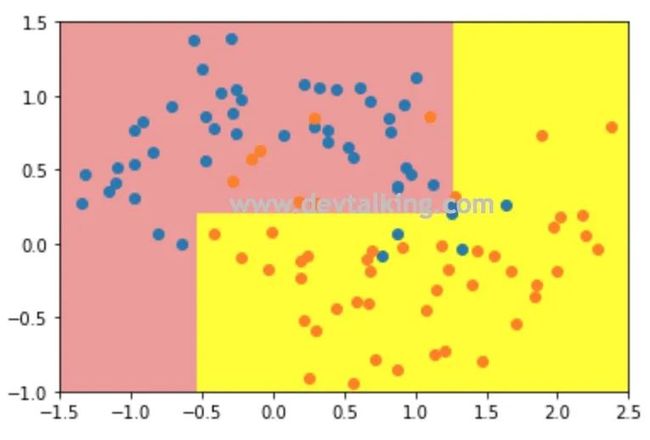
可以看到当限定了决策树深度后,模型的过拟合情况明显得到了改善,泛化能力有明显提高。下面再来看看其他几个超参数。
我们可以指定每个节点当它至少有多少个数据时才继续拆分下去:
# 每个节点至少有10个数据时才会继续拆分下去
dt_clf3 = DecisionTreeClassifier(min_samples_split=10)
dt_clf3.fit(X, y)
# 绘制决策边界
plot_decision_boundary(dt_clf3, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
|
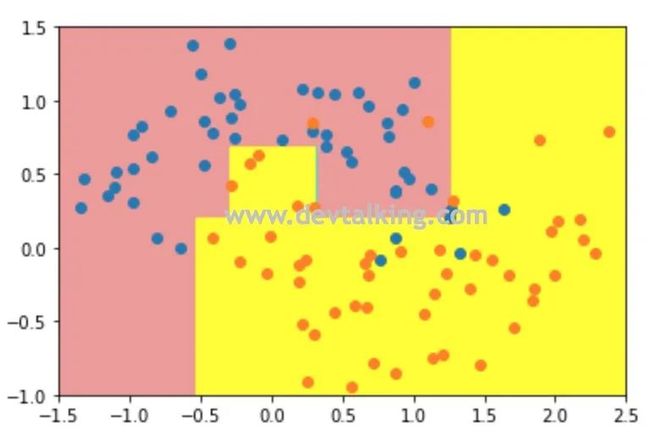
我们还可以指定划分后决策树每个叶子节点至少要多少个样本数据:
# 每个叶子节点至少要有6个样本数据
dt_clf4 = DecisionTreeClassifier(min_samples_leaf=6)
dt_clf4.fit(X, y)
# 绘制决策边界
plot_decision_boundary(dt_clf4, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
|

对于一棵决策树而言,叶子节点越多,决策树肯定约复杂。所以我们也可以指定最大叶子节点个数:
# 决策树的最大叶子节点个数为4
dt_clf5 = DecisionTreeClassifier(max_leaf_nodes=4)
dt_clf5.fit(X, y)
# 绘制决策边界
plot_decision_boundary(dt_clf5, axis=[-1.5, 2.5, -1.0, 1.5])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.show()
|
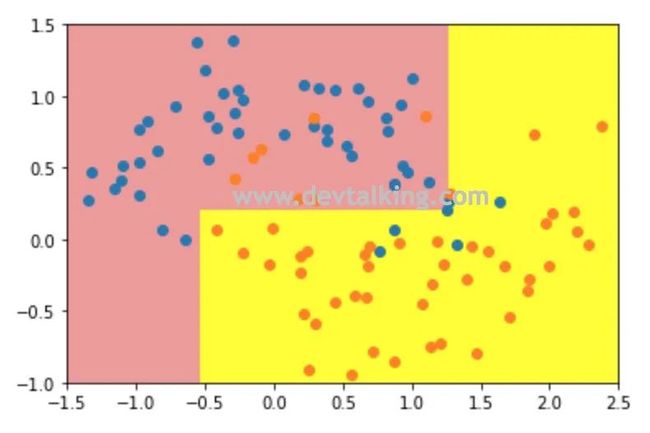
决策树还有许多超参数,这里我们只是举了几个例子,大家可以去Scikit Learn官网去看看DecisionTreeClassifier的其他超参数,然后使用网格搜索方式选出最优超参数的组合,使得模型达到最优效果。
CART
CART是Classification And Regression Tree的缩写,字面意思已经很明确了,分类和回归树,说明我们这篇笔记中介绍的基于信息熵和基尼系数划分方式的决策树既可以解决分类问题,还可以解决回归问题。Scikit Learn中封装的决策树也是CART,当然还有一些其他实现方式的决策树,大家有兴趣可以在网上查阅ID3,C4.5,C5.0等实现方式的决策树。
下面我们来看看Scikit Learn中封装的解决回归问题的决策树:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 使用波士顿房价数据
boston = datasets.load_boston()
X = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
from sklearn.tree import DecisionTreeRegressor
dt_reg = DecisionTreeRegressor()
dt_reg.fit(X_train, y_train)
dt_reg.score(X_test, y_test)
# 结果
0.59192423637607194
|
可以看到Scikit Learn中提供了决策树回归器DecisionTreeRegressor,虽然模型的评分不是很高,但是可以通过超参数来调节,提升评分。DecisionTreeRegressor和超参数和DecisionTreeClassifier的超参数基本是一样的。
决策树的缺陷
这一小节来看看决策树存在的两个缺陷。
 决策边界的局限性
决策边界的局限性
因为决策树的根节点,也就是划分节点的判断条件都是在某个维度,判断小于或大于某个阈值,所以每个根节点的决策边界必然都是平行于某个维度的,对于二维数据来说,决策边界不是平行于横轴就是平行于纵轴的。

比如上图显示的示例,如果使用逻辑回归训练模型,绘制出的决策边界应该是上图中的斜虚线。但如果是使用决策树训练模型,那么绘制出的决策边界应该首先是从中间进行划分:

此时上半部分的信息熵为0,因全部是蓝色点,然后会从中间再分一下:

所以最终决策边界为:
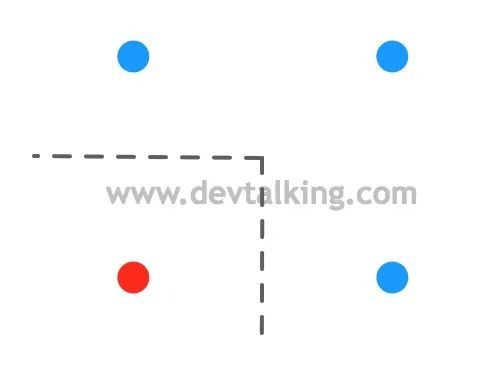
那么这样的横平竖直的决策边界有什么局限性呢?我们再来看一个示例:
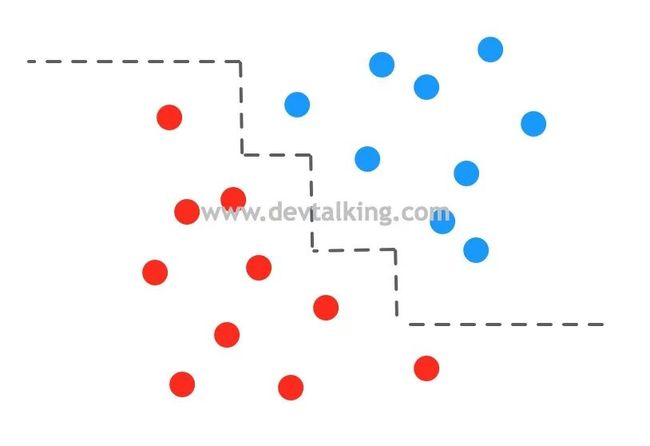
如果是上图显示的样本数据,使用决策树训练的模型绘制出的决策边界是一个阶梯状,中间的阶梯部分划分倒是问题不大,但问题出在两头于横轴平行的部分。如果我们再来一个样本点,看看会被划分到哪一类:

假如新来一个样本点A,它是蓝色点,但是按照决策树的决策边界就被归为了红色点。但如果是逻辑回归模型绘制出的决策边界,点A就能被正确的分类:

这就是决策树决策边界的局限性所在。
对数据敏感
决策树的另一个缺陷是对样本数据中的个别数据非常敏感,这个敏感体现在如果对样本数据进行少许改动,决策边界都会发生巨大改变。我们来举例看看:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
# 还是使用鸢尾花数据
iris = datasets.load_iris()
X = iris.data[:, 2:]
y = iris.target
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier(max_depth=2, criterion="entropy")
dt_clf.fit(X, y)
plot_decision_boundary(dt_clf, axis=[0.5, 7.5, 0, 3])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()
|
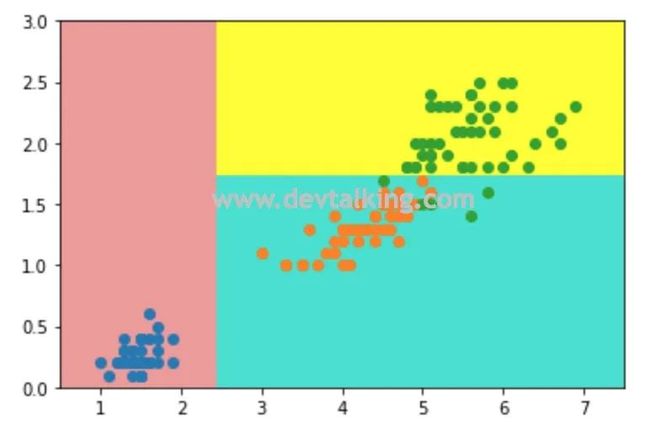
然后我们删除一个鸢尾花数据,再来看看决策边界:
# 删除样本数据中索引为138的数据
X_new = np.delete(X, 138, axis=0)
y_new = np.delete(y, 138)
dt_clf2 = DecisionTreeClassifier(max_depth=2, criterion="entropy")
dt_clf2.fit(X_new, y_new)
plot_decision_boundary(dt_clf2, axis=[0.5, 7.5, 0, 3])
plt.scatter(X[y==0, 0], X[y==0, 1])
plt.scatter(X[y==1, 0], X[y==1, 1])
plt.scatter(X[y==2, 0], X[y==2, 1])
plt.show()
|

可以看到当删除了一个数据后,决策边界发生了巨大的变化。不过对于样本数据中的个别数据很敏感这也是非参数机器学习算法的通病,都比较依赖于调参,才能得到一个比较好的模型。
但是决策树的更多的体现在集成学习中,在下一篇笔记中大家将会看到决策树在集成学习和随机森林里的作用。
END

往期精彩文章回顾

机器学习笔记(二十九):决策树、信息熵
机器学习笔记(二十八):高斯核函数
机器学习笔记(二十七):核函数(Kernel Function)
机器学习笔记(二十六):支撑向量机(SVM)(2)
机器学习笔记(二十五):支撑向量机(SVM)
机器学习笔记(二十四):召回率、混淆矩阵
机器学习笔记(二十三):算法精准率、召回率
机器学习笔记(二十二):逻辑回归中使用模型正则化
机器学习笔记(二十一):决策边界
机器学习笔记(二十):逻辑回归(2)

长按扫描二维码关注凌云时刻
每日收获前沿技术与科技洞见