三、Hadoop运行模式(本地模式、伪分布模式)
上篇博客介绍了Linux下搭建Hadoop运行环境,本篇主要介绍Hadoop的本地运行模式和伪分布式模式,关注专栏《from zero to hero(Hadoop篇)》查看相关系列的文章~
目录
一、本地模式
1.1 官方Grep案例
1.2 官方WordCount案例
二、 伪分布式模式
2.1 启动HDFS运行MapReduce程序
2.2 启动YARN运行MapReduce程序
2.3 配置历史服务器
2.4 配置日志的聚集
一、本地模式
1.1 官方Grep案例
1、在hadoop-2.7.2下创建input文件夹
[root@node1 hadoop-2.7.2]# mkdir input2、将Hadoop的xml配置文件拷贝到input目录下
[root@node1 hadoop-2.7.2]# cp etc/hadoop/*.xml input3、执行share目录下的MapReduce程序
[root@node1 hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'4、查看结果
[root@node1 hadoop-2.7.2]# cat output/*
1 dfsadmin
1.2 官方WordCount案例
1、在hadoop-2.7.2下创建wcinput文件夹
[root@node1 hadoop-2.7.2]# mkdir wcinput2、在wcinput文件下创建一个wc.input文件
[root@node1 hadoop-2.7.2]# cd wcinput
[root@node1 hadoop-2.7.2]# touch wc.input3、编辑wc.input文件
[root@node1 hadoop-2.7.2]# vi wc.input在文件中输入如下内容:
hadoop yarn
hadoop mapreduce
spark4、回到Hadoop目录/opt/modules/hadoop-2.7.2
5、执行程序
[root@node1 hadoop-2.7.2]# hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput6、查看结果
[root@node1 hadoop-2.7.2]# cat wcoutput/part-r-00000
spark 2
hadoop 2
mapreduce 1
yarn 1二、 伪分布式模式
2.1 启动HDFS运行MapReduce程序
1、配置集群
(1)在hadoop-env.sh中修改JAVA_HOME路径
export JAVA_HOME=/opt/modules/jdk1.8.0_144
(2)修改core-site.xml配置文件
fs.defaultFS
hdfs://node1:9000
hadoop.tmp.dir
/opt/modules/hadoop-2.7.2/data/tmp

(3)配置hdfs-site.xml配置文件
dfs.replication
1

2、启动集群
(1)格式化NameNode
[root@node1 hadoop-2.7.2]# bin/hdfs namenode -format(2)启动NameNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-root-namenode-node1.out
[root@node1 hadoop-2.7.2]# jps
29863 Jps
29803 NameNode
[root@node1 hadoop-2.7.2]#(3)启动DataNode
[root@node1 hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-root-datanode-node1.out
[root@node1 hadoop-2.7.2]# jps
30051 Jps
29947 DataNode
29803 NameNode
[root@node1 hadoop-2.7.2]#3、启动成功后,在浏览器查看HDFS文件系统。
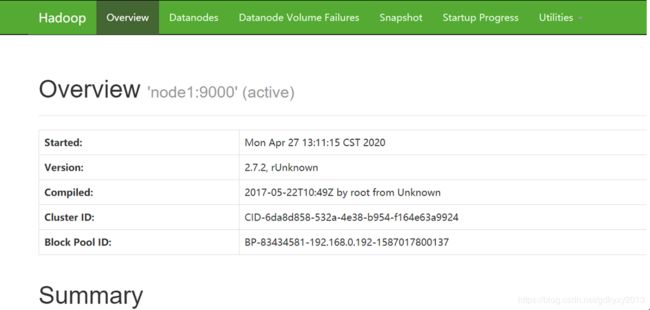
4、查看产生的log日志
[root@node1 logs]# pwd
/opt/modules/hadoop-2.7.2/logs
注意:NameNode格式化一次即可,不可以重复格式化。格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。所以,格式化NameNode时,要先删除data数据和log日志,然后再格式化NameNode。
[root@node1 current]# pwd
/opt/modules/hadoop-2.7.2/data/tmp/dfs/name/current
[root@node1 current]# cat VERSION
#Mon Apr 27 13:11:17 CST 2020
namespaceID=1774549806
clusterID=CID-6da8d858-532a-4e38-b954-f164e63a9924
cTime=0
storageType=NAME_NODE
blockpoolID=BP-83434581-192.168.0.192-1587017800137
layoutVersion=-63
[root@node1 current]# pwd
/opt/modules/hadoop-2.7.2/data/tmp/dfs/data/current
[root@node1 current]# cat VERSION
#Mon Apr 27 13:12:01 CST 2020
storageID=DS-f135ada4-7135-4e43-b064-a87b40c43ba9
clusterID=CID-6da8d858-532a-4e38-b954-f164e63a9924
cTime=0
datanodeUuid=4f2ac5ff-aedd-4554-93e4-88618536ebdc
storageType=DATA_NODE
layoutVersion=-56
[root@node1 current]#
5、操作集群
(1)在HDFS上创建一个input文件夹
[root@node1 ~]# hdfs dfs -mkdir -p /user/xzw/input
[root@node1 ~]# hdfs dfs -ls /user/xzw
Found 1 items
drwxr-xr-x - root supergroup 0 2020-04-27 13:28 /user/xzw/input(2)将测试文件上传到HDFS中
[root@node1 hadoop-2.7.2]# hdfs dfs -put ./wcinput/wc.input /user/xzw/input
[root@node1 hadoop-2.7.2]# hdfs dfs -ls /user/xzw/input
Found 1 items
-rw-r--r-- 1 root supergroup 46 2020-04-27 13:32 /user/xzw/input/wc.input(3)运行MapReduce程序
[root@node1 hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/xzw/input/ /user/xzw/output查看输出结果:
[root@node1 hadoop-2.7.2]# hdfs dfs -ls /user/xzw/output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2020-04-27 13:42 /user/xzw/output/_SUCCESS
-rw-r--r-- 1 root supergroup 38 2020-04-27 13:42 /user/xzw/output/part-r-00000
[root@node1 hadoop-2.7.2]# hdfs dfs -cat /user/xzw/output/part-r-00000
spark 2
hadoop 2
mapreduce 1
yarn 12.2 启动YARN运行MapReduce程序
1、配置集群
(1)配置yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144(2)配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node1

(3)配置mapred-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144(4)对mapred-site.xml.template重新命名为:mapred-site.xml,并进行配置。
mapreduce.framework.name
yarn

2、启动集群
(1)启动NameNode和DataNode
(2)启动ResourceManager
[root@node1 hadoop-2.7.2]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-root-resourcemanager-node1.out
[root@node1 hadoop-2.7.2]# jps
1136 NameNode
1587 Jps
1236 DataNode
1368 ResourceManager(3)启动NodeManager
[root@node1 hadoop-2.7.2]# yarn-daemon.sh start nodemanager
starting nodemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-root-nodemanager-node1.out
[root@node1 hadoop-2.7.2]# jps
1136 NameNode
1665 NodeManager
1236 DataNode
1368 ResourceManager
1770 Jps3、浏览器中查看YARN的界面
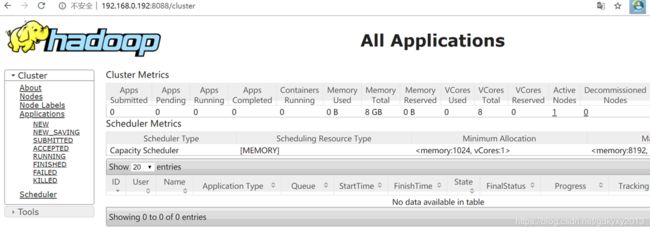
4、执行MapReduce程序
[root@node1 hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/xzw/input/ /user/xzw/output可以在YARN的监控界面查看相关job的状态:
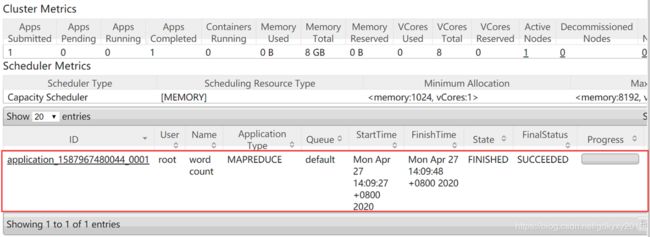
查看运行结果:
[root@node1 hadoop-2.7.2]# hdfs dfs -ls /user/xzw/output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2020-04-27 14:09 /user/xzw/output/_SUCCESS
-rw-r--r-- 1 root supergroup 38 2020-04-27 14:09 /user/xzw/output/part-r-000002.3 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1、配置mapred-site.xml,在配置文件中增加以下配置:
mapreduce.jobhistory.address
node1:10020
mapreduce.jobhistory.webapp.address
node1:19888
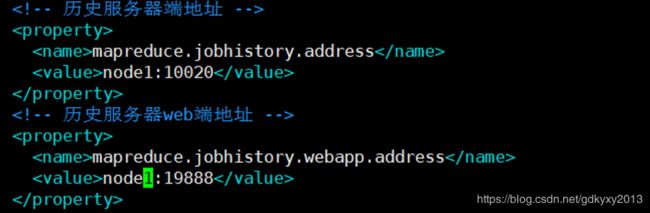
2、启动历史服务器
[root@node1 hadoop]# mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/modules/hadoop-2.7.2/logs/mapred-root-historyserver-node1.out
[root@node1 hadoop]# jps
6176 Jps
1136 NameNode
1665 NodeManager
1236 DataNode
6133 JobHistoryServer
1368 ResourceManager3、监控界面查看JobHistory
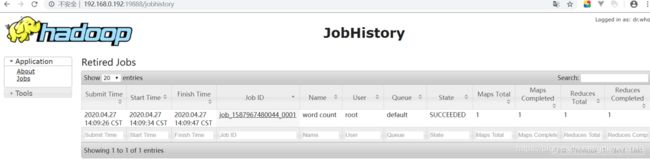
2.4 配置日志的聚集
日志聚集是指应用运行完之后,将程序运行日志信息上传到HDFS系统上。日志聚集的好处是可以方便的查看程序运行情况,方便开发测试。这里需要注意的是,开启日志聚集功能,需要重新启动NodeManager、ResourceManager和HistoryManager。
开启日志聚集的步骤如下:
1、配置yarn-site.xml。
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800

2、重启相关服务
3、执行WordCount程序
[root@node1 hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/xzw/input /user/xzw/output4、查看历史服务器

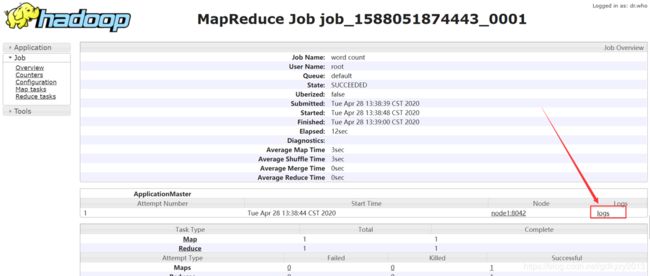
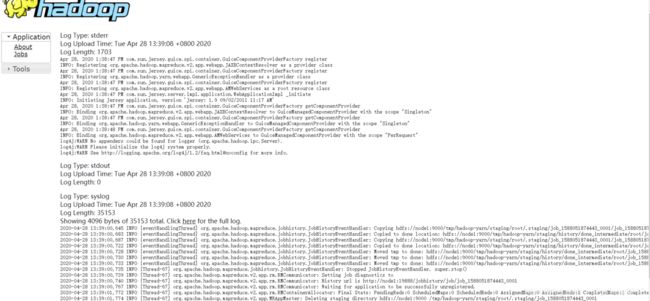
本文到此就结束了,下篇文章将会为大家讲述Hadoop的完全分布式~