四、Hadoop的运行模式(完全分布式)
上篇博客介绍了Hadoop的本地模式和伪分布式,本篇主要介绍Hadoop的完全分布式,关注专栏《from zero to hero(Hadoop篇)》查看相关系列的文章~
目录
一、分发命令以及分发脚本
1.1 scp命令
1.2 rsync命令
1.3 使用rsync命令编写分发脚本
二、集群配置
2.1 集群节点配置
2.2 集群配置
三、集群单点启动
四、 配置SSH免秘钥登录
五、群起集群
六、集群启停方式总结
七、集群时间同步
一、分发命令以及分发脚本
在介绍完全分布式之前,先来看一下相关的分发命令。
1.1 scp命令
scp可以实现服务器与服务器之间的数据拷贝。
例如:将node1中的hadoop及jdk分发到node2上
[root@node1 modules]# scp -r ./hadoop-2.7.2 node2:/opt/modules/
[root@node1 modules]# scp -r ./jdk1.8.0_144 node2:/opt/modules/1.2 rsync命令
rsync主要用于备份和镜像,具有速度快、避免重复相同内容和支持符号链接的优点。rsync复制文件要比scp的速度快,rsync只对差异文件做更新,scp是把所有文件都复制过去。rsync的基本语法为:
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称选项参数说明:-a表示归档拷贝,-v表示显示复制过程。
例如:将/opt/software文件下hadoop tar包同步至node2下的相同目录。
[root@node1 software]# rsync -av ./hadoop-2.7.2.tar.gz node2:/opt/software/
root@node2's password:
sending incremental file list
hadoop-2.7.2.tar.gz
sent 197,706,044 bytes received 35 bytes 9,195,631.58 bytes/sec
total size is 197,657,687 speedup is 1.001.3 使用rsync命令编写分发脚本
有些时候,我们集群节点数比较多,而挨着使用分发命令进行分发是一件非常麻烦的事情。这时候,我们可以编写分发脚本,实现一次性分发。因为rsync命令只是做差异文件的更新,效率上较scp更优,所以我们使用rsync命令编写脚本。
例如:循环复制相关内容至集群所有节点的相同目录下。
1、在/usr/bin/目录下创建xsync文件,此文件用于存放分发脚本代码。
[root@node1 bin]# touch xsync
[root@node1 bin]# vim xsync编辑xsync文件:
#!/bin/bash
#1、获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0));
then
echo no args;
exit;
fi
#2、获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3、获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4、获取当前用户名称
user=`whoami`
#5、循环
for((host=196; host<199; host++));
do
echo -------------------192.168.0.$host---------------------
rsync -av $pdir/$fname [email protected].$host:$pdir
done2、修改脚本执行权限
[root@node1 bin]# chmod 777 ./xsync3、测试
[root@node1 ~]# xsync /opt/modules/jdk1.8.0_144/二、集群配置
2.1 集群节点配置
|
|
node2 |
node3 |
node4 |
| HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2.2 集群配置
1、配置核心配置文件:core-site.xml
fs.defaultFS
hdfs://node2:9000
hadoop.tmp.dir
/opt/modules/hadoop-2.7.2/data/tmp
2、配置HDFS配置文件
(1)配置hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144(2)配置hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
node4:50090
3、配置YARN配置文件
(1)配置yarn-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144(2)配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node3
4、配置MapReduce配置文件
(1)配置mapred-env.sh
export JAVA_HOME=/opt/modules/jdk1.8.0_144(2)配置mapred-site.xml
mapreduce.framework.name
yarn
5、分发配置文件
[root@node2 hadoop]# xsync /opt/modules/hadoop-2.7.2/三、集群单点启动
1、集群第一次启动需要格式化NameNode。
[root@node2 hadoop]# hdfs namenode -format2、在node2上启动NameNode。
[root@node2 hadoop]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-root-namenode-node2.out
[root@node2 hadoop]# jps
7843 NameNode
7915 Jps3、在node2、node3、node4节点上启动DataNode。
[root@node2 hadoop]# hadoop-daemon.sh start datanode
starting datanode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-root-datanode-node2.out
[root@node2 hadoop]# jps
7843 NameNode
8020 Jps
7944 DataNode4、监控界面查看相关配置。
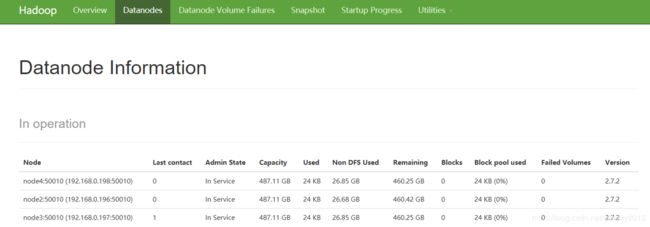
四、 配置SSH免秘钥登录
1、生成公钥和私钥
[root@node1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:yvTppNPebC7sF+fT0wTznNcB77ICu/hy9BW42Ct3sm8 root@node1
The key's randomart image is:
+---[RSA 2048]----+
| |
| . |
| . o |
| . .oo |
| . S o . o=+|
| o o =.o.o o*|
| oo= ++o.oo.|
| .==*o*oEo .|
| .=BBB.Bo . |
+----[SHA256]-----+2、将公钥拷贝到需要免密登录的机器上
[root@node1 ~]# ssh-copy-id node1
[root@node1 ~]# ssh-copy-id node2
[root@node1 ~]# ssh-copy-id node3
[root@node1 ~]# ssh-copy-id node43、相关文件功能解释
[root@node1 .ssh]# pwd
/root/.ssh
[root@node1 .ssh]# ll
total 16
-rw------- 1 root root 1568 Apr 29 14:20 authorized_keys
-rw------- 1 root root 1679 Apr 29 14:15 id_rsa
-rw-r--r-- 1 root root 392 Apr 29 14:15 id_rsa.pub
-rw-r--r-- 1 root root 1396 Apr 29 14:17 known_hosts| known_hosts |
记录ssh访问过计算机的公钥(public key) |
| id_rsa |
生成的私钥 |
| id_rsa.pub |
生成的公钥 |
| authorized_keys |
存放授权过得无密登录服务器公钥 |
五、群起集群
1、配置slaves
[root@node2 hadoop]# pwd
/opt/modules/hadoop-2.7.2/etc/hadoop
[root@node2 hadoop]# vim slaves
node2
node3
node42、同步该文件到集群其他节点
[root@node2 hadoop]# xsync slaves3、启动集群
(1)启动HDFS
[root@node2 hadoop-2.7.2]# sbin/start-dfs.sh
(2)启动YARN(这里需要注意的是,如果ResourceManager和NameNode没有在同一台机器上,需要去ResourceManager所在的机器上启动YARN)
[root@node3 hadoop-2.7.2]# sbin/start-yarn.sh
4、浏览器中输入如下地址查看SecondaryNameNode
node4:50090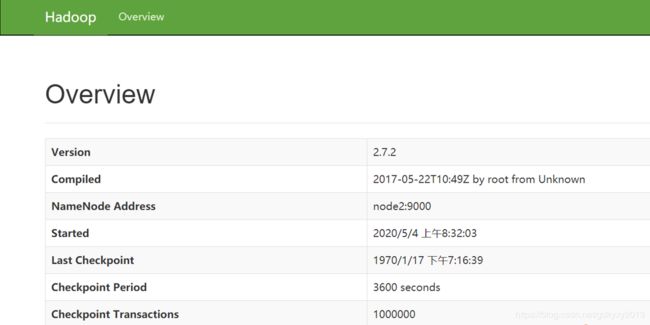
六、集群启停方式总结
1、各个组件分别启动/停止
(1)启停HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode(2)启停YARN各组件
yarn-daemon.sh start / stop resourcemanager / nodemanager2、整体启动/停止
(1)整体启停HDFS
start-dfs.sh / stop-dfs.sh(2)整体启停YARN
start-yarn.sh / stop-yarn.sh七、集群时间同步
1、检查ntp是否安装
[root@node2 ~]# rpm -qa | grep ntp2、如果没有安装ntp的话,需要先安装ntp
[root@node2 ~]# yum -y install ntp再次检查:
[root@node2 ~]# rpm -qa|grep ntp
ntp-4.2.6p5-29.el7.centos.x86_64
ntpdate-4.2.6p5-29.el7.centos.x86_643、修改ntp配置文件
[root@node2 ~]# vim /etc/ntp.conf
#授权192.168.0.0-192.168.0.255这个网段的所有机器可以从本台机器上查询并同步时间
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
#集群在局域网中,不使用其他互联网上的时间
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步。
server 127.127.1.0
fudge 127.127.1.0 stratum 104、修改ntpd文件
[root@node2 ~]# vim /etc/sysconfig/ntpd
#让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes5、重新启动ntpd服务
[root@node2 ~]# systemctl restart ntpd.service6、集群其他机器设置定时任务,每十分钟向该节点同步一次时间。
[root@node3 ~]# crontab -e
*/10 * * * * /usr/sbin/ntpdate node2重启生效。
[root@node3 ~]# systemctl restart crond.service
至此,咱们的Hadoop的完全分布式就讲解完了,你们在这个过程中遇到了什么问题,欢迎留言,让我看看你们遇到了什么问题~