数据库分析——Mysql索引详述
一、引言
为了找工作,这几天疯狂的啃《高性能Mysql》这本神书,来深入理解下Mysql中的一些操作,从而强化自己对Mysql中原理的理解。索引这词我们并不陌生,在书中我们经常性看的目录也是索引,而索引的目的就是加快查询速度,而这篇文章主要讲的是面试中经常被问到的Mysql索引。
二、Mysql索引引入
正如书中的目录一样,建立索引的目的就是为了加快查询速度,Mysql索引也不例外。为了说明索引在Mysql中加快查询速度,我们建立一个表,往里面插入上万条数据,来比较一下利用索引查询数据和不利用索引查询的速度。
在比较开始前,我们来预测一下两者的差距,如果读者在其它资料上看过关于Mysql一些底层的一些原理的话,就会知道Mysql的默认引擎是InnoDB,而InnoDB默认索引实现结构是B+Tree,在B+Tree中查找一个数据是复杂度是O(log(n))级别的,而不依靠索引查询数据的复杂度是O(n)级别的,两者会相差一个量级。
假如索引建立起的是一颗三阶的B+Tree,而数据库中有11条数据,主键序列0到10,其内部就会建立起如下结构:
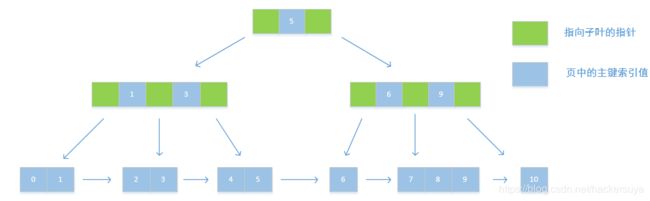
假如遍历主键为10的数据,则按照索引来遍历,Mysql只需要遍历5,9这两个索引就能得到主键值为10的数据,当然,Mysql在B+Tree上进行索引遍历的时候在每个索引层上还会进行二分查找,这样更一步的加快了查询速度。
回到比较的场景,首先建立如下表:
create table student(
id int not null,
name varchar(16) not null ,
age int not null,
primary key('id')
);
一张很普通的student表,在创建的时候默认创建了名为id的主键索引,关于主键索引,之后再谈,之后向这张表中插入10000条数据,在其中查询一条相同的数据:
![]()
SELECT * FROM `student` where id =5008;
SELECT * FROM `student` where age =5011;

从结果来看,利用索引查询与不利用索引的查询的速度相差了5倍,而且还是在10000条数据中。
二、创建Mysql索引
从应用层面上来看,Mysql的索引类型主要有3种:主键索引、唯一索引、普通索引。
- 主键索引:
主键索引大家其实很熟悉,它是在创建数据库表的时候创建的,也就是表中的主键那一列,它默认非空且唯一,也就是这个字段的值不能为NULL,也不能重复,如下就创建了一个名为id的索引:
create table student(
id int not null,
name varchar(16) not null ,
age int not null,
primary key(id)
);
- 唯一索引:索引的值必须唯一,但是可为空,创建语句如下:
create unique index [索引名称] on [表名[字段名](length)]
- 普通索引:索引的值可为空,也可重复,创建语句如下:
create index [索引名称] on [表名[字段名](length)]
如果根据id来查询数据,那么会很快,而反之用其它的字段来查询数据,就会很慢。比如,在原来的student表上将name字段创建为索引:
create index name on student(name(16))
就会使得遍历name字段的速度达到遍历id字段的速度了。
三、Mysql索引的种类
在Mysql中,索引底层的实现有很多种类别,并不是一种索引在任何场景都能发挥出卓越的功效,就像排序算法一样,不同的场景适合于于不同的索引实现。在Mysql的索引实现中,是交由存贮引擎来实现的,不同的存贮引擎支持不同的索引,比如InnoDB支持B+Tree索引,Memory支持哈希索引。
3.1 B+Tree 索引
一般来说,在谈论Mysql索引时,如果没有特别指出是哪种索引类型,那么多半是在说B+Tree索引。B+Tree索引是在面试中问的最多的Mysql问题之一,如果你没有听过B+Tree索引,那么一定听过他的另外一个名字:聚簇索引。
3.1.1 B+Tree与聚簇索引
之所以有聚簇索引这个名字,是因为它的数据结构的实现——B+Tree。一颗m阶的B+Tree有如下的特点:
- 每个节点最多有
m(m>=2)颗子树 - 除了根节点以及叶子节点外,每个分支节点都至少有
ceil(m/2)颗子树 - 根节点至少含有两个节点,除非B树只有根节点
- 所有的叶子节点都在同一层上,且所有的关键字都包含于叶子节点中
- 叶子节点按递增顺序排列,且
每个叶子结点都是连接的,形成一个有序的序列 - 有i个孩子的节点,关键字就有
i-1个,且按递增排列 - 所有的数据都保存在叶子节点中
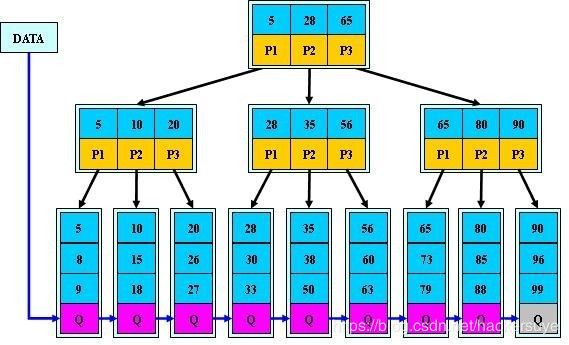
B+Tree的性质保证了如下几个特性:
- 数据都是顺序存贮,且都是有序的,且根节点到叶子节点高度一样
- 相邻的键值与数据行都是紧密的凑在一起的
为什么选择B+Tree来实现聚簇索引?相对于其它数据结构,比如红黑树,B+Tree的高度更小,因为B+Tree的度数比红黑树固定度数为2要多,树高度体现在查找中就会使得查找次数更少,也就是磁盘I/O次数更少。 其次,因为B+Tree是顺序存贮数据的,所以在查找数据的时候根本不需要进行磁盘寻道,只需要旋转很短的距离,就能找到数据。
而聚簇的意思就是指相邻的数据行和相邻的键值紧凑地存储在一起。数据的存贮顺序是与索引的顺序相关的,对于自增的主键,聚簇索引只需要一条一条的按顺序写入磁盘,这样数据就会自然的有序,而没有自增的主键,那么每次插入的时候会进行树的切割操作,在磁盘里就对应着不断调整物理分页了,所以对于前一种磁盘碎片少,效率较高。
不管哪种方案,最终相关数据像是挤在了一起一样,都会有序的排列在叶子节点中,这样就便利了分组与排序,因为相关联的数据总是被分到一块去了,而且就不需要在创建临时表了。
聚簇索引加快了数据的查询速度,因为不再需要全表扫描了,只需要从根节点开始查起,而每一层的键都定义了下一层各个节点的上限与下限,加上二分查找,很容易得出要进入下一层的节点是哪个,最终会遍历到数据行所在。
值得注意的是,聚簇索引在数据行上只保留着数据的主键值,具体的数据需要根据键值来二次进行查找,这被称作聚簇索引的二级索引。
3.1.2 聚簇索引的使用范围
聚簇索引适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
现在对于student这张表进行下修改,把原来的删除,创建一张新的表,将name也设置成主键,如下:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
`class` varchar(255) NOT NULL,
PRIMARY KEY (`id`,`name`)
)
同样的,在里面插入10000条数据,用来测验聚簇索引的适用范围。对于全键值查找,指的是根据所有的键来查找,比如查找如下数据:
![]()
SELECT * FROM `student` where id=6009 and name='995f7';
SELECT * FROM `student` where age=3991;
SELECT * FROM `student` where name='995f7' and id=6009;
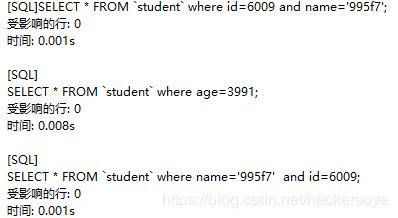
对于全键值查找来说,键的顺序不影响查找的效果,对于键前缀查找,它的匹配规则是最左前缀的查找,比如:
SELECT * FROM `student` where id=6009 and name='995f7';
SELECT * FROM `student` where name='995f7';
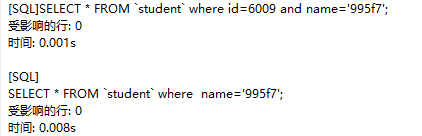
在这里,虽然name也是键的之一,但是它越过了id键来查找,也就是越过了最左的那一个键,即没有匹配最左键,所以它没有利用到聚簇索引。假如一张表中有id,name,age三个键,那么根据最左匹配,它可以匹配如下查询语句:
....where id=1 and name='a' and age=1;
....where id=1 and name='a';
....where id=1;
对于键值范围查找,是同样需要满足键前缀查找的,在匹配范围查找时,还是需要满足键前缀,聚簇索引才能起作用:
SELECT * FROM `student` where id = 6009 and name like '9%';
SELECT * FROM `student` where age like '399_';
SELECT * FROM `student` where name like '9%';

在上述例子中,越过id键直接范围查询以9开头的name键,会发现聚簇索引已经失效了,所以在键值范围查找也要满足最左前缀规则。
基于以上规则,我们不难推测出在Mysql中使用聚簇索引的一些限制:
- 没有依照
最左前缀规则查找,聚簇索引会失效。 - 跳过了索引中的某些键值,聚簇索只会在再跳过的键值之前的键值查找生效,比如
id,name,age是一个索引,以id,age来查询,则只会让id在聚簇索引中生效。 - 查询中如果有范围查找,那么其右边的键值无法使用聚簇索引。
3.1.3 聚簇索引的优劣
聚簇索引的显著特点就是最大限度的提升了I/O密集型应用的性能,它利用索引的思想减少了I/O操作,大幅度的提升了查找的效率,而且相关的数据会被“聚”在一起,免去了在排序与分组的时候建立临时表的操作。
因为聚簇索引需要保证数据的有序,所有插入速度严重依赖于插入顺序,而且如果不是键的自增,会大大降低插入速度,且造成磁盘碎片化过多。而且,更新数据,需要更新索引,降低了更新操作的速度。
3.2 哈希索引
哈希索引的策略采取的哈希表来完成,虽然读取性能达到了O(1)级别,但是失去了数据的有序性和关联性,所以它无法完成:
- 无法完成排序与分组,因为失去了有序性。
- 只能精确查找,无法完成范围查找。
- 无法完成部分查找,因为是根据键的哈希值来确定数据的。
在Mysql中,只有Memory引擎显示支持哈希索引,也支持聚簇索引。在Memory引擎中,是支持非唯一哈希索引的,也就是用链表法来解决哈希冲突的。当查找某个数据时,会根据主键的哈希值来查找对应的数据指针,再根据数据指针查询到主键的所在,然后比较主键是否相等,相等则确认数据是想要的数据。
在InnoDB引擎中有一个特殊的功能叫做自适应哈希索引。当InnoDB注意到某个数据被使用的非常频繁的时候,它会在聚簇索引的基础上创建一个哈希索引,使得聚簇索引也有哈希索引的一些性质。
关于全文索引与空间数据索引在此不再叙述了,感兴趣的同学可以看看《高性能Mysql》一书。
四、索引的优化
4.1 独立的列
独立的列是指的是索引不参与表达式,也不能是函数的参数,比如下面的查询:
select * from student where id+1=3;
上述查询就不会使用到索引,虽然上式和select * from student where id=2在查询结果上等价的,但是后者可以使用到索引。
4.2 多列索引
多列索引指的是多个键值组成一个索引,并不是为多个列创建索引。比如:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
`class` varchar(255) NOT NULL,
PRIMARY KEY (`id`,`name`)
)
上述在创建表的时候创建了一个主键索引,而且还是多列索引,而不是如下:
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
`class` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY(`name`)
两者的区别体现在查询id与name两个字段的查询语句上,在多列索引的情况下,一个索引包含了所有的键,所以在形成B+Tree时,同一个id的name会聚集在一起,查询到了id,查询name会很快,而非多列索引会有多个聚簇索引,也就是多个B+Tree,每个索引之间互不关联,也就查询速度下降了。
4.3 索引列顺序
一般来说,优先查找识别度高的数据能得到一个不错的效率,而优先选择选择性大的索引就是基于这种思想。索引的选择性是指不重复的值和记录总数的值的数量的比值,最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,查询效率也越高。一般把选择性高的索引放在前面。
4.4 前缀索引
对于BLOB、TEXT 和 VARCHAR类型的列,需要使用到前缀索引,只索引开始的部分字符,因为Mysql不允许索引这些列的完整长度。
4.5 覆盖索引
覆盖索引指的是一个索引包含了所有需要查询的字段的值。覆盖索引带来的一个显著的好处就是不需要回表查询,因为索引的叶子节点已经包含要查询的数据。比如:
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`age` int(11) NOT NULL,
`class` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
)
接着查询select id from student。当查询这句时,在聚簇索引内建立的索引的叶子值就是id的值,所以就已经得到所需要的数据了,这就是覆盖索引。
五、索引的优劣与使用范围
索引的优点
-
大大减少了服务器需要扫描的数据行数。
-
帮助服务器避免进行排序和分组,以及避免创建临时表(
B+Tree 索引是有序的,可以用-于ORDER BY和GROUP BY操作。临时表主要是在排序和分组过程中创建,因为不需要排序和分组,也就不需要创建临时表)。 -
将
随机 I/O变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
索引的缺点
- 降低了更新表的速率,更新完数据后还需要更新表的索引,不适合在更新操作频繁的表中建立过多的索引。
- 建立索引会占用磁盘空间的索引文件。
索引的使用条件
-
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
-
对于中到大型的表,索引就非常有效;
-
对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。