Kaggle房价预测案例分享
在Jupyter Notebook运行可以显示图(
--开头是输出的内容,需要注意下)
参考:https://github.com/AliceDudu/Kaggle-projects/blob/master/house-prices-advanced-regression-techniques/house-1-feature.ipynb



参考:https://github.com/AliceDudu/Kaggle-projects/blob/master/house-prices-advanced-regression-techniques/house-1-feature.ipynb
# 导入需要的包
import pandas as pd
import numpy as np
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, RidgeCV, LassoCV, ElasticNetCV
from sklearn.metrics import mean_squared_error, make_scorer
from scipy.stats import skew
from IPython.display import display
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 获取训练数据
train = pd.read_csv("train.csv")
print("train : " + str(train.shape))
--train : (1460, 81)
# 获取测试数据
test = pd.read_csv("test.csv")
print("test : " + str(test.shape))
--test : (1459, 80)
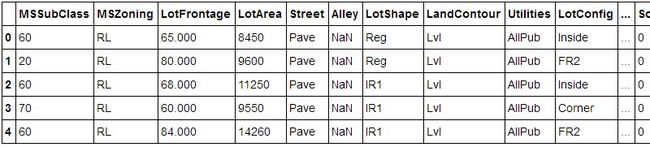
train.head()test.head()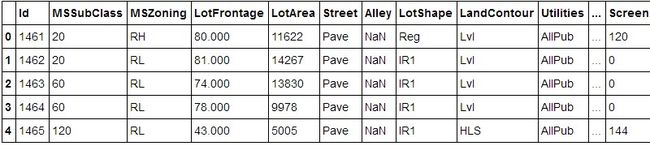
# 合并数据 从'MSSubClass'列到'SaleCondition'列
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'],
test.loc[:,'MSSubClass':'SaleCondition']))
all_data.head()
# 查看重复项
idsUnique = len(set(train.Id))
idsTotal = train.shape[0]
idsDupli = idsTotal - idsUnique
print("There are " + str(idsDupli) + " duplicate IDs for " + str(idsTotal) + " total entries")
# 删除Id列
train.drop("Id", axis = 1, inplace = True)
--There are 0 duplicate IDs for 1460 total entries
# 查看重复项
idsUnique = len(set(test.Id))
idsTotal = test.shape[0]
idsDupli = idsTotal - idsUnique
print("There are " + str(idsDupli) + " duplicate IDs for " + str(idsTotal) + " total entries")
# 删除Id列
test.drop("Id", axis = 1, inplace = True)
--There are 0 duplicate IDs for 1459 total entries
# 寻找异常值,如 https://ww2.amstat.org/publications/jse/v19n3/decock.pdf
plt.scatter(train.GrLivArea, train.SalePrice, c = "blue", marker = "s")
plt.title("Looking for outliers")
plt.xlabel("GrLivArea")
plt.ylabel("SalePrice")
plt.show()
train = train[train.GrLivArea < 4000]
print("train : " + str(train.shape))
--train : (1456, 80)
all_data = pd.concat((train.loc[:,'MSSubClass':'SaleCondition'],
test.loc[:,'MSSubClass':'SaleCondition']))
all_data.head()# 转换官方得分的目标
train.SalePrice = np.log1p(train.SalePrice)
y = train.SalePrice
def fill_missing(dataset):
# 处理中值/平均值或最常见值无意义的特征的缺失值
# Alley : data description says NA means "no alley access"
dataset.loc[:, "Alley"] = dataset.loc[:, "Alley"].fillna("None")
# BedroomAbvGr : NA most likely means 0
dataset.loc[:, "BedroomAbvGr"] = dataset.loc[:, "BedroomAbvGr"].fillna(0)
# BsmtQual etc : data description says NA for basement features is "no basement"
dataset.loc[:, "BsmtQual"] = dataset.loc[:, "BsmtQual"].fillna("No")
dataset.loc[:, "BsmtCond"] = dataset.loc[:, "BsmtCond"].fillna("No")
dataset.loc[:, "BsmtExposure"] = dataset.loc[:, "BsmtExposure"].fillna("No")
dataset.loc[:, "BsmtFinType1"] = dataset.loc[:, "BsmtFinType1"].fillna("No")
dataset.loc[:, "BsmtFinType2"] = dataset.loc[:, "BsmtFinType2"].fillna("No")
dataset.loc[:, "BsmtFullBath"] = dataset.loc[:, "BsmtFullBath"].fillna(0)
dataset.loc[:, "BsmtHalfBath"] = dataset.loc[:, "BsmtHalfBath"].fillna(0)
dataset.loc[:, "BsmtUnfSF"] = dataset.loc[:, "BsmtUnfSF"].fillna(0)
# CentralAir : NA most likely means No
dataset.loc[:, "CentralAir"] = dataset.loc[:, "CentralAir"].fillna("N")
# Condition : NA most likely means Normal
dataset.loc[:, "Condition1"] = dataset.loc[:, "Condition1"].fillna("Norm")
dataset.loc[:, "Condition2"] = dataset.loc[:, "Condition2"].fillna("Norm")
# EnclosedPorch : NA most likely means no enclosed porch
dataset.loc[:, "EnclosedPorch"] = dataset.loc[:, "EnclosedPorch"].fillna(0)
# External stuff : NA most likely means average
dataset.loc[:, "ExterCond"] = dataset.loc[:, "ExterCond"].fillna("TA")
dataset.loc[:, "ExterQual"] = dataset.loc[:, "ExterQual"].fillna("TA")
# Fence : data description says NA means "no fence"
dataset.loc[:, "Fence"] = dataset.loc[:, "Fence"].fillna("No")
# FireplaceQu : data description says NA means "no fireplace"
dataset.loc[:, "FireplaceQu"] = dataset.loc[:, "FireplaceQu"].fillna("No")
dataset.loc[:, "Fireplaces"] = dataset.loc[:, "Fireplaces"].fillna(0)
# Functional : data description says NA means typical
dataset.loc[:, "Functional"] = dataset.loc[:, "Functional"].fillna("Typ")
# GarageType etc : data description says NA for garage features is "no garage"
dataset.loc[:, "GarageType"] = dataset.loc[:, "GarageType"].fillna("No")
dataset.loc[:, "GarageFinish"] = dataset.loc[:, "GarageFinish"].fillna("No")
dataset.loc[:, "GarageQual"] = dataset.loc[:, "GarageQual"].fillna("No")
dataset.loc[:, "GarageCond"] = dataset.loc[:, "GarageCond"].fillna("No")
dataset.loc[:, "GarageArea"] = dataset.loc[:, "GarageArea"].fillna(0)
dataset.loc[:, "GarageCars"] = dataset.loc[:, "GarageCars"].fillna(0)
# HalfBath : NA most likely means no half baths above grade
dataset.loc[:, "HalfBath"] = dataset.loc[:, "HalfBath"].fillna(0)
# HeatingQC : NA most likely means typical
dataset.loc[:, "HeatingQC"] = dataset.loc[:, "HeatingQC"].fillna("TA")
# KitchenAbvGr : NA most likely means 0
dataset.loc[:, "KitchenAbvGr"] = dataset.loc[:, "KitchenAbvGr"].fillna(0)
# KitchenQual : NA most likely means typical
dataset.loc[:, "KitchenQual"] = dataset.loc[:, "KitchenQual"].fillna("TA")
# LotFrontage : NA most likely means no lot frontage
dataset.loc[:, "LotFrontage"] = dataset.loc[:, "LotFrontage"].fillna(0)
# LotShape : NA most likely means regular
dataset.loc[:, "LotShape"] = dataset.loc[:, "LotShape"].fillna("Reg")
# MasVnrType : NA most likely means no veneer
dataset.loc[:, "MasVnrType"] = dataset.loc[:, "MasVnrType"].fillna("None")
dataset.loc[:, "MasVnrArea"] = dataset.loc[:, "MasVnrArea"].fillna(0)
# MiscFeature : data description says NA means "no misc feature"
dataset.loc[:, "MiscFeature"] = dataset.loc[:, "MiscFeature"].fillna("No")
dataset.loc[:, "MiscVal"] = dataset.loc[:, "MiscVal"].fillna(0)
# OpenPorchSF : NA most likely means no open porch
dataset.loc[:, "OpenPorchSF"] = dataset.loc[:, "OpenPorchSF"].fillna(0)
# PavedDrive : NA most likely means not paved
dataset.loc[:, "PavedDrive"] = dataset.loc[:, "PavedDrive"].fillna("N")
# PoolQC : data description says NA means "no pool"
dataset.loc[:, "PoolQC"] = dataset.loc[:, "PoolQC"].fillna("No")
dataset.loc[:, "PoolArea"] = dataset.loc[:, "PoolArea"].fillna(0)
# SaleCondition : NA most likely means normal sale
dataset.loc[:, "SaleCondition"] = dataset.loc[:, "SaleCondition"].fillna("Normal")
# ScreenPorch : NA most likely means no screen porch
dataset.loc[:, "ScreenPorch"] = dataset.loc[:, "ScreenPorch"].fillna(0)
# TotRmsAbvGrd : NA most likely means 0
dataset.loc[:, "TotRmsAbvGrd"] = dataset.loc[:, "TotRmsAbvGrd"].fillna(0)
# Utilities : NA most likely means all public utilities
dataset.loc[:, "Utilities"] = dataset.loc[:, "Utilities"].fillna("AllPub")
# WoodDeckSF : NA most likely means no wood deck
dataset.loc[:, "WoodDeckSF"] = dataset.loc[:, "WoodDeckSF"].fillna(0)
return dataset
train = fill_missing(train)
train.head()
用test得到test new
test_new = fill_missing(test)
test_new.head()
all_data = fill_missing(all_data)
all_data.head()
def num_to_cat(dataset):
# 一些数字特征实际上是真正的类别
dataset = dataset.replace({"MSSubClass" : {20 : "SC20", 30 : "SC30", 40 : "SC40", 45 : "SC45",
50 : "SC50", 60 : "SC60", 70 : "SC70", 75 : "SC75",
80 : "SC80", 85 : "SC85", 90 : "SC90", 120 : "SC120",
150 : "SC150", 160 : "SC160", 180 : "SC180", 190 : "SC190"},
"MoSold" : {1 : "Jan", 2 : "Feb", 3 : "Mar", 4 : "Apr", 5 : "May", 6 : "Jun",
7 : "Jul", 8 : "Aug", 9 : "Sep", 10 : "Oct", 11 : "Nov", 12 : "Dec"}
})
return dataset
train = num_to_cat(train)
train.head()
test_new = num_to_cat(test_new)
test_new.head()
all_data = num_to_cat(all_data)
all_data.head()
def order_cat(dataset):
# 当订单中有信息时,将一些分类功能编码为有序数字
dataset = dataset.replace({"Alley" : {"Grvl" : 1, "Pave" : 2},
"BsmtCond" : {"No" : 0, "Po" : 1, "Fa" : 2, "TA" : 3, "Gd" : 4, "Ex" : 5},
"BsmtExposure" : {"No" : 0, "Mn" : 1, "Av": 2, "Gd" : 3},
"BsmtFinType1" : {"No" : 0, "Unf" : 1, "LwQ": 2, "Rec" : 3, "BLQ" : 4,
"ALQ" : 5, "GLQ" : 6},
"BsmtFinType2" : {"No" : 0, "Unf" : 1, "LwQ": 2, "Rec" : 3, "BLQ" : 4,
"ALQ" : 5, "GLQ" : 6},
"BsmtQual" : {"No" : 0, "Po" : 1, "Fa" : 2, "TA": 3, "Gd" : 4, "Ex" : 5},
"ExterCond" : {"Po" : 1, "Fa" : 2, "TA": 3, "Gd": 4, "Ex" : 5},
"ExterQual" : {"Po" : 1, "Fa" : 2, "TA": 3, "Gd": 4, "Ex" : 5},
"FireplaceQu" : {"No" : 0, "Po" : 1, "Fa" : 2, "TA" : 3, "Gd" : 4, "Ex" : 5},
"Functional" : {"Sal" : 1, "Sev" : 2, "Maj2" : 3, "Maj1" : 4, "Mod": 5,
"Min2" : 6, "Min1" : 7, "Typ" : 8},
"GarageCond" : {"No" : 0, "Po" : 1, "Fa" : 2, "TA" : 3, "Gd" : 4, "Ex" : 5},
"GarageQual" : {"No" : 0, "Po" : 1, "Fa" : 2, "TA" : 3, "Gd" : 4, "Ex" : 5},
"HeatingQC" : {"Po" : 1, "Fa" : 2, "TA" : 3, "Gd" : 4, "Ex" : 5},
"KitchenQual" : {"Po" : 1, "Fa" : 2, "TA" : 3, "Gd" : 4, "Ex" : 5},
"LandSlope" : {"Sev" : 1, "Mod" : 2, "Gtl" : 3},
"LotShape" : {"IR3" : 1, "IR2" : 2, "IR1" : 3, "Reg" : 4},
"PavedDrive" : {"N" : 0, "P" : 1, "Y" : 2},
"PoolQC" : {"No" : 0, "Fa" : 1, "TA" : 2, "Gd" : 3, "Ex" : 4},
"Street" : {"Grvl" : 1, "Pave" : 2},
"Utilities" : {"ELO" : 1, "NoSeWa" : 2, "NoSewr" : 3, "AllPub" : 4}}
)
return dataset
train = order_cat(train)
train.head()
test_new = order_cat(test_new)
test_new.head()
all_data = order_cat(all_data)
all_data.head()
#增加新特征
def new_feature(dataset):
# Create new features
# 1* Simplifications of existing features
dataset["SimplOverallQual"] = dataset.OverallQual.replace({1 : 1, 2 : 1, 3 : 1, # bad
4 : 2, 5 : 2, 6 : 2, # average
7 : 3, 8 : 3, 9 : 3, 10 : 3 # good
})
dataset["SimplOverallCond"] = dataset.OverallCond.replace({1 : 1, 2 : 1, 3 : 1, # bad
4 : 2, 5 : 2, 6 : 2, # average
7 : 3, 8 : 3, 9 : 3, 10 : 3 # good
})
dataset["SimplPoolQC"] = dataset.PoolQC.replace({1 : 1, 2 : 1, # average
3 : 2, 4 : 2 # good
})
dataset["SimplGarageCond"] = dataset.GarageCond.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplGarageQual"] = dataset.GarageQual.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplFireplaceQu"] = dataset.FireplaceQu.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplFireplaceQu"] = dataset.FireplaceQu.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplFunctional"] = dataset.Functional.replace({1 : 1, 2 : 1, # bad
3 : 2, 4 : 2, # major
5 : 3, 6 : 3, 7 : 3, # minor
8 : 4 # typical
})
dataset["SimplKitchenQual"] = dataset.KitchenQual.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplHeatingQC"] = dataset.HeatingQC.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplBsmtFinType1"] = dataset.BsmtFinType1.replace({1 : 1, # unfinished
2 : 1, 3 : 1, # rec room
4 : 2, 5 : 2, 6 : 2 # living quarters
})
dataset["SimplBsmtFinType2"] = dataset.BsmtFinType2.replace({1 : 1, # unfinished
2 : 1, 3 : 1, # rec room
4 : 2, 5 : 2, 6 : 2 # living quarters
})
dataset["SimplBsmtCond"] = dataset.BsmtCond.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplBsmtQual"] = dataset.BsmtQual.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplExterCond"] = dataset.ExterCond.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
dataset["SimplExterQual"] = dataset.ExterQual.replace({1 : 1, # bad
2 : 1, 3 : 1, # average
4 : 2, 5 : 2 # good
})
# 2* Combinations of existing features
# 2* Combinations of existing features
# Overall quality of the house
dataset["OverallGrade"] = dataset["OverallQual"] * dataset["OverallCond"]
# Overall quality of the garage
dataset["GarageGrade"] = dataset["GarageQual"] * dataset["GarageCond"]
# Overall quality of the exterior
dataset["ExterGrade"] = dataset["ExterQual"] * dataset["ExterCond"]
# Overall kitchen score
dataset["KitchenScore"] = dataset["KitchenAbvGr"] * dataset["KitchenQual"]
# Overall fireplace score
dataset["FireplaceScore"] = dataset["Fireplaces"] * dataset["FireplaceQu"]
# Overall garage score
dataset["GarageScore"] = dataset["GarageArea"] * dataset["GarageQual"]
# Overall pool score
dataset["PoolScore"] = dataset["PoolArea"] * dataset["PoolQC"]
# Simplified overall quality of the house
dataset["SimplOverallGrade"] = dataset["SimplOverallQual"] * dataset["SimplOverallCond"]
# Simplified overall quality of the exterior
dataset["SimplExterGrade"] = dataset["SimplExterQual"] * dataset["SimplExterCond"]
# Simplified overall pool score
dataset["SimplPoolScore"] = dataset["PoolArea"] * dataset["SimplPoolQC"]
# Simplified overall garage score
dataset["SimplGarageScore"] = dataset["GarageArea"] * dataset["SimplGarageQual"]
# Simplified overall fireplace score
dataset["SimplFireplaceScore"] = dataset["Fireplaces"] * dataset["SimplFireplaceQu"]
# Simplified overall kitchen score
dataset["SimplKitchenScore"] = dataset["KitchenAbvGr"] * dataset["SimplKitchenQual"]
# Total number of bathrooms
dataset["TotalBath"] = dataset["BsmtFullBath"] + (0.5 * dataset["BsmtHalfBath"]) + \
dataset["FullBath"] + (0.5 * dataset["HalfBath"])
# Total SF for house (incl. basement)
dataset["AllSF"] = dataset["GrLivArea"] + dataset["TotalBsmtSF"]
# Total SF for 1st + 2nd floors
dataset["AllFlrsSF"] = dataset["1stFlrSF"] + dataset["2ndFlrSF"]
# Total SF for porch
dataset["AllPorchSF"] = dataset["OpenPorchSF"] + dataset["EnclosedPorch"] + \
dataset["3SsnPorch"] + dataset["ScreenPorch"]
# Has masonry veneer or not
dataset["HasMasVnr"] = dataset.MasVnrType.replace({"BrkCmn" : 1, "BrkFace" : 1, "CBlock" : 1,
"Stone" : 1, "None" : 0})
# House completed before sale or not
dataset["BoughtOffPlan"] = dataset.SaleCondition.replace({"Abnorml" : 0, "Alloca" : 0, "AdjLand" : 0,
"Family" : 0, "Normal" : 0, "Partial" : 1})
return dataset
train = new_feature(train)
train.head()
test_new = new_feature(test_new)
test_new.head()
all_data = new_feature(all_data)
all_data.head()
# 找到最重要的字段
# Find most important features relative to target
print("Find most important features relative to target")
corr = train.corr()
corr.sort_values(["SalePrice"], ascending = False, inplace = True)
print(corr.SalePrice)
输出内容:
Find most important features relative to target
SalePrice 1.000
OverallQual 0.819
AllSF 0.817
AllFlrsSF 0.729
GrLivArea 0.719
SimplOverallQual 0.708
ExterQual 0.681
GarageCars 0.680
TotalBath 0.673
KitchenQual 0.667
GarageArea 0.655
BsmtQual 0.653
TotalBsmtSF 0.642
SimplExterQual 0.636
GarageScore 0.618
1stFlrSF 0.614
SimplKitchenQual 0.610
OverallGrade 0.604
FullBath 0.591
YearBuilt 0.589
ExterGrade 0.587
SimplGarageScore 0.585
SimplBsmtQual 0.578
YearRemodAdd 0.569
GarageYrBlt 0.544
TotRmsAbvGrd 0.533
SimplOverallGrade 0.527
SimplKitchenScore 0.523
SimplExterGrade 0.488
Fireplaces 0.487
...
GarageQual 0.192
GarageGrade 0.184
GarageCond 0.172
PoolQC 0.164
SimplFunctional 0.137
Functional 0.136
ScreenPorch 0.124
SimplPoolQC 0.122
SimplBsmtCond 0.104
Street 0.058
3SsnPorch 0.056
ExterCond 0.051
SimplGarageQual 0.047
PoolArea 0.041
Utilities 0.013
BsmtFinSF2 0.006
SimplGarageCond -0.015
BsmtHalfBath -0.015
MiscVal -0.020
SimplBsmtFinType2 -0.020
SimplOverallCond -0.028
BsmtFinType2 -0.030
YrSold -0.034
OverallCond -0.037
LowQualFinSF -0.038
LandSlope -0.040
SimplExterCond -0.042
KitchenAbvGr -0.148
EnclosedPorch -0.149
LotShape -0.286
Name: SalePrice, dtype: float64
def poly_feature(dataset):
# Create new features
# 3* Polynomials on the top 10 existing features
dataset["OverallQual-s2"] = dataset["OverallQual"] ** 2
dataset["OverallQual-s3"] = dataset["OverallQual"] ** 3
dataset["OverallQual-Sq"] = np.sqrt(dataset["OverallQual"])
dataset["AllSF-2"] = dataset["AllSF"] ** 2
dataset["AllSF-3"] = dataset["AllSF"] ** 3
dataset["AllSF-Sq"] = np.sqrt(dataset["AllSF"])
dataset["AllFlrsSF-2"] = dataset["AllFlrsSF"] ** 2
dataset["AllFlrsSF-3"] = dataset["AllFlrsSF"] ** 3
dataset["AllFlrsSF-Sq"] = np.sqrt(dataset["AllFlrsSF"])
dataset["GrLivArea-2"] = dataset["GrLivArea"] ** 2
dataset["GrLivArea-3"] = dataset["GrLivArea"] ** 3
dataset["GrLivArea-Sq"] = np.sqrt(dataset["GrLivArea"])
dataset["SimplOverallQual-s2"] = dataset["SimplOverallQual"] ** 2
dataset["SimplOverallQual-s3"] = dataset["SimplOverallQual"] ** 3
dataset["SimplOverallQual-Sq"] = np.sqrt(dataset["SimplOverallQual"])
dataset["ExterQual-2"] = dataset["ExterQual"] ** 2
dataset["ExterQual-3"] = dataset["ExterQual"] ** 3
dataset["ExterQual-Sq"] = np.sqrt(dataset["ExterQual"])
dataset["GarageCars-2"] = dataset["GarageCars"] ** 2
dataset["GarageCars-3"] = dataset["GarageCars"] ** 3
dataset["GarageCars-Sq"] = np.sqrt(dataset["GarageCars"])
dataset["TotalBath-2"] = dataset["TotalBath"] ** 2
dataset["TotalBath-3"] = dataset["TotalBath"] ** 3
dataset["TotalBath-Sq"] = np.sqrt(dataset["TotalBath"])
dataset["KitchenQual-2"] = dataset["KitchenQual"] ** 2
dataset["KitchenQual-3"] = dataset["KitchenQual"] ** 3
dataset["KitchenQual-Sq"] = np.sqrt(dataset["KitchenQual"])
dataset["GarageScore-2"] = dataset["GarageScore"] ** 2
dataset["GarageScore-3"] = dataset["GarageScore"] ** 3
dataset["GarageScore-Sq"] = np.sqrt(dataset["GarageScore"])
return dataset
train = poly_feature(train)
train.head()
test_new = poly_feature(test_new)
test_new.head()
all_data = poly_feature(all_data)
all_data.head()
# train
# 区分数值特征(减去目标)和分类特征
# Differentiate numerical features (minus the target) and categorical features
categorical_features = train.select_dtypes(include = ["object"]).columns
numerical_features = train.select_dtypes(exclude = ["object"]).columns
numerical_features = numerical_features.drop("SalePrice")
print("Numerical features : " + str(len(numerical_features)))
print("Categorical features : " + str(len(categorical_features)))
train_num = train[numerical_features]
train_cat = train[categorical_features]
--Numerical features : 118
--Categorical features : 25
因为有第一列ID
# test_new
# Differentiate numerical features (minus the target) and categorical features
categorical_features = test_new.select_dtypes(include = ["object"]).columns
numerical_features = test_new.select_dtypes(exclude = ["object"]).columns
# numerical_features = numerical_features.drop("SalePrice")
print("Numerical features : " + str(len(numerical_features)))
print("Categorical features : " + str(len(categorical_features)))
test_new_num = test_new[numerical_features]
test_new_cat = test_new[categorical_features]
--Numerical features : 120
--Categorical features : 24
# all_data
# Differentiate numerical features (minus the target) and categorical features
categorical_features = all_data.select_dtypes(include = ["object"]).columns
numerical_features = all_data.select_dtypes(exclude = ["object"]).columns
# numerical_features = numerical_features.drop("SalePrice")
print("Numerical features : " + str(len(numerical_features)))
print("Categorical features : " + str(len(categorical_features)))
all_data_num = all_data[numerical_features]
all_data_cat = all_data[categorical_features]
--Numerical features : 117
--Categorical features : 26
# Handle remaining missing values for numerical features by using median as replacement
print("NAs for numerical features in train : " + str(train_num.isnull().values.sum()))
train_num = train_num.fillna(train_num.median())
print("Remaining NAs for numerical features in train : " + str(train_num.isnull().values.sum()))
--NAs for numerical features in train : 11431
--Remaining NAs for numerical features in train : 0
# Handle remaining missing values for numerical features by using median as replacement
print("NAs for numerical features in test_new : " + str(test_new_num.isnull().values.sum()))
test_new_num = test_new_num.fillna(test_new_num.median())
print("Remaining NAs for numerical features in test_new : " + str(test_new_num.isnull().values.sum()))
--NAs for numerical features in test_new : 85
--Remaining NAs for numerical features in test_new : 0
# Handle remaining missing values for numerical features by using median as replacement
print("NAs for numerical features in all_data : " + str(all_data_num.isnull().values.sum()))
all_data_num = all_data_num.fillna(all_data_num.median())
print("Remaining NAs for numerical features in all_data : " + str(all_data_num.isnull().values.sum()))
--NAs for numerical features in all_data : 166
--Remaining NAs for numerical features in all_data : 0
# 对变量数值特征进行Log变换,以减少异常值的影响
# 由Alexandru Papiu的脚本启发:https://www.kaggle.com/apapiu/house-prices-advanced-regression-techniques/regularized-linear-models
# 作为一般的经验法则,绝对值> 0.5的偏度被认为至少适度地偏斜
# Log transform of the skewed numerical features to lessen impact of outliers
# Inspired by Alexandru Papiu's script : https://www.kaggle.com/apapiu/house-prices-advanced-regression-techniques/regularized-linear-models
# As a general rule of thumb, a skewness with an absolute value > 0.5 is considered at least moderately skewed
skewness = train_num.apply(lambda x: skew(x))
skewness = skewness[abs(skewness) > 0.5]
print(str(skewness.shape[0]) + " skewed numerical features to log transform")
skewed_features = skewness.index
train_num[skewed_features] = np.log1p(train_num[skewed_features])
--87 skewed numerical features to log transform
# Log transform of the skewed numerical features to lessen impact of outliers
# Inspired by Alexandru Papiu's script : https://www.kaggle.com/apapiu/house-prices-advanced-regression-techniques/regularized-linear-models
# As a general rule of thumb, a skewness with an absolute value > 0.5 is considered at least moderately skewed
skewness = test_new_num.apply(lambda x: skew(x))
skewness = skewness[abs(skewness) > 0.5]
print(str(skewness.shape[0]) + " skewed numerical features to log transform")
skewed_features = skewness.index
test_new_num[skewed_features] = np.log1p(test_new_num[skewed_features])
--87 skewed numerical features to log transform
# Log transform of the skewed numerical features to lessen impact of outliers
# Inspired by Alexandru Papiu's script : https://www.kaggle.com/apapiu/house-prices-advanced-regression-techniques/regularized-linear-models
# As a general rule of thumb, a skewness with an absolute value > 0.5 is considered at least moderately skewed
skewness = all_data_num.apply(lambda x: skew(x))
skewness = skewness[abs(skewness) > 0.5]
print(str(skewness.shape[0]) + " skewed numerical features to log transform")
skewed_features = skewness.index
all_data_num[skewed_features] = np.log1p(all_data_num[skewed_features])
--86 skewed numerical features to log transform
# 通过单热编码为分类值创建虚拟特征
# Create dummy features for categorical values via one-hot encoding
print("NAs for categorical features in train : " + str(train_cat.isnull().values.sum()))
train_cat = pd.get_dummies(train_cat)
print("Remaining NAs for categorical features in train : " + str(train_cat.isnull().values.sum()))
--NAs for categorical features in train : 2749
--Remaining NAs for categorical features in train : 0
# Create dummy features for categorical values via one-hot encoding
print("NAs for categorical features in test_new : " + str(test_new_cat.isnull().values.sum()))
test_new_cat = pd.get_dummies(test_new_cat)
print("Remaining NAs for categorical features in test_new : " + str(test_new_cat.isnull().values.sum()))
--NAs for categorical features in test_new : 7
--Remaining NAs for categorical features in test_new : 0
# Create dummy features for categorical values via one-hot encoding
print("NAs for categorical features in all_data : " + str(all_data_cat.isnull().values.sum()))
all_data_cat = pd.get_dummies(all_data_cat)
print("Remaining NAs for categorical features in all_data : " + str(all_data_cat.isnull().values.sum()))
--NAs for categorical features in all_data : 8
--Remaining NAs for categorical features in all_data : 0
test_new.head()
# 合并分类和数值特性
# Join categorical and numerical features
train = pd.concat([train_num, train_cat], axis = 1)
print("New number of features : " + str(train.shape[1]))
--New number of features : 295
# Join categorical and numerical features
test_new = pd.concat([test_new_num, test_new_cat], axis = 1)
print("New number of features : " + str(test_new.shape[1]))
--New number of features : 281
# Join categorical and numerical features
all_data = pd.concat([all_data_num, all_data_cat], axis = 1)
print("New number of features : " + str(all_data.shape[1]))
--New number of features : 320
test_new.head()
train.shape[0]
--1456
train = all_data[:train.shape[0]]
test = all_data[train.shape[0]:]
y.head()
输出:
0 12.248
1 12.109
2 12.317
3 11.849
4 12.429
Name: SalePrice, dtype: float64
#分割数据集
# Partition the dataset in train + validation sets
X_train, X_test, y_train, y_test = train_test_split(train, y, test_size = 0.3, random_state = 0)
print("X_train : " + str(X_train.shape))
print("X_test : " + str(X_test.shape))
print("y_train : " + str(y_train.shape))
print("y_test : " + str(y_test.shape))
X_train : (1022, 295)
X_test : (438, 295)
y_train : (1022,)
y_test : (438,)
# Partition the dataset in train + validation sets
X_train, X_test, y_train, y_test = train_test_split(train, y, test_size = 0.3, random_state = 0)
print("X_train : " + str(X_train.shape))
print("X_test : " + str(X_test.shape))
print("y_train : " + str(y_train.shape))
print("y_test : " + str(y_test.shape))
X_train : (1019, 320)
X_test : (437, 320)
y_train : (1019,)
y_test : (437,)
# 标准化数值特性
# Standardize numerical features
stdSc = StandardScaler()
X_train.loc[:, numerical_features] = stdSc.fit_transform(X_train.loc[:, numerical_features])
X_test.loc[:, numerical_features] = stdSc.transform(X_test.loc[:, numerical_features])
# 定义官方评分的误差度量:RMSE
# Define error measure for official scoring : RMSE
scorer = make_scorer(mean_squared_error, greater_is_better = False)
def rmse_cv_train(model):
rmse= np.sqrt(-cross_val_score(model, X_train, y_train, scoring = scorer, cv = 10))
return(rmse)
def rmse_cv_test(model):
rmse= np.sqrt(-cross_val_score(model, X_test, y_test, scoring = scorer, cv = 10))
return(rmse)
# Linear Regression
lr = LinearRegression()
lr.fit(X_train, y_train)
# 看看训练和验证集的预测
# Look at predictions on training and validation set
print("RMSE on Training set :", rmse_cv_train(lr).mean())
print("RMSE on Test set :", rmse_cv_test(lr).mean())
y_train_pred = lr.predict(X_train)
y_test_pred = lr.predict(X_test)
# 绘制残差
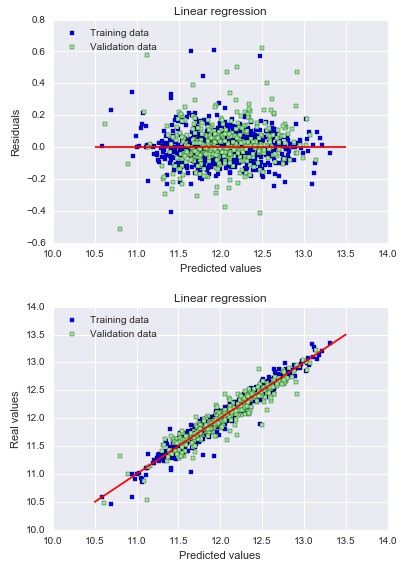
# Plot residuals
plt.scatter(y_train_pred, y_train_pred - y_train, c = "blue", marker = "s", label = "Training data")
plt.scatter(y_test_pred, y_test_pred - y_test, c = "lightgreen", marker = "s", label = "Validation data")
plt.title("Linear regression")
plt.xlabel("Predicted values")
plt.ylabel("Residuals")
plt.legend(loc = "upper left")
plt.hlines(y = 0, xmin = 10.5, xmax = 13.5, color = "red")
plt.show()
# 绘制预测
# Plot predictions
plt.scatter(y_train_pred, y_train, c = "blue", marker = "s", label = "Training data")
plt.scatter(y_test_pred, y_test, c = "lightgreen", marker = "s", label = "Validation data")
plt.title("Linear regression")
plt.xlabel("Predicted values")
plt.ylabel("Real values")
plt.legend(loc = "upper left")
plt.plot([10.5, 13.5], [10.5, 13.5], c = "red")
plt.show()
--('RMSE on Training set :', 0.2994379109222855)
--('RMSE on Test set :', 0.38449735311625766)
# 2* Ridge
ridge = RidgeCV(alphas = [0.01, 0.03, 0.06, 0.1, 0.3, 0.6, 1, 3, 6, 10, 30, 60])
ridge.fit(X_train, y_train)
alpha = ridge.alpha_
print("Best alpha :", alpha)
print("Try again for more precision with alphas centered around " + str(alpha))
ridge = RidgeCV(alphas = [alpha * .6, alpha * .65, alpha * .7, alpha * .75, alpha * .8, alpha * .85,
alpha * .9, alpha * .95, alpha, alpha * 1.05, alpha * 1.1, alpha * 1.15,
alpha * 1.25, alpha * 1.3, alpha * 1.35, alpha * 1.4],
cv = 10)
ridge.fit(X_train, y_train)
alpha = ridge.alpha_
print("Best alpha :", alpha)
print("Ridge RMSE on Training set :", rmse_cv_train(ridge).mean())
print("Ridge RMSE on Test set :", rmse_cv_test(ridge).mean())
y_train_rdg = ridge.predict(X_train)
y_test_rdg = ridge.predict(X_test)
# Plot residuals
plt.scatter(y_train_rdg, y_train_rdg - y_train, c = "blue", marker = "s", label = "Training data")
plt.scatter(y_test_rdg, y_test_rdg - y_test, c = "lightgreen", marker = "s", label = "Validation data")
plt.title("Linear regression with Ridge regularization")
plt.xlabel("Predicted values")
plt.ylabel("Residuals")
plt.legend(loc = "upper left")
plt.hlines(y = 0, xmin = 10.5, xmax = 13.5, color = "red")
plt.show()
# Plot predictions
plt.scatter(y_train_rdg, y_train, c = "blue", marker = "s", label = "Training data")
plt.scatter(y_test_rdg, y_test, c = "lightgreen", marker = "s", label = "Validation data")
plt.title("Linear regression with Ridge regularization")
plt.xlabel("Predicted values")
plt.ylabel("Real values")
plt.legend(loc = "upper left")
plt.plot([10.5, 13.5], [10.5, 13.5], c = "red")
plt.show()
# 绘制重要系数
# Plot important coefficients
coefs = pd.Series(ridge.coef_, index = X_train.columns)
print("Ridge picked " + str(sum(coefs != 0)) + " features and eliminated the other " + \
str(sum(coefs == 0)) + " features")
imp_coefs = pd.concat([coefs.sort_values().head(10),
coefs.sort_values().tail(10)])
imp_coefs.plot(kind = "barh")
plt.title("Coefficients in the Ridge Model")
plt.show()
--('Best alpha :', 30.0)
--Try again for more precision with alphas centered around 30.0
--('Best alpha :', 22.5)
--('Ridge RMSE on Training set :', 0.11517100992467055)
--('Ridge RMSE on Test set :', 0.11636013229778504)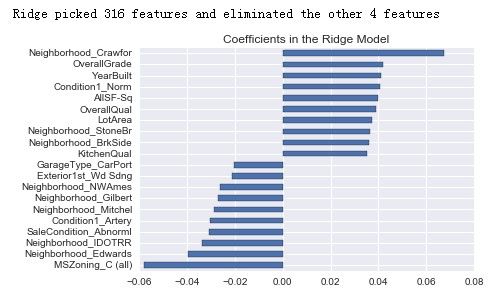
# 3* Lasso
lasso = LassoCV(alphas = [0.0001, 0.0003, 0.0006, 0.001, 0.003, 0.006, 0.01, 0.03, 0.06, 0.1,
0.3, 0.6, 1],
max_iter = 50000, cv = 10)
lasso.fit(X_train, y_train)
alpha = lasso.alpha_
print("Best alpha :", alpha)
print("Try again for more precision with alphas centered around " + str(alpha))
lasso = LassoCV(alphas = [alpha * .6, alpha * .65, alpha * .7, alpha * .75, alpha * .8,
alpha * .85, alpha * .9, alpha * .95, alpha, alpha * 1.05,
alpha * 1.1, alpha * 1.15, alpha * 1.25, alpha * 1.3, alpha * 1.35,
alpha * 1.4],
max_iter = 50000, cv = 10)
lasso.fit(X_train, y_train)
alpha = lasso.alpha_
print("Best alpha :", alpha)
print("Lasso RMSE on Training set :", rmse_cv_train(lasso).mean())
print("Lasso RMSE on Test set :", rmse_cv_test(lasso).mean())
y_train_las = lasso.predict(X_train)
y_test_las = lasso.predict(X_test)
# Plot residuals
plt.scatter(y_train_las, y_train_las - y_train, c = "blue", marker = "s", label = "Training data")
plt.scatter(y_test_las, y_test_las - y_test, c = "lightgreen", marker = "s", label = "Validation data")
plt.title("Linear regression with Lasso regularization")
plt.xlabel("Predicted values")
plt.ylabel("Residuals")
plt.legend(loc = "upper left")
plt.hlines(y = 0, xmin = 10.5, xmax = 13.5, color = "red")
plt.show()
# Plot predictions
plt.scatter(y_train_las, y_train, c = "blue", marker = "s", label = "Training data")
plt.scatter(y_test_las, y_test, c = "lightgreen", marker = "s", label = "Validation data")
plt.title("Linear regression with Lasso regularization")
plt.xlabel("Predicted values")
plt.ylabel("Real values")
plt.legend(loc = "upper left")
plt.plot([10.5, 13.5], [10.5, 13.5], c = "red")
plt.show()
# Plot important coefficients
coefs = pd.Series(lasso.coef_, index = X_train.columns)
print("Lasso picked " + str(sum(coefs != 0)) + " features and eliminated the other " + \
str(sum(coefs == 0)) + " features")
imp_coefs = pd.concat([coefs.sort_values().head(10),
coefs.sort_values().tail(10)])
imp_coefs.plot(kind = "barh")
plt.title("Coefficients in the Lasso Model")
plt.show()
--('Best alpha :', 0.00059999999999999995)
--Try again for more precision with alphas centered around 0.0006
--('Best alpha :', 0.00059999999999999995)
--('Lasso RMSE on Training set :', 0.11403954212405014)
--('Lasso RMSE on Test set :', 0.11585280771533035)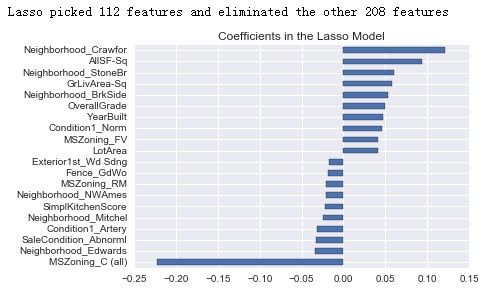
X_train.head()
X_test.head()
test.head()
y_pred_lasso = lasso.predict(test)
y_pred_lasso
--array([ 90.59653003, 62.86892549, 74.88361726, ..., 81.39766545,
39.54093941, 87.80713916])
y_pred_lasso = np.exp(y_pred_lasso)
y_pred_lasso
--array([ 2.21601691e+39, 2.01199745e+27, 3.32308738e+32, ...,
2.24159394e+35, 1.48734526e+17, 1.36193383e+38])
pred_df = pd.DataFrame(y_pred_lasso, index=test_new["Id"], columns=["SalePrice"])
pred_df.to_csv('output.csv', header=True, index_label='Id')
# Get data
test_data = pd.read_csv("test.csv")
print("test : " + str(test_data.shape))
pred_df = pd.DataFrame(y_pred_lasso, index=test_data["Id"], columns=["SalePrice"])
pred_df.to_csv('output_lasso.csv', header=True, index_label='Id')