李宏毅学习笔记34.GAN.05.fGAN: General Framework of GAN
文章目录
- 简介
- f-divergence
- Fenchel Conjugate
- Connection with GAN
- Mode Collapse
- Mode Dropping
- 问题分析
- 解决Mode Collapse
简介
上节在讲原文GAN的时候,提到我们实际是在用Discriminator来衡量两个数据的分布之间的JS divergence,那能不能是其他类型的divergence来衡量真实数据和生成数据之间的差距?又如何进行衡量?(虽然在实作上用不同divergence结果没有很大差别)
公式输入请参考:在线Latex公式
f-divergence
任意的divergence都可以用来衡量真实数据和生成数据之间的差距,用f-divergence进行衡量的算法就叫fGAN。先来看看f-divergence的概念:
P P P and Q Q Q are two distributions. p ( x ) p(x) p(x) and q ( x ) q(x) q(x) are the probability of sampling x x x.
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) f ( p ( x ) q ( x ) ) d x , f is convex, f ( 1 ) = 0 D_f(P||Q)=\int_xq(x)f\left(\cfrac{p(x)}{q(x)}\right)dx,\text{f is convex, }f(1)=0 Df(P∣∣Q)=∫xq(x)f(q(x)p(x))dx,f is convex, f(1)=0
如果两个分布相同,那么f-divergence的值应该相等,我们来验证一下:
当 p ( x ) = q ( x ) for all x p(x)=q(x) \text{ for all } x p(x)=q(x) for all x
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) f ( p ( x ) q ( x ) ) d x = 0 D_f(P||Q)=\int_xq(x)f\left(\cfrac{p(x)}{q(x)}\right)dx=0 Df(P∣∣Q)=∫xq(x)f(q(x)p(x))dx=0
因为: p ( x ) q ( x ) = 1 , f ( 1 ) = 0 \cfrac{p(x)}{q(x)}=1,f(1)=0 q(x)p(x)=1,f(1)=0,所以divergence为0,是最小的f-divergence。证明如下:
Because f is convex,因此有(右边是左边的lower bound):
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) f ( p ( x ) q ( x ) ) d x ≥ f ( ∫ x q ( x ) p ( x ) q ( x ) d x ) D_f(P||Q)=\int_xq(x)f\left(\cfrac{p(x)}{q(x)}\right)dx\ge f\left(\int_xq(x)\cfrac{p(x)}{q(x)}dx\right) Df(P∣∣Q)=∫xq(x)f(q(x)p(x))dx≥f(∫xq(x)q(x)p(x)dx)
f ( ∫ x q ( x ) p ( x ) q ( x ) d x ) = f ( ∫ x p ( x ) d x ) = f ( 1 ) = 0 f\left(\int_xq(x)\cfrac{p(x)}{q(x)}dx\right)=f\left(\int_xp(x)dx\right)=f(1)=0 f(∫xq(x)q(x)p(x)dx)=f(∫xp(x)dx)=f(1)=0
如果 f f f是不同的函数,就得到不同的divergence,例如: f ( x ) = x l o g x f(x)=xlogx f(x)=xlogx
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) p ( x ) q ( x ) l o g ( p ( x ) q ( x ) ) d x = ∫ x p ( x ) l o g ( p ( x ) q ( x ) ) d x D_f(P||Q)=\int_xq(x)\cfrac{p(x)}{q(x)}log\left(\cfrac{p(x)}{q(x)}\right)dx\\ =\int_xp(x)log\left(\cfrac{p(x)}{q(x)}\right)dx Df(P∣∣Q)=∫xq(x)q(x)p(x)log(q(x)p(x))dx=∫xp(x)log(q(x)p(x))dx
这个是KL divergence。
例如: f ( x ) = − l o g x f(x)=-logx f(x)=−logx
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) ( − l o g ( p ( x ) q ( x ) ) ) d x = ∫ x q ( x ) l o g ( q ( x ) p ( x ) ) d x D_f(P||Q)=\int_xq(x)\left(-log\left(\cfrac{p(x)}{q(x)}\right)\right)dx\\ =\int_xq(x)log\left(\cfrac{q(x)}{p(x)}\right)dx Df(P∣∣Q)=∫xq(x)(−log(q(x)p(x)))dx=∫xq(x)log(p(x)q(x))dx
这个是Reverse KL divergence。
例如: f ( x ) = ( x − 1 ) 2 f(x)=(x-1)^2 f(x)=(x−1)2
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) ( p ( x ) q ( x ) − 1 ) 2 d x = ∫ x ( p ( x ) − q ( x ) ) 2 q ( x ) d x D_f(P||Q)=\int_xq(x)\left(\cfrac{p(x)}{q(x)}-1\right)^2dx\\ =\int_x\cfrac{\left(p(x)-q(x)\right)^2}{q(x)}dx Df(P∣∣Q)=∫xq(x)(q(x)p(x)−1)2dx=∫xq(x)(p(x)−q(x))2dx
这个是Chi Square divergence。
Fenchel Conjugate
每一个 f f f凸函数都有一个Conjugate函数记为 f ∗ f^* f∗,公式如下:
f ∗ ( t ) = max x ∈ d o m ( f ) { x t − f ( x ) } f^*(t)=\underset{x\in dom(f)}{\text{max}}\{xt-f(x)\} f∗(t)=x∈dom(f)max{xt−f(x)}
穷举所有的 t , x t,x t,x,然后找到能使得 x t − f ( x ) xt-f(x) xt−f(x)最大的 t , x t,x t,x。
比较笨的穷举法如下:

另外一种方法:函数 x t − f ( x ) xt-f(x) xt−f(x)是直线,我们带不同的 x x x得到不同的直线,例如下面有三条直线:
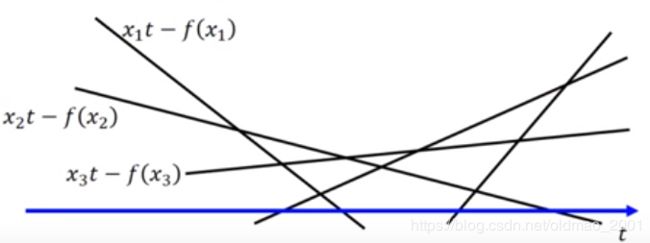
然后找不同的t对应的最大值。(就是所有直线的upper bound)
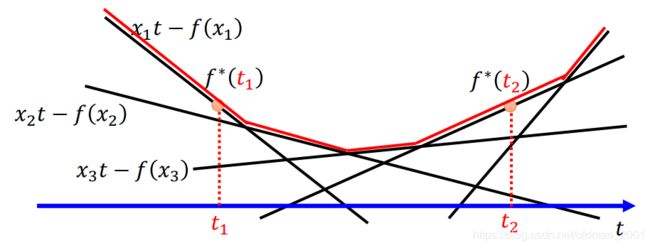
上面的红线无论你如何画,最后都是convex的。
看例子,假设: f ( x ) = x l o g x f(x)=xlogx f(x)=xlogx,把 x = 0.1 , x = 1 , x = 10 x=0.1,x=1,x=10 x=0.1,x=1,x=10,图片如下:
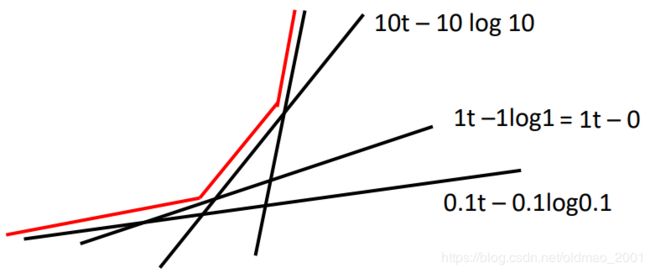
红线最后接近
f ∗ ( t ) = e x p ( t − 1 ) f^*(t)=exp(t-1) f∗(t)=exp(t−1)
下面是数学证明,假设 f ( x ) = x l o g x f(x)=xlogx f(x)=xlogx
则:
f ∗ ( t ) = max x ∈ d o m ( f ) { x t − f ( x ) } = max x ∈ d o m ( f ) { x t − x l o g x } (1) f^*(t)=\underset{x\in dom(f)}{\text{max}}\{xt-f(x)\}=\underset{x\in dom(f)}{\text{max}}\{xt-xlogx\}\tag1 f∗(t)=x∈dom(f)max{xt−f(x)}=x∈dom(f)max{xt−xlogx}(1)
令上式中 x t − x l o g x = g ( x ) , Given t , find x maximizing g ( x ) xt-xlogx=g(x)\text{, Given }t\text{, find }x\text{ maximizing }g(x) xt−xlogx=g(x), Given t, find x maximizing g(x)
求极值,就是对 x x x求导数等于0:
g ′ ( x ) = t − l o g x − 1 = 0 x = e x p ( t − 1 ) g'(x)=t-logx-1=0\\ x=exp(t-1) g′(x)=t−logx−1=0x=exp(t−1)
把上面内容代入公式(1):
f ∗ ( t ) = x t − x l o g x = e x p ( t − 1 ) × t − e x p ( t − 1 ) × ( t − 1 ) = e x p ( t − 1 ) f^*(t)=xt-xlogx=exp(t-1)\times t-exp(t-1)\times(t-1)=exp(t-1) f∗(t)=xt−xlogx=exp(t−1)×t−exp(t−1)×(t−1)=exp(t−1)
一般化后:
( f ∗ ) ∗ = f (f^*)^*=f (f∗)∗=f
讲这么多,下面看下上面两节内容和GAN的关系
Connection with GAN
通过上面的推导我们知道 f ∗ ( t ) f^*(t) f∗(t)和 f ( x ) f(x) f(x)互为Conjugate,写为:
f ∗ ( t ) = max x ∈ d o m ( f ) { x t − f ( x ) } ← → f ( x ) = max t ∈ d o m ( f ∗ ) { x t − f ∗ ( t ) } f^*(t)=\underset{x\in dom(f)}{\text{max}}\{xt-f(x)\}\leftarrow\rightarrow f(x)=\underset{t\in dom(f^*)}{\text{max}}\{xt-f^*(t)\} f∗(t)=x∈dom(f)max{xt−f(x)}←→f(x)=t∈dom(f∗)max{xt−f∗(t)}
这两个相互Conjugate的convex的函数有什么特别?我们继续看。
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) f ( p ( x ) q ( x ) ) d x = ∫ x q ( x ) ( max t ∈ d o m ( f ∗ ) { p ( x ) q ( x ) t − f ∗ ( t ) } ) d x D_f(P||Q)=\int_xq(x)f\left(\cfrac{p(x)}{q(x)}\right)dx\\ =\int_xq(x)\left(\underset{t\in dom(f^*)}{\text{max}}\left\{\cfrac{p(x)}{q(x)}t-f^*(t)\right\}\right)dx Df(P∣∣Q)=∫xq(x)f(q(x)p(x))dx=∫xq(x)(t∈dom(f∗)max{q(x)p(x)t−f∗(t)})dx
我们用函数 D ( x ) D(x) D(x)代替 t t t,使得输入x,输出为t,使得上面{}中的值最大,替换后,就找到了 D f ( P ∣ ∣ Q ) D_f(P||Q) Df(P∣∣Q)的lower bound
D f ( P ∣ ∣ Q ) ≥ ∫ x q ( x ) ( p ( x ) q ( x ) D ( x ) − f ∗ ( D ( x ) ) ) d x = ∫ x p ( x ) D ( x ) d x − ∫ x q ( x ) f ∗ ( D ( x ) ) d x D_f(P||Q)\ge\int_xq(x)\left(\cfrac{p(x)}{q(x)}D(x)-f^*(D(x))\right)dx\\ =\int_xp(x)D(x)dx-\int_xq(x)f^*(D(x))dx Df(P∣∣Q)≥∫xq(x)(q(x)p(x)D(x)−f∗(D(x)))dx=∫xp(x)D(x)dx−∫xq(x)f∗(D(x))dx
当我们找的函数 D ( x ) D(x) D(x)是最好的,那么就可以逼近 D f ( P ∣ ∣ Q ) D_f(P||Q) Df(P∣∣Q)
D f ( P ∣ ∣ Q ) ≈ max D ∫ x p ( x ) D ( x ) d x − ∫ x q ( x ) f ∗ ( D ( x ) ) d x D_f(P||Q)\approx\underset{D}{\text{max}}\int_xp(x)D(x)dx-\int_xq(x)f^*(D(x))dx Df(P∣∣Q)≈Dmax∫xp(x)D(x)dx−∫xq(x)f∗(D(x))dx
积分可以写成期望值:
= max D { E x ∼ P [ D ( x ) ] − E x ∼ Q [ f ∗ ( D ( x ) ) ] } =\underset{D}{\text{max}}\{E_{x\sim P}[D(x)]-E_{x\sim Q}[f^*(D(x))]\} =Dmax{Ex∼P[D(x)]−Ex∼Q[f∗(D(x))]}
接下来我们把 P = P d a t a , Q = P G P=P_{data},Q=P_G P=Pdata,Q=PG,则有:
D f ( P d a t a ∣ ∣ P G ) = max D { E x ∼ P d a t a [ D ( x ) ] − E x ∼ P G [ f ∗ ( D ( x ) ) ] } D_f(P_{data}||P_G)=\underset{D}{\text{max}}\{E_{x\sim P_{data}}[D(x)]-E_{x\sim P_G}[f^*(D(x))]\} Df(Pdata∣∣PG)=Dmax{Ex∼Pdata[D(x)]−Ex∼PG[f∗(D(x))]}
把上面的式子可以带回求Generator的公式:
G ∗ = a r g min G D f ( P d a t a ∣ ∣ P G ) = a r g min G max D { E x ∼ P d a t a [ D ( x ) ] − E x ∼ P G [ f ∗ ( D ( x ) ) ] } = a r g min G max D V ( G , D ) \begin{aligned}G^* &=arg\underset{G}{\text{min}}D_f(P_{data}||P_G)\\ &=arg\underset{G}{\text{min}}\underset{D}{\text{max}}\{E_{x\sim P_{data}}[D(x)]-E_{x\sim P_G}[f^*(D(x))]\}\\ &=arg\underset{G}{\text{min}}\underset{D}{\text{max}}V(G,D)\end{aligned} G∗=argGminDf(Pdata∣∣PG)=argGminDmax{Ex∼Pdata[D(x)]−Ex∼PG[f∗(D(x))]}=argGminDmaxV(G,D)
也就是说我们可以优化不同的divergence(https://arxiv.org/pdf/1606.00709.pdf)


可以用来解决Mode Collapse
Mode Collapse
当我们的GAN模型Training with too many iterations……
有些人脸就会比较像,除了一些颜色不太一样

从数学上说就是我们的生成对象的分布越来越小了

Mode Dropping
就是真实数据有两簇或者多簇,但是生成数据只能生成其中一簇:

例如下面的人脸,一个循环只有白种人,一个循环只有黄种人,一个循环中只有黑人。

问题分析
传统的做法类似MLE实际上是最小化KL divergence,可以看到生成数据的分布是在真实数据中间,这也是为什么真实数据这么模糊
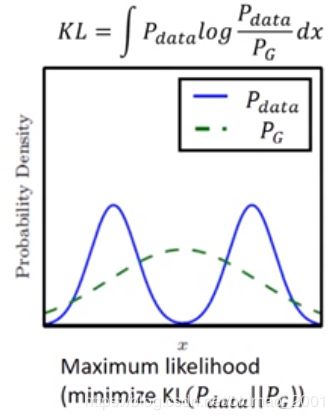
如果换成Reverse KL Divergence:
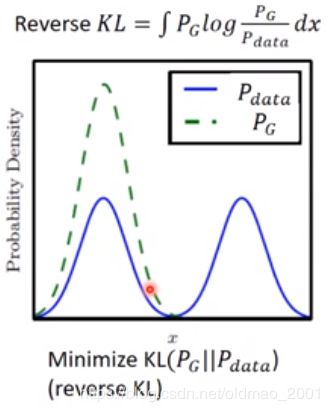
可以看到解决了模糊的问题,但是会出现Mode Dropping的问题。
因此选择不同的divergence对于GAN很重要。
解决Mode Collapse
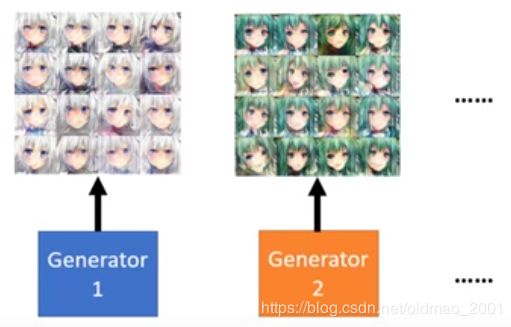
Unsemble:训练多个generator,然后随机调一个generator来生成图片,这样结果就会比较diverse。
Train a set of generators: { G 1 , G 2 , … , G N } \{G_1,G_2,…,G_N\} {G1,G2,…,GN}
To generate an image Random pick a generator G i G_i Gi. Use G i G_i Gi generate the image.