Kaggle - House_Price基础篇
Kaggle - House price 数据处理
Kaggle: House Prices: Advanced Regression Techniques
1,读取数据: 使用pd.read_csv()导入 train_df, test_df数据
2,合并数据:
- label: 使用log1p平滑处理train_df中的label得到[y_train] -> 最后需要用expm1() 变回来
- 提取label: 使用np.pop取出label后期导入模型中测试使用,切记:千万不要动test_df测试数据
- 合并train&test: 使用np.concat合并train_df, test_df得到[all_df],一会预处理使用
3,处理数据中变量:
- 最好不用数字作为标签划分数据,出现歧义: int -> string -> One-hot编码(.get_dummies)->all_df也采用One-hot,列从79列变为303列,得到[all_dummy_df]
- 处理缺失值,这里用平均值代替,看情况处理:.isnull().sum().sort_values(ascending=False) -> .mean() -> .fillna(mean值)
- 标准化数据,看情况使用, 这里对非one-hot列处理, all_df.dtypes != 'object' -> 数值-平均值/方差 -> ok
4, 建立模型:
- Ridge Regression: 导入Ridge & cross_val_score -> 分别获取训练集dummy_train_df & 测试集dummy_test_df,
- 采用多组alpha测试: 使用np.logspace -> 循环调用不同的alpha,得到测试分数,画图 (neg_mean_squared_error) -> 得到error最小的地方
- Random Forest: 导入RandomForestRegressor -> 循环不同max_features, 得到测试分数,画图(neg_mean_squared_error) -> 得到最小的error地方
5,组合模型:
- 使用最好的参数,建立两种模型 ridge & RandomFroestRegressor
- 用两种模型训练,输入数据.fit(X_train, y_train)
- 输入测试数据X_test,得到两组预测结果 -> 这里简单求平均 -> y_final
6,提交结果
- data = pd.DataFrame({'id': test_df.index, 'SalePrice':y_final})
代码如下:
0,导入常用包
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as pltf = '/Users/a1/Desktop/算法实战/house_price_predict/'
os.chdir(f)1,读取数据
train_df = pd.read_csv('train.csv', index_col=0)
test_df = pd.read_csv('test.csv', index_col=0)
train_df.shape
train_df.head()2,合并数据
# 1) 取出SalePrice, label本身并不平滑,我们先让label平滑(正态化),最后记得变回来expm1()
%matplotlib inline
prices = pd.DataFrame({"price":train_df["SalePrice"], "Log(price+1)":np.log1p(train_df["SalePrice"])})
prices.hist()#把train中的y取出来,用pop
y_train = np.log1p(train_df.pop('SalePrice'))# 2)把剩下的部分合起来
#pandas.concat:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.concat.html#pandas.concat
all_df = pd.concat((train_df, test_df), axis=0)all_df.shape
y_train.head()3,变量转化
# 1) 首先,我们注意到,*MSSubClass* 的值其实应该是一个category,
#但是Pandas是不会懂这些事儿的。使用DF的时候,这类数字符号会被默认记成数字。这种东西就很有误导性,我们需要把它变回成*string*
#MSSubClass 本来应为属性,不是int值,查看值的属性
all_df['MSSubClass'].dtypes
#把int格式转换为str格式 -> 然后采用One-hot进行分类去除数字分类的影响
all_df['MSSubClass'] = all_df['MSSubClass'].astype(str)
#all_df['MSSubClass'].dtypes
#转换后,统计以下,value_counts()
all_df['MSSubClass'].value_counts()# 2) 当用数字进行分类时候,数字大小会带来歧义,采用One-Hot方法
#当我们用numerical来表达categorical的时候,要注意,数字本身有大小的含义,所以乱用数字会给之后的模型学习带来麻烦。于是我们可以用One-Hot的方法来表达category。pandas自带的get_dummies方法,可以帮你一键做到One-Hot。
#https://blog.csdn.net/lanchunhui/article/details/72870358, One-Hot
#此刻*MSSubClass*被我们分成了12个column,每一个代表一个category。是就是1,不是就是0。
pd.get_dummies(all_df['MSSubClass'], prefix='MSSubClass').head()
# 3) 把所有的category数据,都给One-Hot
all_dummy_df = pd.get_dummies(all_df)
all_dummy_df.head()# 4) 处理好numerical变量,就算是numerical的变量,也还会有一些小问题。比如,有一些数据是缺失的:
all_dummy_df.isnull().sum().sort_values(ascending=False).head(10)# 5) 标准化数据, 这一步并不是必要,但是得看你想要用的分类器是什么。一般来说,regression的分类器都比较傲娇,最好是把源数据给放在一个标准分布内。不要让数据间的差距太大。
#这一步并不是必要,但是得看你想要用的分类器是什么。一般来说,regression的分类器都比较傲娇,最好是把源数据给放在一个标准分布内。不要让数据间的差距太大。
#这里,我们当然不需要把One-Hot的那些0/1数据给标准化。我们的目标应该是那些本来就是numerical的数据:先来看看 哪些是numerical的:
numeric_cols = all_df.columns[all_df.dtypes != 'object'] #打印出所有数字列,就是不等于‘object’类型
numeric_cols
numeric_col_mean = all_dummy_df.loc[:, numeric_cols].mean() #取所有数字列的平均值
numeric_col_std = all_dummy_df.loc[:, numeric_cols].std() #取所有数字列的方差
all_dummy_df.loc[:, numeric_cols] = (all_dummy_df.loc[:, numeric_cols] - numeric_col_mean)/numeric_col_std #每个数字减去均值,再除以方差
all_dummy_df.head()# 6) 处理这些缺失的信息,得靠好好审题。一般来说,数据集的描述里会写的很清楚,这些缺失都代表着什么。当然,如果实在没有的话,也只能靠自己的『想当然』。。在这里,我们用平均值来填满这些空缺。mean_cols = all_dummy_df.mean()mean_cols.head(20)all_dummy_df = all_dummy_df.fillna(mean_cols)#填充完成后,看看有没有空缺值了all_dummy_df.isnull().sum().sum()4,建立模型
#1 把数据集分为 训练/测试集
dummy_train_df = all_dummy_df.loc[train_df.index]
dummy_test_df = all_dummy_df.loc[test_df.index]
print(dummy_train_df.shape)
print(dummy_test_df.shape)# Ridge
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
#这一步不是很有必要,把DF转换为Numpy, 配合sklearn
X_train = dummy_train_df.values
X_test = dummy_test_df.values
#https://docs.scipy.org/doc/numpy/reference/generated/numpy.logspace.html
#用sklearn自带的cross validation方法测试
alphas = np.logspace(-3, 2, 50)
test_scores = []
for alpha in alphas:
clf = Ridge(alpha)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=10, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
#画图
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(alphas, test_scores)
plt.title("Alpha vs CV Error");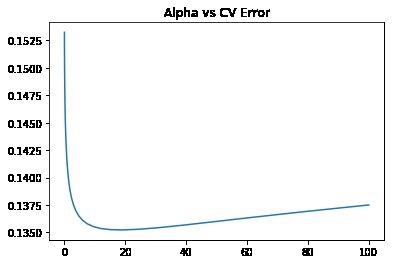
可见,大概alpha=10~20的时候,可以把score达到0.135左右。#Random Forest
from sklearn.ensemble import RandomForestRegressor
max_features = [.1, .3, .5, .7, .9, .99]
text_scores=[]
for max_feat in max_features:
clf = RandomForestRegressor(n_estimators=200, max_features=max_feat)
test_score = np.sqrt(-cross_val_score(clf, X_train, y_train, cv=5, scoring='neg_mean_squared_error'))
test_scores.append(np.mean(test_score))
plt.plot(max_features, test_scores[0:6])
plt.title("Max Features vs CV Error");
#注意这里有一个报错
#ValueError: x and y must have same first dimension, but have shapes (6,) and (12,)
#plt.plot(max_features, test_scores[6:12])
#plt.title("Max Feature vs CV Error");
用RF的最优值达到了0.1375,Ensemble (集成模型)
#这里我们用一个Stacking的思维来汲取两种或者多种模型的优点
#首先,我们把最好的parameter拿出来,做成我们最
终的model
#把刚才的模型最好的参数,代入,新建最好的模型是什么
ridge = Ridge(alpha=15)
rf = RandomForestRegressor(n_estimators=500, max_features=.3)
ridge.fit(X_train, y_train)
rf.fit(X_train, y_train)
#上面提到了,因为最前面我们给label做了个log(1+x), 于是这里我们需要把predit的值给exp回去,并且减掉那个"1",所以就是我们的expm1()函数#这个时候才开始用X_test用来最后使用
y_ridge = np.expm1(ridge.predict(X_test))
y_rf = np.expm1(rf.predict(X_test))
#一个正经的Ensemble是把这群model的预测结果作为新的input,再做一次预测这里我们简单的方法,就是直接『平均化』。
y_final = (y_ridge + y_rf)/2
X_test.shape # 看一下这个test的结构,因为知道test,最终都是药预测房屋价格的6,提交结果
data = pd.DataFrame({'Id': test_df.index, 'SalePrice':y_final})
data.head()
##另一种写法
#pd.DataFrame(data = {'ID': test_df.index, 'SalePrice':y_final}).head()#注意加上.csv
z = 'Users/a1/Desktop/算法实战/house_price_predict'
data.to_csv('z.csv', index=False)