Kafka Broker端设计原理
1.消息详解
消息详解请参考我的另一篇文章 kafka日志详解
2.副本机制
2.1 副本机制的好处
- 1.提供数据冗余
- 副本的第一个好处就是提供数据冗余。
- 2.提供高伸缩性
- 支持横向扩展,并发读,通过提升机器的数量,来增加系统的吞吐量。
- 3.改善局部数据
- 将不同的副本数据放到不同的地点,可以优化每个地点的系统延时
2.2 Kafka副本机制
Kafka副本的专有名词是Replica,Replica 定义,同一个分区的所有副本保存着相同的数据,分散在不同的Broker上,所以首先要知道Replica 是针对分区来说的。
Replica 有两种类型 Leader 和Follower ,其中Kafka对外提供的服务全部都是Ledaer Replica 提供的,Follower Replica仅仅做两件事:
- 1.定时向Leader 拉取数据

-
2.Leader 挂了后去竞选Leader 提供系统的高可用(具体是否有竞选条件是根据配置决定的)。如下图为所一次Leader 竞选的过程,当Leder Replica 所在的Broker 挂机后,Broker与Zookeepeer保持的会话断开,此时Zookeeper会删除当前Broker的临时节点,Controller听过Watch机制进行监听然后通知对应Broker所在的,Follower Replica开始Leader竞选。
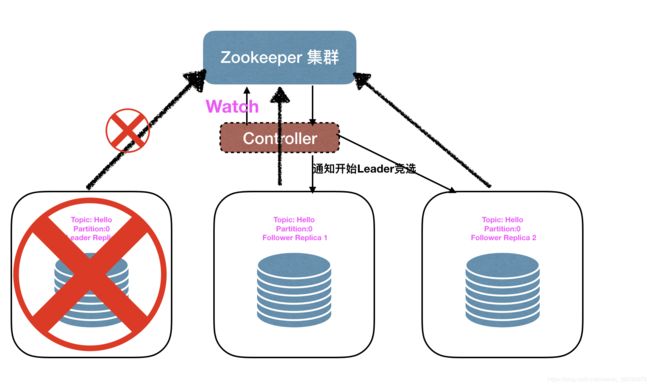
2.3 Leader 选举机制
上文中说到,Kafka的具体是否有竞选条件是根据配置决定的,这个条件就是配置参数unclean.leader.election.enable决定的,如果当前参数的配置为true。就叫做Unclean Leader 选举,如果参数为false就为普通Leader选举。
在此之前还要弄明白这个名词**ISR(In-sync Replica)**大概的意思就是正在同步的副本集合。ISR里边存放的是存活的Leader副本和同步落后Leader副本不是太多的Follower副本。 如果是落后太多的副本就会剔除该副本,当它追上的时候,再添加进副本。
如何去判断Follower Replica 是否落后于Leader Replica 太多,是根据参数replica.lag.time.max.ms决定的,如果Follower Replica 在这个时间后还没有去Leader Replica 去同步数据,就认为该Follower Replica 是不同步的副本,ISR就会剔除它。
弄懂了ISR之后再来看Kafka的选举机制
普通Leader选举:就是仅仅允许ISR中存在的副本进行选举Leader。
**Unclean Leader 选举:**允许所有存活的副本进行Leader选举。
两个的优势劣势显而易见,普通Leader选举更加保证了消息的准确性,而Unclean Leader 选举更加的去保证了系统的高可用性。生产上建议将unclean.leader.election.enable设置为false。
2.4Kafka副本机制的好处
Kafka副本机制仅仅提供了通俗的副本机制所提供的第一个好处,就是仅仅提供了数据的冗余,这是为什么呢?
跟Kafka 特性有关众所周知Kafka作为一个消息引擎,也是消息队列的特性:
-
1.单调读:就是每次读到的数据都是一致的,对于一个消息系统的消费者来说,如果它看到的消息一会是存在的,一会又不存在,显然是不合理的。
-
2.读写同步:当生产者向Kafka写入一条数据的时候,consumer显然是要实时的获取到这条消息才是最合理的。
3.副本同步
Kafka如何进行副本数据同步的,主要是依赖与 HighWater 和Leader Eopch。
3.1HighWater
首先说一下Kafka日志的一些概念
1.Log Start Offset:消息的起始位移
2.Log End Offset(LEO) :下一条消息写入的位移,是不存在的数据。
3.High Water(HW):高水位,高水位以前的数据都是以提交数据,就是消费者可以获取到的数据,以后的数据都是还未提交的数据。这是高水位的第一个作用定义消息的可见性。

高水位(High Water HW)的第二个特性副本同步。
不管是HW还是LEO在Kafka中都有三个种类 Leader 、Remote 、Follower。(如果一个分区有Follower的话,实际的场景也不会不给Leader 副本设置一些Follower 副本)。如下图为某个Topic的一个分区的存储方式。
一共有六个名词:
| -名称- | -介绍- | -更新时机- |
|---|---|---|
| Leader-HW | Leader 高水位 又叫做分区高水位,每个分区的 高水位是要小于 LEO的,而分区高水位还要小于所有的Remote LEO。 | 1.生产者写入数据,更新完Leaer-LEO的值后,更新Leader-HW值。2.Follower副本拉取数据,更新了Remote-LEO的值后更新Leader-HW值 |
| Leader-LEO | Leader 末端位移 | 生产者发送完数据后,更新Leader-LEO值 |
| Rmote-HW | 远程高水位 ,基本没什么用处,不修改。 | 不更新 |
| Remote-LEO | 远程 -LEO,帮助Leader确定分区高水位的值 | Follower 副本拉取数据的时候更新其对应的 Remote-LEO值 |
| Follower-HW | Follower 高水位 | 拉取完Leader副本的数据之后,更新HW,会比较Leader传送过来的HW值和Follower -LEO 进行比较取较小的值作为 Follower-HW |
| Follower-LEO | Follower 末端位移 | 拉取完Leader副本的数据之后,更新LEO |
分区高水位更新公式如下:
leaderHW = max{LeaderHW, min(LEO-0,LEO-1, LEO-2, ……,LEO-n)}
如下图为一次副本同步机制的具体流程。
- 生产者发送了十条消息,此时Leader存储完后,只有L_LEO 变为10
- Follower1和Follower2开始拉取消息FetchRequest请求,传入自己的LEO值,也就是fecch_offset的值。Leader Response 带有的参数就是HW值,然后Followers并分别更新消息,之后更新对应的LEO值。
- 之后Followers回继续发送FecthRequest请求,传入自己最新的LEO值,Leader获取到请求后会更新远程LEO的值,和HW值。
- Leader 返回FecchResponse 带有最新的HW值,Followers用此值来更新自己的HW值,一次副本同步结束。
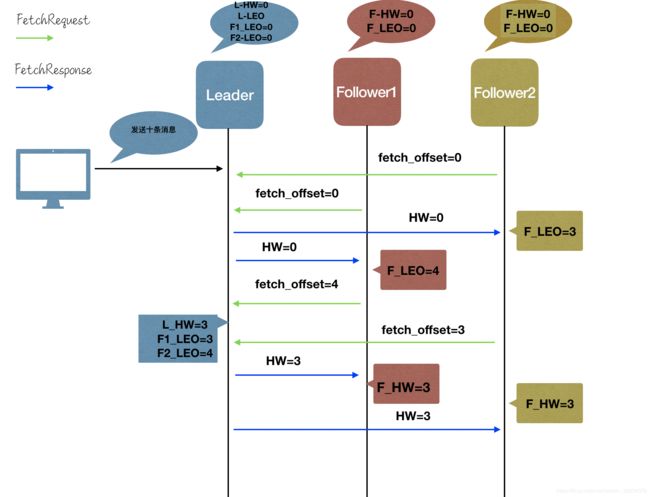
从上图我们可以看出,这样的同步机制是存在缺陷的,因为L_HW和F_HW的更新是明显存在时间错配问题。
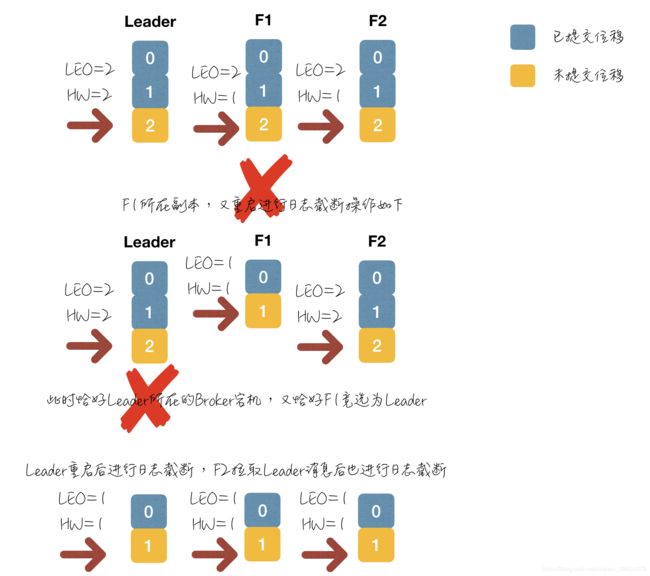
时间错配引起的数据丢失问题:(发生这个问题的前提是 min.insync.replicas=1 也就是消息发送到Leader既认为发送成功)
如图所示,假如F1在等待Leader的FetchRespose请求的过程之重启了,重启后做的事情是
- 进行日志截断操作(根据HW来截断)
- 发送fetchRequest请求
而此时Leader宕机,重启后,F1当选为Leader,发现不用进行日志截断操作,拉取数据发现自己的HW>分区HW,按照分区HW,进行日志截断操作至此,消息就就丢失了。
3.2 Leader Epoch(0.11.0)
针对于上边因为HighWater 更新机制的时间错配造成的问题,Kafka引入了Leder Epoch来规避这种消息丢失的场景,事实证明在引入了Leader Epoch之后kafka关于副本消息不一致的情况改善了很多。
**Leader Epoch:**为每个Topic的分区创建一个类似于如下的数据
Leader Epoch 如何规避数据丢失场景:

利用了Kafka的Leader Epoch 机制,Kafka规避了这种消息丢失的场景,也规避了另外一种场景当A和F1同时宕机的情况下消息不一致的情景。当然向上边的这种场景Leader 和 F1同时宕机,Kafka还是会出现消息丢失的场景。但是相当于之前的HighWater机制已经很大的优化了系统。
如果想要做到消息完全不丢失,那就配置acks=all ,当消息完全写入所有的(ISR中的)副本后才算是同步成功。