推荐系统第四课(用户建模----召回排序都会用到)wide and deep Practice
1 learning to rank 回顾

Learning to Rank for Information Retrieval,Tie-Yan :Liu
https://www.cda.cn/uploadfile/image/20151220/20151220115436_46293.pdf
1分类模型的应用
一、点击预估模型

ad_pv较小的时候考虑到置信度问题,因此选择cate类

模型:
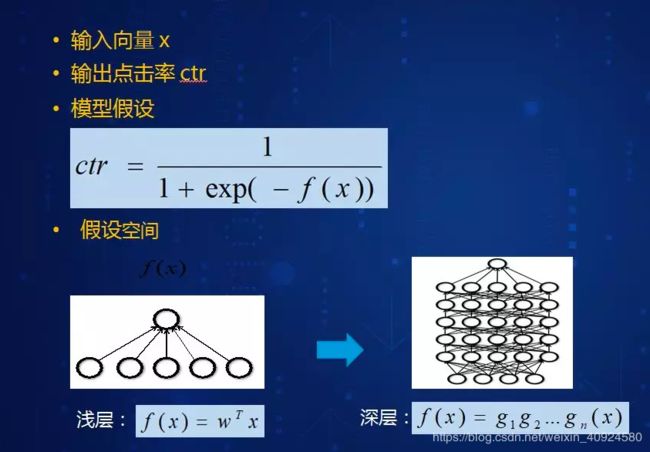
线上CTR预估系统示例
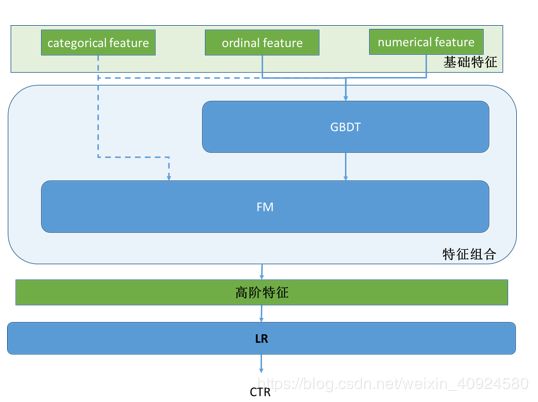
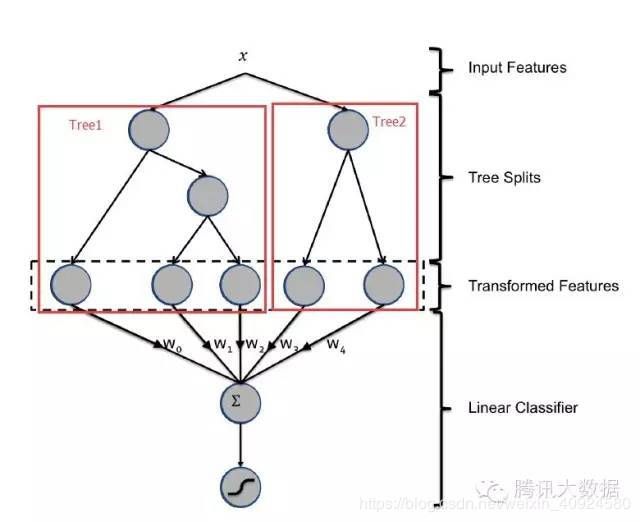
GBDT与LR的融合方式,Facebook的paper有个例子如下图2所示,图中Tree1、Tree2为通过GBDT模型学出来的两颗树,x为一条输入样本,遍历两棵树后,x样本分别落到两颗树的叶子节点上,每个叶子节点对应LR一维特征,那么通过遍历树,就得到了该样本对应的所有LR特征。由于树的每条路径,是通过最小化均方差等方法最终分割出来的有区分性路径,根据该路径得到的特征、特征组合都相对有区分性,效果理论上不会亚于人工经验的处理方式。
参考:http://www.cbdio.com/BigData/2015-08/27/content_3750170.htm
二、用户偏好模型构造帮助Trigger Selection
用户行为序列
![]()
• ⽤户偏好模型
预测⽤户下⼀个浏览或者购买的类⽬、性别预测、年龄预测等
• 问题抽象:基于时序⾏为的⼆分类模型
(1)统计量、变化类特征(⼈⼯组合)、序列类模型(部分⾃动组合)
(2)分析先⾏:⽐如对于⼀些商品trends变化和⽬标相关性进⾏分析
>⼈⼯组合特征:x1*x2,x1/x2…
>部分⾃动组合⽅式->GBDT/RF/FM/NN
(3)模型⽤法:做独⽴model;做进feature.
2模型构建
一、低维线性模型

二、非线性模型
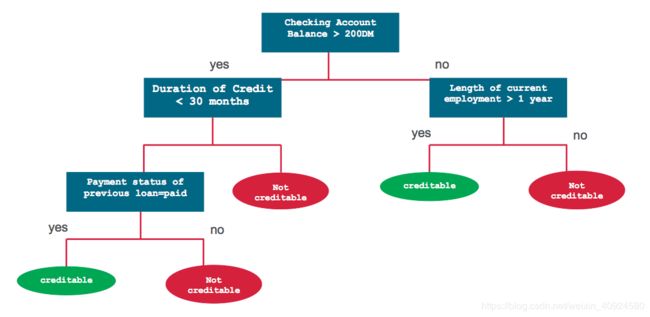
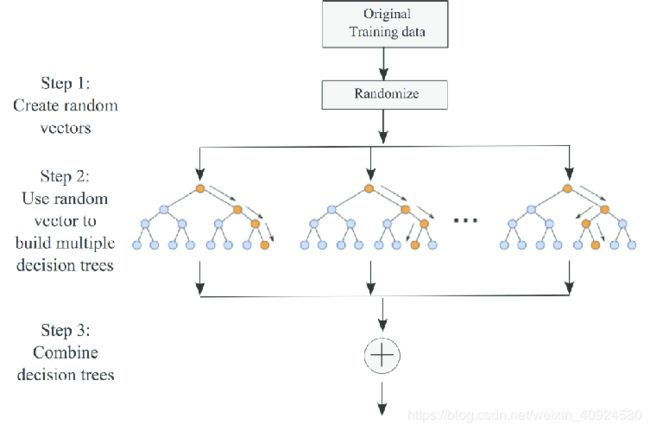
1—CART/RF
决策树
随机森林
2、非线性模型-----FM
• FM 受到前⾯所有的分解模型的启发
• 每个特征都表⽰成embedding vector,并且构造⼆阶关系
• FM 允许更多的特征⼯程,并且可以表⽰之前所有模型为特殊的FM

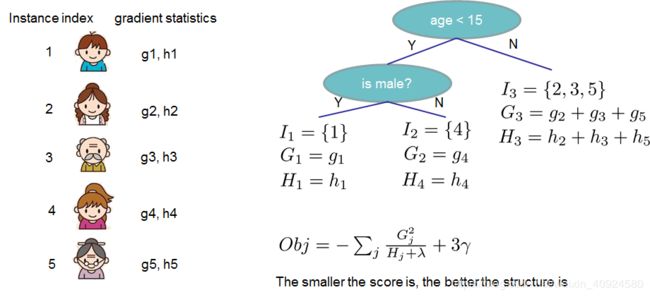
3、非线性模型----GBDT/DNN
GBDT
DNN

三、模型融合
http://quinonero.net/Publications/predicting-clicks-facebook.pdf

https://www.microsoft.com/en-us/research/wp-content/uploads/2017/04/main-1.pdf

四、互联网中的特征工程
特征分类

embedding特征:1相关性分数(类似cos距离),便于系统维护;2embedding直接输入,向量维度高扩展性好,但是重新训练模型后表达会发生变化。
特征组合
• Dense特征组合
A. 将⼀个特征与其本⾝或其他特征相乘(称为特征组合)(⼆阶或者⾼阶)
B. 两个特征相除。
C. 对连续特征进⾏分桶,以分为多个区间分箱
• ID特征之间的组合
D. 笛卡尔积:假如拥有⼀个特征A,A有两个可能值{A1,A2}。拥有⼀个特征B,存在{B1,B2}等可能
值。然后,A&B之间的交叉特征如下:{(A1,B1),(A1,B2),(A2,B1),(A2,B2)},⽐如经纬度,⼀个更好地诠释好的交叉特征的实例是类似于(经度,纬度)。⼀个相同的经度对应了地图上很多的地⽅,纬度也是⼀样。但是⼀旦你将经度和纬度组合到⼀起,它们就代表了地理上特定的⼀块区域,区域中每⼀部分是拥有着类似的特性。
头条特征工程:
**第⼀类是相关性特征,就是评估内容的属性和与⽤用户
是否匹配。**显性的匹配包括关键词匹配、分类匹配、
来源匹配、主题匹配等。像FM模型中也有⼀一些隐性匹
配,从⽤用户向量量与内容向量量的距离可以得出。
第⼆类是环境特征,包括地理理位置、时间。这些既是
bias特征,也能以此构建一些匹配特征。
**第三类是热度特征。**包括全局热度、分类热度,主题
热度,以及关键词热度等。内容热度信息在⼤大的推荐
系统特别在⽤用户冷启动的时候⾮非常有效。
**第四类是协同特征,它可以在部分程度上帮助解决所
谓算法越推越窄的问题。**协同特征并非考虑⽤用户已有
历史。而是通过用户行为分析不同用户间相似性,比如点击相似、兴趣分类相似、主题相似、兴趣词相似,甚⾄至向量量相似,从而扩展模型的探索能⼒力力。
特征选择
为什什么要做特征选择:
- 特征与⽬目标的相关性
- 训练和预测同分布问题
特征选择⽅方法分为3种:
- Filter:过滤法,评估单个特征和结果值之间的相关程度。按照发散性或者相关性对各个特征进⾏行行评分,设定阈值或者待选择阈值的个数,选择特征。sklearn中SelectKBest包可以根据特征的百分比进行操作
- Wrapper:包装法,根据⽬目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。典型的算法为“递归特征删除算法”,比如使用LR全特征跑一个模型,根据线性模型的系数删除掉5-10%弱特征,观察auc的变化;逐步进行直至auc出现大的下滑为止。from sklearn.feature_selection import RFE
- Embedded:嵌入法,先使用某些机器器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter⽅方法,但是是通过训练来确定特征的优劣。L1正则化

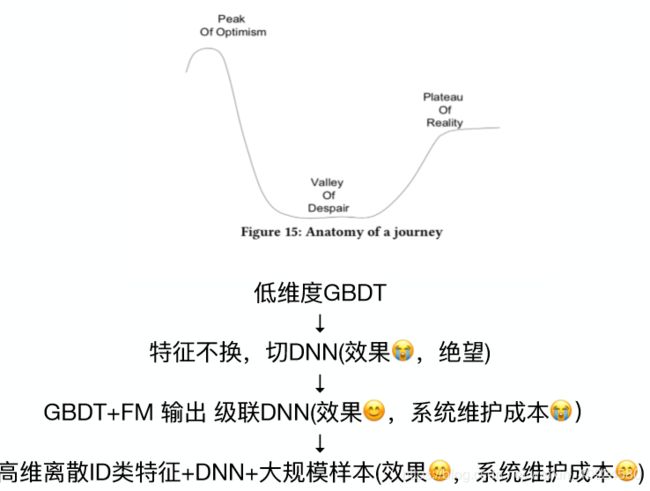
Airbnb模型演变
3、Wide&Deep Learning实战
参考:https://blog.csdn.net/yujianmin1990/article/details/78989099
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中。模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
结合我们的产品应用场景同 Google Play 的推荐场景存在较多的类似之处,在经过调研和评估后,我们也将 wide and deep 模型应用到产品的推荐排序模型,并搭建了一套线下训练和线上预估的系统。鉴于网上对 wide and deep 模型的相关描述和讲解并不是特别多,我们将这段时间对 TensorFlow1.1 中该模型的调研和相关应用经验分享出来,希望对相关使用人士带来帮助。
wide and deep 模型的框架在原论文的图中进行了很好的概述。wide 端对应的是线性模型,输入特征可以是连续特征,也可以是稀疏的离散特征,离散特征之间进行交叉后可以构成更高维的离散特征。线性模型训练中通过 L1 正则化,能够很快收敛到有效的特征组合中。deep 端对应的是 DNN 模型,每个特征对应一个低维的实数向量,我们称之为特征的 embedding。DNN 模型通过反向传播调整隐藏层的权重,并且更新特征的 embedding。wide and deep 整个模型的输出是线性模型输出与 DNN 模型输出的叠加。
如原论文中提到的,模型训练采用的是联合训练(joint training),模型的训练误差会同时反馈到线性模型和 DNN 模型中进行参数更新。相比于 ensemble learning 中单个模型进行独立训练,模型的融合仅在最终做预测阶段进行,joint training 中模型的融合是在训练阶段进行的,单个模型的权重更新会受到 wide 端和 deep 端对模型训练误差的共同影响。因此在模型的特征设计阶段,wide 端模型和 deep 端模型只需要分别专注于擅长的方面,wide 端模型通过离散特征的交叉组合进行 memorization,deep 端模型通过特征的 embedding 进行 generalization,这样单个模型的大小和复杂度也能得到控制,而整体模型的性能仍能得到提高。

from __future__ import absolute_import
from __future__ import division #导入精确除法,导入后若要执行阶段除法,需要使用"//"
from __future__ import print_function
import argparse #Argparse的作用就是为py文件封装好可以选择的参数,使他们更加灵活,丰富
import sys
import tempfile
from six.moves import urllib
import pandas as pa
import tensorflow as tf
COLUMNS = ["age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country",
"income_bracket"]
LABEL_COLUMN = "label"
CATEGORICAL_COLUMNS = ["workclass", "education", "marital_status", "occupation",
"relationship", "race", "gender", "native_country"] #类别型特征
CONTINUOUS_COLUMNS = ["age", "education_num", "capital_gain", "capital_loss",
"hours_per_week"] #连续型特征
def maybe_download(train_data,test_data):
""" maybe downs training data and returns train and test file names."""
if train_data:
train_file_name = train_data
else:
train_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.data", train_file.name)# pylint: disable=line-too-long
train_file_name = train_file.name
train_file.close()
print("Training data is downloaded to %s" % train_file_name)
if test_data:
test_file_name = test_data
else:
test_file = tempfile.NamedTemporaryFile(delete=False)
urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.test", test_file.name) # pylint: disable=line-too-long
test_file_name = test_file.name
test_file.close()
print("Test data is downloaded to %s" % test_file_name)
def build_estimator(model_dir,model_type):
""" Build an estimator"""
#sparse base columns
#tf.contrib.layers.sparse_column_with_XXX 构建低维离散特征
gender = tf.contrib.layers.sparse_columns_with_keys(column_name="gender",keys=["female", "male"])
education = tf.contib.layers.sparse_columns_with_hash_bucket("education",hash_bucket_size = 1000)
relationship = tf.contib.layers.sparse_columns_with_hash_bucket("relationship",hash_bucket_size = 100)
workclass = tf.cntrib.layers.sparse_columns_with_hash_bucket("workclass",hash_bucket_size = 100)
occupation = tf.comtrib.layers.sparse_columns_with_hash_bucket("occupation",hash_bucket_size = 1000)
native_country = tf.comtrib.layers.sparse_columns_with_hash_bucket("native_country",hash_bucket_size = 1000)
"""Continuous base columns"""
#tf.contrib.layers.real_valued_column 构建连续型实数特征
age = tf.contrib.layers.real_valued_column("age")
education_num = tf.contrib.layers.real_valued_column("education_num")
capital_gain = tf.contrib.layers.real_valued_column("capital_gain")
hours_pre_week = tf.contrib.layers.real_valued_column("hours_pre_week")
"""Transformations"""
#连续型特征通过 bucketization 生成离散特征
age_buckets = tf.contrib.layers.bucketized_columns(age,boundaries=[18,25,30,35,40,45,50,55,60,65])
#wide columns and deep columns
wide_columns = [gender,native_country,education,occupation,workclass,relationship,age_buckets,
tf.contrib.layers.crossed_column([education,occupation],hash_bucket_size = int(1e4)),
tf.contrib.layers.crossed_column([age_bucket,education,occupation],hash_bucket_size = int(1e6)),
tf.contrib.layers.crossed_colunm([native_country,occupation],hash_bucket_size=int(1e4))]
deep_clumns = [
tf.contrib.layers.embedding_column(workclass,dimension=8),
tf.contrib.layers.embedding_column(education,dimension=8),
tf.contrib.layers.embedding_column(gender,dimension=8),
tf.contrib.layers.embedding_column(relationship,dimension=8),
tf.contrib.layers.embedding_column(native_country,dimension=8),
tf.contrib.layers.embedding_column(occupation,dimension=8),
age,
education_num,
capital_gain,
hours_pre_week,
]
if model_type == "wide":
m = tf.contrib.learn.LinearClassifier(model_dir=model_dir,feature_colunms=wide_columns)
elif model_type == "deep":
m = tf.contrib.learn.DNNClassifier(model_dir=model_dir,feature_colunms=deep_clumns,hidden_units=[100,50]) #DNN 模型的隐藏层单元数目
else:
m = tf.contrib.laern.DNNLinearCombinedClassifier(model_dir=model_dir,linear_feature_columns=wide_columns,
dnn_feature_colunms=deep_clumns,
dnn_hidden_units=[100,50])
return m
def input_fn(df):
"""Input builder function,这个函数的主要作用就是把输入数据转换成张量,即向量型"""
#Creates a dictionary mapping from each continuous feature column name (k) to the values of that column stored in a constant Tensor.
continuous_cols = {k: tf.constant(df[k].values) for k in CONTINUOUS_COLUMNS}
#Creates a dictionary mapping from each categorical feature column name (k) to the values of that column stored in a tf.SparseTensor.
categorical_cols= {k:tf.SparseTensor(
indices=[[i,0] for i in range(df[k].size)])}
#Merges the two dictionaries into one
feature_cols = dict(continuous_cols)
feature_cols.update(feature_cols)
# Converts the label column into a constant Tensor.
label = tf.contant(df[LABEL_COLUMN].values)
# Returns the feature columns and the label.
return feature_cols,label
def train_and_eval(model_dir,model_type,train_step,train_data,test_data):
"""Train and evaluate the model"""
train_file_name,test_file_name = maybe_download(train_data,test_data)
df_train = pd.read_csv(tf.gfile.Open(train_file_name),
names=COLUMNS,
skipinitialspace=True,
engine = "python") #skipinitialspace=True忽略分隔符后的空白
df_test = pd.read_csv(tf.gfile.Open(test_file_name),
names = COLUMNS,
skipinitialspace=True,
skiprows = 1,
engine = "python") #skiprows表示需要忽略的行数
#remove NaN elements
df_train = df_train.dropna(how='any',axis=0)#使用参数axis = 0删除行,参数axis = 1删除列,这样删除一个变量(一个特征)
df_test = df_test.dropna(how='any',axis=0)
#将标签根据50K转为1,0
df_train[LABEL_COLUMN] = (
df_train["income_bracket"].apply(lambda x: ">50K" in x)).astype(int)
df_test[LABEL_COLUMN] = (
df_test["income_bracket"].apply(lambda x: ">50K" in x)).astype(int)
#判断输出的目录是否存在,不存在则创建临时的
model_dir = tempfile.mkdtemp() if not model_dir else model_dir
print("model directory = %s" % model_dir)
m = build_estimator(model_dir,model_type)
#进行训练
m.fit(input_fn=lambda:input_fn(df_train),steps=train_steps)
#使用test数据进行评估
results = m.evaluate(input_fn=lambda:input_fn(df_test),steps=1)
for key in sorted(results):
print("%s: %s" % (key, results[key]))
print("Train WDL End")
FLAGS = None
def main(_):
print(FLAGS)
train_and_eval(FLAGS.model_dir, FLAGS.model_type, FLAGS.train_steps,
FLAGS.train_data, FLAGS.test_data)
if __name__ == "__main__":
#使用argparse的第一步是创建ArgumentParser对象,ArgumentParser对象保存了所有必要的信息,
#用以将命令行参数解析为相应的python数据类型
parser = argparse.ArgumentParser()
parser.register("type", "bool", lambda v: v.lower() == "true")
#调用add_argument()向ArgumentParser对象添加命令行参数信息,这些信息告诉ArgumentParser
#对象如何处理命令行参数。可以通过调用parse_agrs()来使用这些命令行参数
parser.add_argument(
"--model_dir",
type=str,
default="./wdl_data/model_save",
help="Base directory for output models."
)
parser.add_argument(
"--model_type",
type=str,
default="wide_n_deep",
help="Valid model types: {'wide', 'deep', 'wide_n_deep'}."
)
parser.add_argument(
"--train_steps",
type=int,
default=2000,
help="Number of training steps."
)
parser.add_argument(
"--train_data",
type=str,
default="./wdl_data/adult.data",
help="Path to the training data."
)
parser.add_argument(
"--test_data",
type=str,
default="./wdl_data/adult.test",
help="Path to the test data."
)
#有时间一个脚本只需要解析所有命令行参数中的一小部分,剩下的命令行参数
#给两一个脚本或者程序。在这种情况下,parse_known_args()就很有用。它很
#像parse_args(),但是它在接受到多余的命令行参数时不报错
FLAGS, unparsed = parser.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) #执行main函数