朴素贝叶斯——Naive Bayes原理
Naive Bayes
简介
朴素贝叶斯分类是一种十分简单的分类算法。
- 思路
对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,将该待分类项归于概率最大的类别。
- 步骤
- 设 x = { a 1 , a 2 , . . . , a n } x=\{a_1, a_2, ..., a_n\} x={a1,a2,...,an}为一个待分类项, a i a_i ai为x的特征属性。
- 类别集合 C = { y 1 , y 2 , . . . , y n } C=\{y_1, y_2, ..., y_n\} C={y1,y2,...,yn}。
- 计算 P ( y 1 ∣ x ) , P ( y 2 ∣ x ) , . . . , P ( y n ∣ x ) P(y_1|x), P(y_2|x), ..., P(y_n|x) P(y1∣x),P(y2∣x),...,P(yn∣x)。
- 如果 P ( y k ∣ x ) = m a x { P ( y 1 ∣ x ) , P ( y 2 ∣ x ) , . . . , P ( y n , x ) } P(y_k|x)=max\{P(y_1|x), P(y_2|x), ..., P(y_n, x)\} P(yk∣x)=max{P(y1∣x),P(y2∣x),...,P(yn,x)},则 x ∈ y k x\in y_k x∈yk。
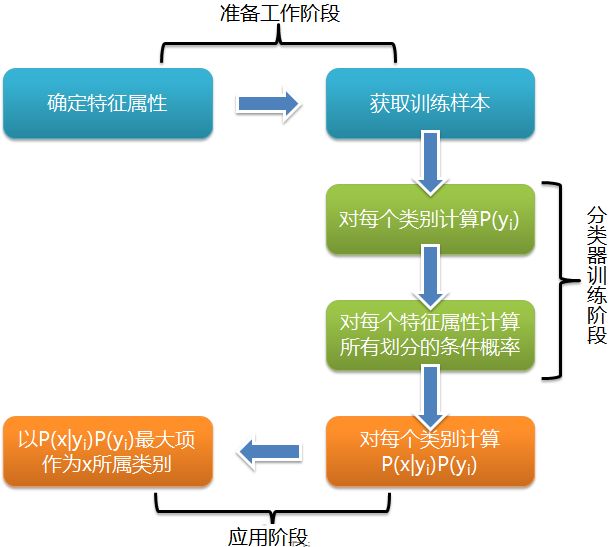
基本原理
- 条件概率
条件概率指事件A在事件B已经发生的条件下发生的概率,直接上公式:
P ( A ∣ B ) = P ( A B ) P ( B ) P(A|B)=\frac{P(AB)}{P(B)} P(A∣B)=P(B)P(AB)
- 贝叶斯定理
贝叶斯定理用于计算后验概率。
先验概率(prior probability):指根据以往经验和分析。在实验或采样前就可以得到的概率。
后验概率(posterior probability):指某件事已经发生,想要计算这件事发生的原因是由某个因素引起的概率。
计算公式:
P ( B ∣ A ) = P ( A ∣ B ) P ( B ) P ( A ) P(B|A)=\frac{P(A|B)P(B)}{P(A)} P(B∣A)=P(A)P(A∣B)P(B)
- 步骤详解
在上述给出的步骤中,最关键的是第三步中的计算,即 P ( y k ∣ x ) P(y_k|x) P(yk∣x)的计算。
首先我们需要统计在不同类别下各个属性的条件概率,即
P ( a 1 ∣ y 1 ) , . . . , P ( a m ∣ y 1 ) , . . . , P ( a m ∣ y n ) P(a_1|y_1), ..., P(a_m|y_1), ..., P(a_m|y_n) P(a1∣y1),...,P(am∣y1),...,P(am∣yn)
由贝叶斯公式我们将待求转换为:
P ( y k ∣ x ) = P ( x ∣ y k ) P ( y k ) P ( x ) = ∣ D y k , x ∣ ∣ D ∣ P(y_k|x)=\frac{P(x|y_k)P(y_k)}{P(x)}=\frac{|D_{y_k,x}|}{|D|} P(yk∣x)=P(x)P(x∣yk)P(yk)=∣D∣∣Dyk,x∣
由全概率公式得 P ( x ) P(x) P(x)对于所有的划分都为常数,所以要使 P ( y k ∣ x ) P(y_k|x) P(yk∣x)最大,只需使 P ( x ∣ y k ) P ( y k ) P(x|y_k)P(y_k) P(x∣yk)P(yk)最大。同时朴素贝叶斯假设各个属性相互独立,当然这里为了方便计算而牺牲了部分准确率。由此假设,有
P ( x ∣ y i ) P ( y i ) = P ( a 1 ∣ y i ) . . . P ( a m ∣ y i ) P ( y i ) = P ( y i ) ∏ j = 0 m P ( a j ∣ y i ) P(x|y_i)P(y_i)=P(a_1|y_i)...P(a_m|y_i)P(y_i)=P(y_i)\prod_{j=0}^mP(a_j|y_i) P(x∣yi)P(yi)=P(a1∣yi)...P(am∣yi)P(yi)=P(yi)j=0∏mP(aj∣yi)
所以 h ( x ) = a r g m a x y i ∈ y P ( y i ) ∏ j = 0 m P ( a j ∣ y i ) h(x)=argmax_{y_i \in y}P(y_i)\prod_{j=0}^mP(a_j|y_i) h(x)=argmaxyi∈yP(yi)∏j=0mP(aj∣yi)。
- 拉普拉斯修正
当训练样本较少或不充分时,可能出现概率估值为零的情况,引入拉普拉斯修正:
P ( y k ) = ∣ D c ∣ + 1 ∣ D ∣ + N P(y_k)=\frac{|D_c|+1}{|D|+N} P(yk)=∣D∣+N∣Dc∣+1
P ( x i ∣ y k ) = ∣ D c , x i ∣ + 1 ∣ D ∣ + N i P(x_i|y_k)=\frac{|D_{c, x_i}|+1}{|D|+N_i} P(xi∣yk)=∣D∣+Ni∣Dc,xi∣+1
同时,对于引入的修正,随着概率的增大可以忽略不计,从而使估值更接近实际概率值。
reference:
朴素贝叶斯分类(Nave Bayes)