kaggle入门之Titanic实战(二)
这是继《kaggle入门之Titanic实战(一)》的更新,主要加入了两点更新。
一、其中对baseline中没有分析利用的一些特征进行了处理,比如对Name进行了隐藏特征提取,并对其他特征进行了较为详细的分析;
二、加入了简单的模型融合。
以下是正文:
1、对数据的缺失值和离群点进行处理。其中Cabin缺失值用众数进行填充;做Fare的散点图可以看出,取值基本分布在[0, 300]之间,对Fare取值大于300的离群点进行处理,限制为300;通过观察Name可以发现,在绝大多数姓名的中间部分含有Mr、Miss、Mrs等可以对身份进行判断的隐藏特征,对Name进行处理,将这些特征提取出来,并分析和Survived之间是否存在关系;观察Ticket可以发现有的是以字母开头有的是以数字开头,猜测是否以字母开头有可能对Survived有影响;Cabin处理与baseline一样,暂时没想到更好的处理办法;最后对Parch和SibSp进行离群点处理,思路和对Fare的想法一样。
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data_train = pd.read_csv('train.csv')
data_name = data_train['Name'].copy()
data_fare = data_train['Fare'].copy()
data_cabin = data_train['Cabin'].copy()
data_ticket = data_train['Ticket'].copy()
data_age = data_train['Age'].copy()
data_survived = data_train['Survived'].copy()
data_SibSp = data_train['SibSp'].copy()
data_Parch = data_train['Parch'].copy()
data_pclass = data_train['Pclass'].copy()
data_embarked = data_train['Embarked'].copy()
data_sex = data_train['Sex'].copy()
# 对Embarked进行缺失值处理
data_embarked[data_embarked.isnull()] = 'S'
# 首先对Fare的离群点进行处理
print(data_fare.max(), data_fare.min())
data_fare[data_fare > 300] = 300
# 接下来对姓名进行处理,仅保留'Mr'、'Mrs'、'Miss'、'Master'等可以用来表示身份的部分
# 没有的用'Unknown'来表示
for i in range(0, 891):
if 'Mr' in data_name[i] and 'Mrs' not in data_name[i]:
data_name[i] = 'Mr'
elif 'Mrs' in data_name[i]:
data_name[i] = 'Mrs'
elif 'Miss' in data_name[i]:
data_name[i] = 'Miss'
elif 'Master' in data_name[i]:
data_name[i] = 'Master'
else:
data_name[i] = 'Unknown'
number_set = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
# 对ticket进行处理,如果data_ticket[i][0]为字母则记为STR
# 否则记为'NUM',意思是第一个字符为数字,注意ticket的数据类型全部为Str
for i in range(0, 891):
if data_ticket[i][0] in number_set:
data_ticket[i] = 'NUM'
else:
data_ticket[i] = 'STR'
# 对Cabin进行处理
index = data_cabin.isnull()
for i in range(0, 891):
if index[i] == True:
data_cabin[i] = 'Unknown'
else:
data_cabin[i] = 'Known'
#对Parch和SibSp进行处理:
data_Parch[data_Parch > 2] = 2
data_SibSp[data_SibSp > 3] = 3
# 对处理后的数据进行重构
df = DataFrame({'Survived': data_survived, 'Name': data_name, 'Cabin': data_cabin,
'Age': data_age, 'Fare': data_fare, 'Ticket': data_ticket,
'SibSp': data_SibSp, 'Parch': data_Parch, 'Pclass': data_pclass,
'Embarked': data_embarked, 'Sex': data_sex})
# 分析Name和Survived之间的关系
df1 = df[['Name', 'Survived']]
Name_1 = df1.Name[df1.Survived == 1].value_counts()
Name_0 = df1.Name[df1.Survived == 0].value_counts()
df1 = DataFrame({'Survived': Name_1, 'Nosurvived': Name_0})
df1.plot(kind='bar', stacked='all')
plt.xlabel('Name')
plt.title('Name and Survived condition')
#print(df.Age[df.Name == 'Master']) # 可以看出Name类型为Master时年龄明显偏小
# 分析不同姓名特征人群的年龄分布
fig1 = plt.figure()
df.Age[df.Name == 'Mr'].plot(kind='kde')
df.Age[df.Name == 'Mrs'].plot(kind='kde')
df.Age[df.Name == 'Miss'].plot(kind='kde')
df.Age[df.Name == 'Master'].plot(kind='kde')
df.Age[df.Name == 'Unknown'].plot(kind='kde')
plt.xlabel('Name')
plt.ylabel('probability density')
plt.legend(('Name=Mr', 'Name=Mrs', 'Name=Miss', 'Name=Master', 'Name=Unknown'), loc='best')
# 由此可以看出姓名和年龄还是存在一定关系的,这一点可以用来对缺失的年龄进行预测
# 分析Cabin与年龄之间的关系
fig2 = plt.figure()
df5 = df[['Cabin', 'Age']]
Known_Age = df5.Age[df5.Cabin == 'Known'].plot(kind='kde')
Unknown_Age = df5.Age[df5.Cabin == 'Unknown'].plot(kind='kde')
plt.xlabel('Age')
plt.ylabel('probability density')
plt.legend(['Cabin=Known', 'Cabin=Unknown'])
plt.title('Age and Cabin')
#分析Cabin与存活之间的关系
df2 = df[['Survived', 'Cabin']]
Cabin_1 = df2.Cabin[df2.Survived == 1].value_counts()
Cabin_0 = df2.Cabin[df2.Survived == 0].value_counts()
df2 = DataFrame({'Survived': Cabin_1, 'Nosurvived': Cabin_0})
df2.plot(kind='bar', stacked='all')
plt.xlabel('Cabin')
plt.ylabel('Survived')
plt.title('Cabin and Survived')
#分析Ticket与存活之间的关系
df3 = df[['Survived', 'Ticket']]
Ticket_1 = df3.Ticket[df3.Survived == 1].value_counts()
Ticket_0 = df3.Ticket[df3.Survived == 0].value_counts()
df3 = DataFrame({'Survived': Ticket_1, 'Nosurvived': Ticket_0})
df3.plot(kind='bar', stacked='all')
plt.xlabel('Ticket Type')
plt.title('Ticket Type and Survived Condition')
# 说明Ticket类型与是否存活基本没有关系
# 分析表亲个数与年龄质检的关系
df4 = df[['Age', 'SibSp']]
fig3 = plt.figure()
df4.Age[df4.SibSp == 0].plot(kind='kde')
df4.Age[df4.SibSp == 1].plot(kind='kde')
df4.Age[df4.SibSp == 2].plot(kind='kde')
df4.Age[df4.SibSp == 3].plot(kind='kde')
plt.xlabel('SibSp')
plt.ylabel('Age')
plt.legend(['SibSp=0', 'SibSp=1', 'SibSp=2', 'SibSp=3'])
plt.title('SibSp and Age')
# 分析父母/子女个数与年龄之间的关系
df4 = df[['Age', 'Parch']]
fig4 = plt.figure()
df4.Age[df4.Parch == 0].plot(kind='kde')
df4.Age[df4.Parch == 1].plot(kind='kde')
df4.Age[df4.Parch == 2].plot(kind='kde')
plt.xlabel('Parch')
plt.ylabel('Age')
plt.legend(['Parch=0', 'Parch=1', 'Parch=2'])
plt.title('Parch and Age')
plt.show()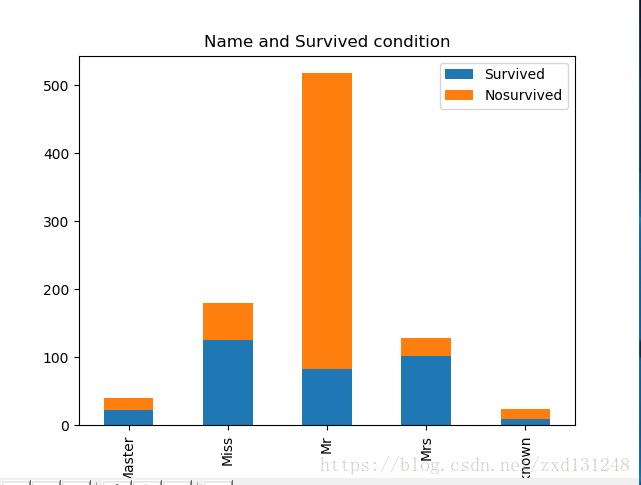
可以看出Name的隐藏特征与Survived果然存在较大关系,但是与Sex存在很大关系,但先不作处理,后续改进再处理;
观察Name与年龄之间的关系,可以看出不同身份的人年龄的最高点有很大差别;
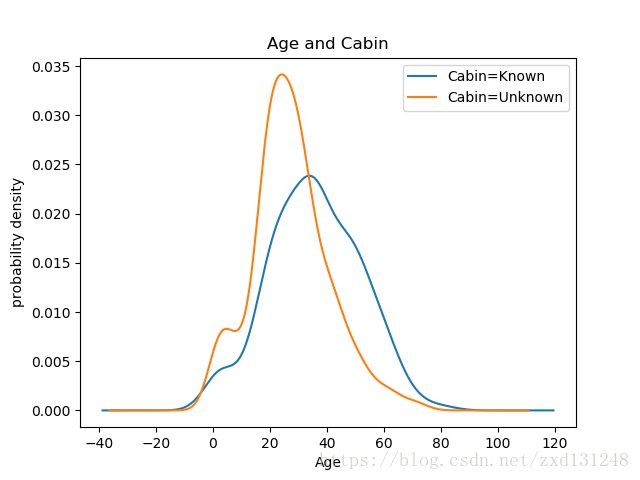
观察Cabin与年龄之间的关系;

观察Cabin与Survived之间的关系,可以看出Cabin与Known是活下来的概率更大;
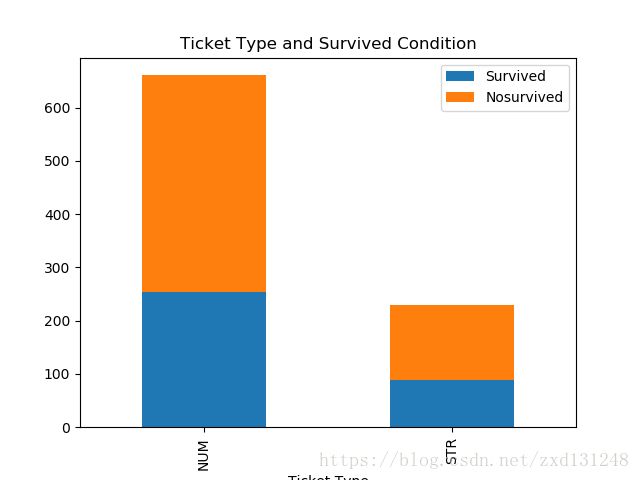
观察Ticket与存活之间的关系,然而并没有明显差别,说明猜测猜的不太对,后续再改进吧;
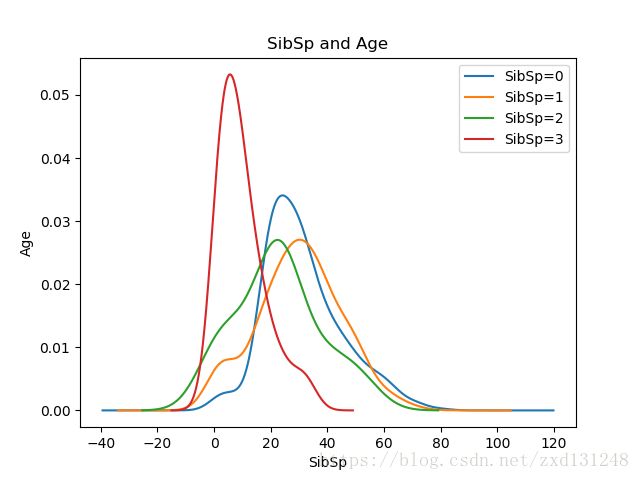
观察SibSp与存活之间的关系,发现取值为3时明显年龄偏小,估计是取值为3的都是小孩子;
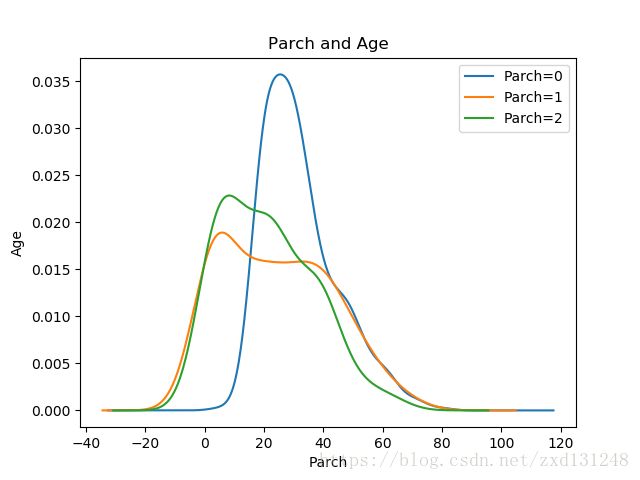
观察Parch与年龄之间的关系,可以看出取值为1和2的与取值为0的年龄分布明显不一样,可能是因为二三十岁正是独自浪迹天涯的时候,比如Jack..对吧。
2、之前数据分析的时候之所以费那么大劲分析各个特征和年龄之间的关系,现在终于要派上用场了,思路跟baseline一样,都是用随机森林进行拟合,巴特挑出来的特征都是跟年龄关系较大的,而不是像baseline一样那么粗暴。
# 根据分析得到的结果,可以看出Name、SibSp、Parch、Cabin、Pclass有较为明显的关系
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
import sklearn.preprocessing as prep
def deal_age(df):
dummies_name = pd.get_dummies(df['Name'], prefix='Name')
dummies_cabin = pd.get_dummies(df['Cabin'], prefix='Cabin')
data_set1 = df[['Age', 'Pclass', 'Parch', 'SibSp']]
data_set2 = pd.concat([data_set1, dummies_name, dummies_cabin], axis=1)
known_age = data_set2[data_set2.Age.notnull()].as_matrix()
unknown_age = data_set2[data_set2.Age.isnull()].as_matrix()
features = known_age[:, 1:]
values = known_age[:, 1]
RandomForest = RandomForestRegressor(random_state=0, n_jobs=-1, n_estimators=2000)
RandomForest.fit(features, values)
predict_ages = RandomForest.predict(unknown_age[:, 1:])
df.loc[(df.Age.isnull()), 'Age'] = predict_ages
data_age = df['Age']
return df, RandomForest, data_age
df, RandomForest, data_age = deal_age(df)3、之后就是利用不同的模型进行训练和预测了,但是不同类型的模型对特征值的种类有不同的要求。我共使用了4种不同类型模型,分别是:
(1)、RandomForest:随机森林,接受二值和标量类型;
(2)、LogisticRegression:逻辑回归分类器,接受二值和标量类型;
(3)、AdaboostClassifier:自适应提升树分类器,接受二值类型;
(4)、GradiantBoostingClassifier:梯度提升树分类器,接受标量类型;
先定义一些通用函数,用来对特征类型进行转换:
def class_2_scalar(data_temp):
temp = pd.factorize(data_temp)[0]
result = Series(temp, index=np.arange(0, len(temp)))
return result
def scalar_2_class(data_temp, num):
temp1 = Series(pd.factorize(pd.qcut(data_temp, num))[0])
return temp1
def scale_operation(data_temp):
temp2 = prep.scale(data_temp)
return temp2
def get_dummy(data_temp, feature_name):
dummies_temp = pd.get_dummies(data_temp[feature_name], prefix=feature_name)
result = pd.concat([data_temp, dummies_temp], axis=1)
result.drop([feature_name], inplace=True, axis=1)
return result具体来说,标量型转换为二值型需要先进行分箱操作并转换为标称型然后计算相应的哑矩阵,而标称类型转化为标量类型的方法是先factorize取特征,然后再进行scale。
由于不同的模型要求不同的特征类型,将针对不同模型的特征处理与模型训练封装在各自的函数里,这样可以互不影响。然后通过调用函数来分别进行数据处理和模型训练。
data_set = get_dummy(df, 'Name')
data_set = get_dummy(data_set, 'Cabin')
data_set = get_dummy(data_set, 'Ticket')
data_set = get_dummy(data_set, 'Sex')
data_set = get_dummy(data_set, 'Embarked')
data_set = get_dummy(data_set, 'Pclass')
print(data_set.info())
# 采用函数调用的形式训练模型
def Random_Forest_classify(data_set):
data_set = data_set.as_matrix()
train_features = data_set[:, 1:]
train_values = data_set[:, 0].astype(int)
RF_classifier = RandomForestClassifier(oob_score=True, n_estimators=10000, n_jobs=-1)
RF_classifier.fit(train_features, train_values)
return RF_classifier, train_features, train_values
def LR_classify(train_features, train_values):
LR_classifier = LogisticRegression(random_state=0, C=1.0, penalty='l1', tol=1e-6)
LR_classifier.fit(train_features, train_values)
return LR_classifier
def Ada_classify(data_set, data_age, data_fare):
Adaboost_classifier = AdaBoostClassifier(n_estimators=200,
learning_rate=0.01, random_state=0)
data_age = scale_operation(scalar_2_class(data_age, 2))
data_fare = scale_operation(scalar_2_class(data_fare, 2))
data_set.drop(['Age', 'Fare'], inplace=True, axis=1)
data_set['Age'] = data_age
data_set['Fare'] = data_fare
data_set = data_set.as_matrix()
train_features_bin = data_set[:, 1:]
train_values_bin = data_set[:, 0]
Adaboost_classifier.fit(train_features_bin, train_values_bin)
return Adaboost_classifier, train_values_bin, train_features_bin
def GBDT_classify(data_name, data_cabin, data_ticket, data_sex,
data_embarked, data_pclass, data_sibsp, data_parch, data_age,
data_fare, data_survived):
GBDT_classifier = GradientBoostingClassifier(learning_rate=0.01, n_estimators=200,
max_depth=3)
data_name = scale_operation(class_2_scalar(data_name))
data_cabin = scale_operation(class_2_scalar(data_cabin))
data_ticket = scale_operation(class_2_scalar(data_ticket))
data_sex = scale_operation(class_2_scalar(data_sex))
data_embarked = scale_operation(class_2_scalar(data_embarked))
data_pclass = scale_operation(class_2_scalar(data_pclass))
data_sibsp = scale_operation(data_sibsp)
data_parch = scale_operation(data_parch)
data_age = scale_operation(data_age)
data_fare = scale_operation(data_fare)
data_set = DataFrame({'Survived': data_survived, 'Name': data_name,
'Cabin': data_cabin, 'Age': data_age, 'Fare': data_fare,
'Ticket': data_ticket, 'SibSp': data_sibsp,
'Parch': data_parch, 'Pclass': data_pclass,
'Embarked': data_embarked, 'Sex': data_sex})
data_set = data_set.as_matrix()
train_features_scalar = data_set[:, 1:]
train_values_scalar = data_set[:, 0]
GBDT_classifier.fit(train_features_scalar, train_values_scalar)
return GBDT_classifier
RF_classifier, train_features, train_values = Random_Forest_classify(data_set)
LR_classifier = LR_classify(train_features, train_values)
Ada_classifier, train_features_bin, train_values_bin = \
Ada_classify(data_set, data_age, data_fare)
GBDT_classifier = GBDT_classify(data_name, data_cabin, data_ticket, data_sex,
data_embarked, data_pclass, data_SibSp,
data_Parch, data_age, data_fare, data_survived)模型训练好之后,就是对测试数据进行类似的数据处理,过程和对训练数据的处理基本一样,没什么好说的。
# 对测试数据进行处理并利用训练好的模型进行预测
test_data = pd.read_csv('test.csv')
test_name = test_data['Name'].copy()
test_fare = test_data['Fare'].copy()
test_cabin = test_data['Cabin'].copy()
test_ticket = test_data['Ticket'].copy()
test_age = test_data['Age'].copy()
test_SibSp = test_data['SibSp'].copy()
test_Parch = test_data['Parch'].copy()
test_pclass = test_data['Pclass'].copy()
test_embarked = test_data['Embarked'].copy()
test_sex = test_data['Sex'].copy()
print(test_data.info())
# 首先对Name进行处理
for i in range(0, 418):
if 'Mr' in test_name[i] and 'Mrs' not in test_name[i]:
test_name[i] = 'Mr'
elif 'Mrs' in test_name[i]:
test_name[i] = 'Mrs'
elif 'Miss' in test_name[i]:
test_name[i] = 'Miss'
elif 'Master' in test_name[i]:
test_name[i] = 'Master'
else:
test_name[i] = 'Unknown'
# 对Ticket进行处理
for i in range(0, 418):
if test_ticket[i][0] in number_set:
test_ticket[i] = 'NUM'
else:
test_ticket[i] = 'STR'
# 对Cabin进行处理
index = test_cabin.isnull()
for i in range(0, 418):
if index[i] == True:
test_cabin[i] = 'Unknown'
else:
test_cabin[i] = 'Known'
# 对Parch和SibSp进行处理:
test_Parch[data_Parch > 2] = 2
test_SibSp[data_SibSp > 3] = 3
# 对Fare的缺失值用均值进行填补并对离群点处理
test_fare[test_fare.isnull()] = test_fare.mean()
data_fare[data_fare > 300] = 300
df_test = DataFrame({'Name': test_name, 'Cabin': test_cabin, 'Age': test_age,
'Fare': test_fare, 'Ticket': test_ticket, 'SibSp': test_SibSp,
'Parch': test_Parch, 'Pclass': test_pclass, 'Embarked': test_embarked,
'Sex': test_sex})
def deal_test_age(df_test, Random_Forest):
dummies_name = pd.get_dummies(df_test['Name'], prefix='Name')
dummies_cabin = pd.get_dummies(df_test['Cabin'], prefix='Cabin')
data_set1 = df_test[['Age', 'Pclass', 'Parch', 'SibSp']]
data_set2 = pd.concat([data_set1, dummies_name, dummies_cabin], axis=1)
unknown_age = data_set2[data_set2.Age.isnull()].as_matrix()
predict_ages = Random_Forest.predict(unknown_age[:, 1:])
df_test.loc[(df_test.Age.isnull()), 'Age'] = predict_ages
test_age = df_test['Age']
return df_test, test_age
df_test, test_age = deal_test_age(df_test, RandomForest)最后用调用函数的方式用训练好的模型对处理好的测试数据进行预测。
data_set = get_dummy(df_test, 'Name')
data_set = get_dummy(data_set, 'Cabin')
data_set = get_dummy(data_set, 'Ticket')
data_set = get_dummy(data_set, 'Sex')
data_set = get_dummy(data_set, 'Embarked')
data_set = get_dummy(data_set, 'Pclass')
print(data_set.columns)
# 利用训练好的模型进行预测
def Random_Forest_predict(data_set, RF_classifier):
data_set = data_set.as_matrix()
test_features = data_set[:, :]
result = RF_classifier.predict(test_features)
return result, test_features
def LR_predict(test_features, LR_classifier):
result = LR_classifier.predict(test_features)
return result
def Ada_predict(data_set, test_age, test_fare, Ada_classifier):
test_age = scale_operation(scalar_2_class(test_age, 2))
test_fare = scale_operation(scalar_2_class(test_fare, 2))
data_set.drop(['Age', 'Fare'], inplace=True, axis=1)
data_set['Age'] = test_age
data_set['Fare'] = test_fare
data_set = data_set.as_matrix()
test_features_bin = data_set
result = Ada_classifier.predict(test_features_bin)
return result
def GBDT_predict(test_name, test_cabin, test_ticket, test_sex,
test_embarked, test_pclass, test_sibsp, test_parch, test_age,
test_fare, GBDT_classifier):
test_name = scale_operation(class_2_scalar(test_name))
test_cabin = scale_operation(class_2_scalar(test_cabin))
test_ticket = scale_operation(class_2_scalar(test_ticket))
test_sex = scale_operation(class_2_scalar(test_sex))
test_embarked = scale_operation(class_2_scalar(test_embarked))
test_pclass = scale_operation(class_2_scalar(test_pclass))
test_sibsp = scale_operation(test_sibsp)
test_parch = scale_operation(test_parch)
test_age = scale_operation(test_age)
test_fare = scale_operation(test_fare)
data_set = DataFrame({'Name': test_name,'Cabin': test_cabin,'Age': test_age,
'Fare': test_fare,'Ticket': test_ticket,'SibSp': test_sibsp,
'Parch': test_parch, 'Pclass': test_pclass,
'Embarked': test_embarked, 'Sex': test_sex})
data_set = data_set.as_matrix()
test_features_scalar = data_set
result = GBDT_classifier.predict(test_features_scalar)
return result
result1, test_features = Random_Forest_predict(data_set, RF_classifier)
result2 = LR_predict(test_features, LR_classifier).astype(int)
result3 = Ada_predict(data_set, test_age, test_fare, Ada_classifier).astype(int)
result4 = GBDT_predict(test_name, test_cabin, test_ticket, test_sex,
test_embarked, test_pclass, test_SibSp, test_Parch, test_age,
test_fare, GBDT_classifier).astype(int)对返回的结果进行相加,采用投票的方式得到最后的结果。
predictions = Series(result1 + result2 + result3 + result4)
index1_pre = predictions.values > 2
index2_pre = predictions.values <= 2
predictions[index1_pre] = 1
predictions[index2_pre] = 0
result = DataFrame({'PassengerId': np.arange(892, 1310), 'Survived': predictions})
result.to_csv('result.csv', index=False)然后去kaggle官网提交结果,可以看到相对baseline准确率有较大提升:

10000多份结果里排在1648,Top20%吧,离前5%还差不少。。
这次的模型里,还有很多不足之处可以改进,目前我想到的主要有以下几点:
(1)、对一些特征的挖掘还不够细致,比方说有的资料上说Ticket的首字母是代表国家的,与存活率之间有一定关系,而我只是区分了是否以字母开头,而且是否以字母开头与是否存活之间关系并不明显;
(2)、没有构建交互特征,有时候并不能看出单个特征与label之间的关系,但是构建交互特征有可能发现一定的联系;
(3)、没有加入cross_validation,仅仅是自主设定了参数并进行了训练,而没有通过交叉验证的方式对模型参数进行调优;
(4)、没有加入超参数的选取,只是对各个模型的预测结果进行了简单相加,相当于认为各个模型的权重相等;
(5)、各个模型的训练都使用了全部的训练数据,这有可能会增加过拟合的风险,更好的处理办法是每个模型只使用一部分的训练数据,这样即便各个模型存在一定的过拟合,也只是对一部分数据过拟合。
暂时就想到这些,之后会继续进行改进。