Hadoop Streaming介绍与实战(附代码)
文章目录
- 一、介绍
- 1.1 streaming简介
- 1.2 streaming优点
- 1.3 streaming不足
- 二、执行原理
- 三、具体参数
- 四、实践
- 4.1 -file的应用
- 4.2 -cacheFile的应用
- 4.3 -cacheArchive的应用
- 4.4 compression(压缩)
- 4.5 全局排序(单个reduce)
- 4.6 全局排序(多个reduce)
- 4.7 共同好友
一、介绍
1.1 streaming简介
- Streaming框架允许任何程序语言实现的程序在Hadoop MapReduce中使用,方便已有程序向Hadoop平台移植。
- Streaming的原理是用Java实现一个包装用户程序的MapReduce程序,该程序负责调用MapReduce Java接口获取key/value对输入,创建一个新的进程启动包装的用户程序,将数据通过管道传递给包装的用户程序处理,然后调用MapReduce Java接口将用户程序的输出切分成key/value对输出。
1.2 streaming优点
- 开发效率高,便于移植
按照标准输入输出编程就可以满足Hadoop要求,单机程序稍改动便能在集群上运行,便于测试。
测试代码 : cat input | mapper | sort | reducer > output - 程序运行效率高
对于CPU密集的计算,有些语言如C/C++比用JAVA编写的程序效率更高。 - 便于平台进行资源控制
Streaming框架中通过limi等方式可以灵活地限制应用程序使用的内存等资源。
1.3 streaming不足
- Hadoop Streaming默认只能处理文本数据,无法直接对二进制数据进行处理,如果要对二进制数据处理,可以将二进制的key和value进行base64的编码转化成文本。
- 两次数据拷贝和解析(分割),带来一定开销。
二、执行原理



三、具体参数
| 参数 | 解释 |
|---|---|
| -input |
输入数据路径 |
| -output |
输出数据路径 |
| -mapper |
mapper可执行程序或Java类 |
| -reducer |
reducer可执行程序或Java类 |
| -file |
分发本地文件 |
| -cacheFile |
分发HDFS文件 |
| -cacheArchive |
Optional 分发HDFS压缩文件 |
| -numReduceTasks |
reduce任务个数 |
| -jobconf | -D NAME=VALUE Optional | 作业配置参数 |
| -combiner |
Combiner Java类 |
| -partitioner |
Partitioner Java类 |
各个参数的详细说明:
- -input :指定作业输入,path可以是文件或者目录,可以使用*通配符,-input选项可以使用多次指定多个文件或目录作为输入。
- -output :指定作业输出目录,path必须不存在,而且执行作业的用户必须有创建该目录的权限,-output只能使用一次。
- -mapper:指定mapper可执行程序或Java类,必须指定且唯一。
- -reducer:指定reducer可执行程序或Java类,可以省略(看需求)。
- -file:用于向计算节点分发本地文件。①map和reduce的执行文件 ②map和reduce要输入的 文件,如配置文件。
- -cacheFile:用于向计算机节点发HDFS文件(文件已经存在于HDFS上)
- -cacheArchive:用于向计算机节点发HDFS压缩文件(文件已经存在于HDFS上)
- -numReduceTasks:指定reducer的个数,如果设置-numReduceTasks 0或者-reducer NONE则没有reducer程序,mapper的输出直接作为整个作业的输出。
- -jobconf | -D NAME=VALUE:指定作业参数,NAME是参数名,VALUE是参数值,可以指定的参数参考hadoop-default.xml。注意:用-D作为参数时,必须在所有参数的最前面
下列是-jobconf | -D 一些用法(▲表示常用)
| 条件 | 作用 |
|---|---|
| ▲mapred.job.name | 作业名 |
| ▲mapred.job.priority | 作业优先级 |
| ▲mapred.job.map.capacity | 最多同时运行map任务数 |
| ▲mapred.job.reduce.capacity | 最多同时运行reduce任务数 |
| ▲mapred.map.tasks | map任务个数 |
| ▲mapred.reduce.tasks | reduce任务个数 |
| mapred.task.timeout | 任务没有响应(输入输出)的最大时间 |
| mapred.compress.map.output | map的输出是否压缩 |
| mapred.map.output.compression.codec | map的输出压缩方式 |
| mapred.compress.reduce.output | reduce的输出是否压缩 |
| mapred.output.compression.codec | reduce的输出压缩方式 |
四、实践
4.1 -file的应用
[root@master mr_file_broadcast]# cat map.py
import sys
def read_local_file_func(f):
word_set=set()
with open(f,'r') as word:
for line in word:
word_set.add(line.strip())
return word_set
def mapper_func(white_file):
word_set=read_local_file_func(white_file)
for line in sys.stdin:
ss=line.strip().split(' ')
for s in ss:
word=s.strip()
if word!=""and (word in word_set):
print "%s\t%s" % (s,1)
if __name__ == '__main__':
module=sys.modules[__name__]
func=getattr(module,sys.argv[1])
args=None
if len(sys.argv)>1:
args=sys.argv[2:]
func(*args)
[root@master mr_file_broadcast]# cat
import sys
def reducer_func():
current_word=None
count_pool=[]
sum=0
for line in sys.stdin:
word,value=line.strip().split()
if current_word==None:
current_word=word
if current_word!=word:
for count in count_pool:
sum+=count
print "%s\t%s" % (current_word,str(sum))
current_word=word
count_pool=[]
sum=0
count_pool.append(int(value))
for count in count_pool:
sum+=count
print "%s\t%s" % (current_word,str(sum))
if __name__ == '__main__':
module=sys.modules[__name__]
func=getattr(module,sys.argv[1])
args=None
if len(sys.argv)>1:
args=sys.argv[2:]
func(*args)
[badou@master mr_file_broadcast]$ cat white_list_file
our
of
into
[root@master mr_file_broadcast]# cat run.sh
HADOOP_CMD="/usr/local/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/123.txt"
OUTPUT_PATH="/output_white_list"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func white_list_file" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=3" \
-file ./map.py \
-file ./red.py \
-file ./white_list_file \
-file ./white_list_file \ 指定计算白名单内单词的wordcount
-jobconf “mapred.reduce.tasks=3” \ 设定reduce任务为3
4.2 -cacheFile的应用
[root@master mr_cachefile_broadcast]# cat run.sh
HADOOP_CMD="/usr/local/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/123.txt"
OUTPUT_PATH="/output_cachefile_demo"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func ABC" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=2" \
-jobconf "mapred.job.name=cachefile_demo" \
-cacheFile "hdfs://master:9000/white_list_file#ABC" \
-file ./map.py \
-file ./red.py \
# cacheFile "$HDFS_PATH#FileName" \
▲ -cacheFile “hdfs://master:9000/white_list_file#ABC” \ 分发cacheFile文件
注:
- cacheFile中F为大写;
- ABC为文件别名,前面带#;
- 跑任务之前要把white_list_file、123.txt 上传到HDFS上
4.3 -cacheArchive的应用
[root@master mr_cachearchive_broadcast]# cat map.py
import sys
import os
def get_file_handler(f):
"""读取文件"""
file_in=open(f,'r')
return file_in
def get_cachefile_handlers(f):
"""将目录里的所有文件读取到list中"""
f_handlers_list=[]
if os.path.isdir(f):
for fd in os.listdir(f):
f_handlers_list.append(get_file_handler(f+'/'+fd))
return f_handlers_list
def read_local_file_func(f):
"""把cachefile文件内容拆分成单词存入set()中"""
word_set=set()
for cachefile in get_cachefile_handlers(f):
for line in cachefile:
word_set.add(line.strip())
return word_set
def mapper_func(white_file):
"""执行map()环节"""
word_set=read_local_file_func(white_file)
for line in sys.stdin:
ss=line.strip().split(' ')
for s in ss:
word=s.strip()
if word!=""and (word in word_set):
print "%s\t%s" % (s,1)
if __name__ == '__main__':
module=sys.modules[__name__]
func=getattr(module,sys.argv[1])
args=None
if len(sys.argv)>1:
args=sys.argv[2:]
func(*args)
[root@master mr_cachearchive_broadcast]# cat run.sh
HADOOP_CMD="/usr/local/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/123.txt"
OUTPUT_PATH="/output_cachearchive_demo"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func WH.gz" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=2" \
-jobconf "mapred.job.name=cachefile_demo" \
-cacheArchive "hdfs://master:9000/w.tar.gz#WH.gz" \
-file ./map.py \
-file ./red.py \
#-cacheArchive "$HDFS_FILE_PATH#ZIP_FILE_NAME" \
▲-cacheArchive “hdfs://master:9000/w.tar.gz#WH.gz” \ 分发cacheArchive文件
注:
- 使用-cacheArchive时传入的文件必须为压缩文件,因此必须在项目目录中提前把文件打包
- cacheArchive中A为大写;
- WH.gz为文件别名,前面带#;
- 跑任务之前要把w.tar.gz(压缩文件)、123.txt 上传到HDFS上
4.4 compression(压缩)
压缩的作用
- 输出数据量较大时,可以使用Hadoop提供的压缩机制对数据进行压缩,减少网络传输带宽和存储的消耗。
- 可以指定对map的输出也就是中间结果进行压缩
- 可以指定对reduce的输出也就是最终输出进行压缩
- 可以指定是否压缩以及采用哪种压缩方式。
- 对map输出进行压缩主要是为了减少shuffle过程中网络传输数据量
- 对reduce输出进行压缩主要是减少输出结果占用的HDFS存储。
[root@master mr_compression]# ls
map.py red.py run.sh tmp
[root@master mr_compression]# cat map.py
import sys
import os
def get_file_handler(f):
file_in=open(f,'r')
return file_in
def get_cachefile_handlers(f):
f_handlers_list=[]
if os.path.isdir(f):
for fd in os.listdir(f):
f_handlers_list.append(get_file_handler(f+'/'+fd))
return f_handlers_list
def read_local_file_func(f):
word_set=set()
for cachefile in get_cachefile_handlers(f):
for line in cachefile:
word_set.add(line.strip())
return word_set
def mapper_func(white_file):
word_set=read_local_file_func(white_file)
for line in sys.stdin:
ss=line.strip().split(' ')
for s in ss:
word=s.strip()
if word!=""and (word in word_set):
print "%s\t%s" % (s,1)
if __name__ == '__main__':
module=sys.modules[__name__]
func=getattr(module,sys.argv[1])
args=None
if len(sys.argv)>1:
args=sys.argv[2:]
func(*args)
[root@master mr_compression]# cat red.py
import sys
def reducer_func():
current_word=None
count_pool=[]
sum=0
for line in sys.stdin:
word,value=line.strip().split()
if current_word==None:
current_word=word
if current_word!=word:
for count in count_pool:
sum+=count
print "%s\t%s" % (current_word,str(sum))
current_word=word
count_pool=[]
sum=0
count_pool.append(int(value))
for count in count_pool:
sum+=count
print "%s\t%s" % (current_word,str(sum))
if __name__ == '__main__':
module=sys.modules[__name__]
func=getattr(module,sys.argv[1])
args=None
if len(sys.argv)>1:
args=sys.argv[2:]
func(*args)
[root@master mr_compression]# cat run.sh
HADOOP_CMD="/usr/local/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/123.txt"
OUTPUT_PATH="/output_compression_demo"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py mapper_func WH.gz" \
-reducer "python red.py reducer_func" \
-jobconf "mapred.reduce.tasks=10" \ #设置reduce个数,结果会输出10个压缩包
-jobconf "mapred.job.name=compression_demo" \ #定义任务名字
-jobconf "mapred.compress.map.output=true" \ #对map结果压缩
-jobconf "mapred.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ #设置压缩方式为gzip
-jobconf "mapred.output.compress=true" \ #对输出结果压缩
-jobconf "mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec" \ #设置压缩方式为gzip
-cacheArchive "hdfs://master:9000/w.tar.gz#WH.gz" \
-file ./red.py \ #分发本地的map程序到计算节点
#-cacheArchive "$HDFS_FILE_PATH#ZIP_FILE_NAME" \ #分发本地的reduce程序到计算节点
[root@master mr_compression]# bash run.sh
rmr: DEPRECATED: Please use 'rm -r' instead.
rmr: `/output_compression_demo': No such file or directory
19/08/01 23:15:05 WARN streaming.StreamJob: -file option is deprecated, please use generic option -files instead.
19/08/01 23:15:07 WARN streaming.StreamJob: -cacheArchive option is deprecated, please use -archives instead.
19/08/01 23:15:07 WARN streaming.StreamJob: -jobconf option is deprecated, please use -D instead.
19/08/01 23:15:07 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
19/08/01 23:15:07 INFO Configuration.deprecation: mapred.job.name is deprecated. Instead, use mapreduce.job.name
19/08/01 23:15:07 INFO Configuration.deprecation: mapred.compress.map.output is deprecated. Instead, use mapreduce.map.output.compress
19/08/01 23:15:07 INFO Configuration.deprecation: mapred.map.output.compression.codec is deprecated. Instead, use mapreduce.map.output.compress.codec
19/08/01 23:15:07 INFO Configuration.deprecation: mapred.output.compress is deprecated. Instead, use mapreduce.output.fileoutputformat.compress
19/08/01 23:15:07 INFO Configuration.deprecation: mapred.output.compression.codec is deprecated. Instead, use mapreduce.output.fileoutputformat.compress.codec
packageJobJar: [./map.py, ./red.py, /tmp/hadoop-unjar4256746077156415342/] [] /tmp/streamjob8410134736400209185.jar tmpDir=null
19/08/01 23:15:10 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.168.10:8032
19/08/01 23:15:10 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.168.10:8032
19/08/01 23:15:32 INFO mapred.FileInputFormat: Total input paths to process : 1
19/08/01 23:15:34 INFO mapreduce.JobSubmitter: number of splits:2
19/08/01 23:15:37 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1564672032511_0002
19/08/01 23:15:40 INFO impl.YarnClientImpl: Submitted application application_1564672032511_0002
19/08/01 23:15:40 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1564672032511_0002/
19/08/01 23:15:40 INFO mapreduce.Job: Running job: job_1564672032511_0002
19/08/01 23:16:26 INFO mapreduce.Job: Job job_1564672032511_0002 running in uber mode : false
19/08/01 23:16:26 INFO mapreduce.Job: map 0% reduce 0%
19/08/01 23:17:05 INFO mapreduce.Job: map 33% reduce 0%
19/08/01 23:17:13 INFO mapreduce.Job: map 100% reduce 0%
19/08/01 23:18:50 INFO mapreduce.Job: map 100% reduce 33%
19/08/01 23:18:53 INFO mapreduce.Job: map 100% reduce 43%
19/08/01 23:18:56 INFO mapreduce.Job: map 100% reduce 50%
19/08/01 23:20:00 INFO mapreduce.Job: map 100% reduce 70%
19/08/01 23:20:04 INFO mapreduce.Job: map 100% reduce 80%
19/08/01 23:20:25 INFO mapreduce.Job: map 100% reduce 90%
19/08/01 23:21:10 INFO mapreduce.Job: map 100% reduce 100%
19/08/01 23:21:40 INFO mapreduce.Job: Job job_1564672032511_0002 completed successfully
19/08/01 23:21:42 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=511
FILE: Number of bytes written=1337465
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=10193
HDFS: Number of bytes written=230
HDFS: Number of read operations=36
HDFS: Number of large read operations=0
HDFS: Number of write operations=20
Job Counters
Killed reduce tasks=6
Launched map tasks=2
Launched reduce tasks=15
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=97069
Total time spent by all reduces in occupied slots (ms)=2012307
Total time spent by all map tasks (ms)=97069
Total time spent by all reduce tasks (ms)=2012307
Total vcore-milliseconds taken by all map tasks=97069
Total vcore-milliseconds taken by all reduce tasks=2012307
Total megabyte-milliseconds taken by all map tasks=99398656
Total megabyte-milliseconds taken by all reduce tasks=2060602368
Map-Reduce Framework
Map input records=9
Map output records=126
Map output bytes=697
Map output materialized bytes=608
Input split bytes=156
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=608
Reduce input records=126
Reduce output records=5
Spilled Records=252
Shuffled Maps =20
Failed Shuffles=0
Merged Map outputs=20
GC time elapsed (ms)=2025
CPU time spent (ms)=21810
Physical memory (bytes) snapshot=1279275008
Virtual memory (bytes) snapshot=24994414592
Total committed heap usage (bytes)=418775040
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=10037
File Output Format Counters
Bytes Written=230
19/08/01 23:21:42 INFO streaming.StreamJob: Output directory: /output_compression_demo
# 查看输出的文件
[root@master mr_compression]# hadoop fs -ls /output_compression_demo
Found 11 items
-rw-r--r-- 3 root supergroup 0 2019-08-01 23:21 /output_compression_demo/_SUCCESS
-rw-r--r-- 3 root supergroup 20 2019-08-01 23:18 /output_compression_demo/part-00000.gz
-rw-r--r-- 3 root supergroup 25 2019-08-01 23:20 /output_compression_demo/part-00001.gz
-rw-r--r-- 3 root supergroup 27 2019-08-01 23:18 /output_compression_demo/part-00002.gz
-rw-r--r-- 3 root supergroup 27 2019-08-01 23:20 /output_compression_demo/part-00003.gz
-rw-r--r-- 3 root supergroup 26 2019-08-01 23:18 /output_compression_demo/part-00004.gz
-rw-r--r-- 3 root supergroup 20 2019-08-01 23:20 /output_compression_demo/part-00005.gz
-rw-r--r-- 3 root supergroup 20 2019-08-01 23:18 /output_compression_demo/part-00006.gz
-rw-r--r-- 3 root supergroup 20 2019-08-01 23:20 /output_compression_demo/part-00007.gz
-rw-r--r-- 3 root supergroup 25 2019-08-01 23:18 /output_compression_demo/part-00008.gz
-rw-r--r-- 3 root supergroup 20 2019-08-01 23:21 /output_compression_demo/part-00009.gz
4.5 全局排序(单个reduce)
[root@master mr_allsort]# ls
a.txt b.txt map_sort.py red_sort.py run.sh
[root@master mr_allsort_1reduce_python]# cat map_sort.py
#!/usr/local/bin/python
import sys
#base_count = 10000
base_count = 99999
for line in sys.stdin:
ss = line.strip().split('\t')
key = ss[0]
val = ss[1]
new_key = base_count - int(key)
#new_key = base_count + int(key)
print "%s\t%s" % (new_key, val)
[root@master mr_allsort]# cat red_sort.py
#!/usr/local/bin/python
import sys
#base_value = 10000
base_value = 99999
for line in sys.stdin:
key, val = line.strip().split('\t')
#print str(int(key) - base_value) + "\t" + val
print str(base_value - int(key)) + "\t" + val
#降序: print str(int(key) - base_value) + "\t" + val
#升序: print str(int(key) + base_value) + "\t" + val
[root@master mr_allsort]# cat run.sh
#set -e -x
HADOOP_CMD="/usr/local/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_A="/a.txt"
INPUT_FILE_PATH_B="/b.txt"
OUTPUT_SORT_PATH="/output_sort"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH
# Step 3.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B\
-output $OUTPUT_SORT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-jobconf "mapred.reduce.tasks=1" \
-file ./map_sort.py \
-file ./red_sort.py \
4.6 全局排序(多个reduce)
[root@master mr_allsort_test]# ls
a.txt b.txt map_sort.py red_sort.py result.txt run.sh
[root@master mr_allsort_test]# cat a.txt
1 hadoop
3 hadoop
5 hadoop
7 hadoop
9 hadoop
[root@master mr_allsort_test]# cat b.txt
0 java
2 java
4 java
6 java
8 java
10 java
[root@master mr_allsort_test]# cat map_sort.py
import sys
base_count = 10000
for line in sys.stdin:
ss = line.strip().spit('\t')
key = ss[0]
val = ss[1]
new_key = base_count + int(key)
red_idx = 1
if new_key < (10000 + 10010) / 2:
red_idx = 0
#print str(red_idx)+'\t'+str(new_key)+'\t'+val
print "%s\t%s\t%s" % (red_idx, new_key, val)
[root@master mr_allsort_test]# cat red_sort.py
import sys
base_count = 10000
for line in sys.stdin:
idx_id, key, val = line.strip().split('\t')
new_key = int(key) - base_count
print '\t'.join([str(new_key), val])
[root@master mr_allsort_test]# cat run.sh
HADOOP_CMD="/usr/local/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_A="/a.txt"
INPUT_FILE_PATH_B="/b.txt"
OUTPUT_PATH="/output_allsort_test_1"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-D "stream.non.zero.exit.is.failure=false" \
-D mapred.reduce.tasks=2 \
-D stream.num.map.output.key.fields=2 \
-D num.key.fields.for.partition=1 \
-files ./map_sort.py \
-files ./red_sort.py \
-input $INPUT_FILE_PATH_A,$INPUT_FILE_PATH_B \
-output $OUTPUT_PATH \
-mapper "python map_sort.py" \
-reducer "python red_sort.py" \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
解释:
Hadoop streaming框架默认情况下会以’/t’作为分隔符,将每行第一个’/t’之前的部分作为key,其余内容作为value,如果没有’/t’分隔符,则整行作为key;这个key/tvalue对又作为该map对应的reduce的输入,有时可以设置
- -D stream.num.map.output.key.fields: map中分隔符的位置,分隔符前为key,后为reduce
- -D num.key.fields.for.partition: 分桶时,key按前面指定的分隔符分隔之后,用于分桶的key占的列数。通俗地讲,就是partition时候按照key中的前几列进行划分,相同的key会被打到同一个reduce里。
- -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner :控制分发,完成二次排序(Java类)
4.7 共同好友
问题:使用MR实现返回共同好友原始数据:A:B,C,D,F,E,O B:A,C,E,K C:F,A,D,I (单向好友,类似微博关注)返回结果:A,B的共同好友有:C和E; A,C用户的共同好友有:D和F
分析:分为两个两个步骤,两次MapReduce
1)求出每一个人都是哪些人的共同好友
2)把这些人(用共同好友的人)作为key,其好友作为value输出。
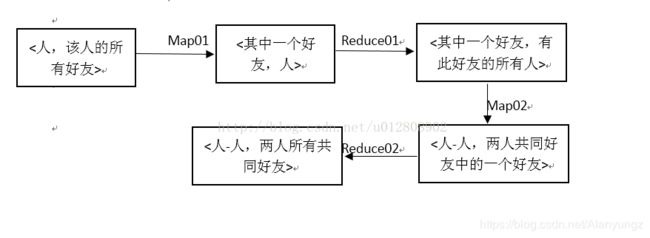
代码:
[root@master mr_mutual_friends]# ls
map_1.py map_2.py person_friends.txt reduce_1.py reduce_2.py run.sh
[root@master mr_mutual_friends]# cat person_friends.txt
A B,C,D,E,F,O
B A,E,C,K
C A,D,F,I
# 第一次MR
[root@master mr_mutual_friends]# cat map_1.py
import sys
for line in sys.stdin:
ss=line.strip().split('\t')
person=ss[0]
friends=ss[1]
for friend in friends.split(','):
print "%s\t%s" % (friend,person)
[root@master mr_mutual_friends]# cat reduce_1.py
import sys
temp_friend = ''
for line in sys.stdin:
ss = line.strip().split('\t')
friend = ss[0]
person = ss[1]
if temp_friend == '':
temp_friend = friend
persons = []
if temp_friend == friend:
persons.append(person)
else :
print(temp_friend + '\t' + ','.join(per for per in persons))
temp_friend = friend
persons = []
persons.append(person)
print(temp_friend + '\t' + ','.join(per for per in persons))
#第二次MR
[root@master mr_mutual_friends]# cat map_2.py
import sys
from itertools import combinations
persons=[]
for line in sys.stdin:
ss = line.strip().split('\t')
friend = ss[0]
persons = ss[1].split(',')
if len(persons)==1:
continue
else:
person = list(combinations(persons, 2))
for per in person:
print "%s-%s: %s" % (per[0], per[1], friend)
[root@master mr_mutual_friends]# cat reduce_2.py
import sys
temp_key = ''
for line in sys.stdin:
ss = line.strip().split(': ')
key = ss[0]
value = ss[1]
if temp_key == '' :
temp_key = key
val = []
if temp_key == key :
val.append(value)
else:
print temp_key + ': ' + ','.join(v for v in val)
temp_key = key
val = []
val.append(value)
print temp_key + ': ' + ','.join(v for v in val)
结果:
[root@master mr_mutual_friends]# hadoop fs -text /output_mutual_friend/part-00000
A-C: D,F
B-A: C,E
C-B: A
这个题目需要做两个MR,第一次MR的输出作为第二个MR输入,要特别注意题目好友是指单向好友~