如何用一行代码让 gevent 爬虫提速 100%

用python做网络开发的人估计都听说过gevent这个库,gevent是一个第三方的python协程库,其是在微线程库greenlet的基础上构建而成,并且使用了epoll事件监听机制,这让gevent具有很好的性能并且比greenlet更好用。根据gevent官方的资料(网址:http://www.gevent.org),gevent具有以下特点:
基于libev或libuv的快速事件循环。
基于greenlet的轻量级执行单元。
重复使用Python标准库中的概念的API(例如,有event和 queues)。
具有SSL支持的协作套接字
通过线程池,dnspython或c-ares执行的合作DNS查询。
猴子修补实用程序,使第三方模块能够合作
TCP / UDP / HTTP服务器子流程支持(通过gevent.subprocess)
线程池
笔者总结一下,gevent大致原理就是当一个greenlet遇到需要等待的操作时(多为IO操作),比如网络IO/睡眠等待,这时就会自动切换到其他的greenlet,等上述操作完成后,再在适当的时候切换回来继续执行。在这个过程中其实仍然只有一个线程在执行,但因为我们在等待某些IO操作时,切换到了其他操作,避免了无用的等待,这就为我们大大节省了时间,提高了效率。
笔者也是在看了gevent这么多的优点之后,感觉有必要上手试一试,但起初效果非常不理想,速度提升并不大,后来在仔细研究了gevent的用法之后,发现gevent的高效率是有条件的,而其中一个重要条件就是monkey patch的使用,也就是我们常说的猴子补丁。
monkey patch就是在不改变源代码的情况下,对程序进行更改和优化,其主要适用于动态语言。通过monkey patch,gevent替换了标准库里面大部分的阻塞式系统调用,比如socket、ssl、threading和select等,而变为协作式运行。下面笔者还是通过代码来演示一下monkey patch的用法以及使用条件。笔者展示的这个程序是一个小型的爬虫程序,程序代码量少,便于阅读和运行,同时也能较好地测试出monkey patch的提升程度。主要思路是从Box Office Mojo网站抓取北美电影市场今年第二季度上映的电影,然后从每部电影的信息页面提取出每部电影的电影分级,然后把每部电影的名称和其对应分级保存在一个字典当中,再测试一下整个过程的时间。在这里,我们主要测试三种情况下的程序完成时间,分别是普通不使用gevent的爬虫,使用gevent但不用monkey patch的爬虫,以及使用gevent和monkey patch的爬虫。
首先看普通不使用gevent的爬虫。
先导入需要的库。
import time
import requests
from lxml import etree
然后读取第二季度上映电影的页面。
url = r'https://www.boxofficemojo.com/quarter/q2/2020/?grossesOption=totalGrosses' #第二季度上映电影的网址
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'} #爬虫头部
rsp = requests.get(url, headers=headers) #读取网页
text = rsp.text #获取网页源码
html = etree.HTML(text)
movie_relative_urls = html.xpath(r'//td[@class="a-text-left mojo-field-type-release mojo-cell-wide"]/a/@href') #获取每部电影的信息页面的相对地址
movie_urls = [r'https://www.boxofficemojo.com'+u for u in movie_relative_urls] #把每部电影的相对地址换成绝对地址
genres_dict = {} #用于保存信息的字典
上述代码中变量url就是第二季度上映电影的网页地址,其页面截图如图1所示。headers是爬虫模拟浏览器的头部信息,每部电影的信息页面就是图1中表格头一行列名Release下面每部电影名称所包含的网址,点击每部电影名称就可进入其对应页面。因为这个网址是相对地址,所以要转换成绝对地址。
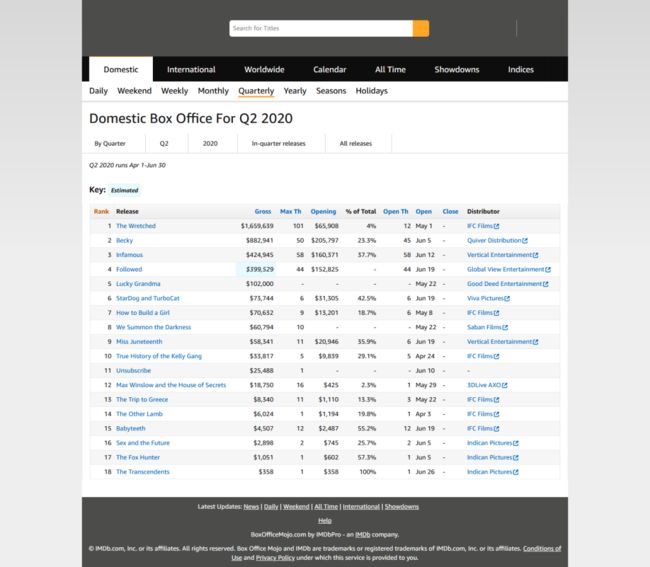
图1. 第二季度上映电影的页面
接下来是每部电影的信息页面的读取。
def spider(url): #这个函数主要用于读取每部电影页面中的电影分级信息
rsp = requests.get(url, headers=headers) #读取每部电影的网页
text = rsp.text #获取页面代码
html = etree.HTML(text)
genre = html.xpath(r'//div/span[text()="Genres"]/following-sibling::span[1]/text()')[0] #读取电影分级信息
title = html.xpath(r'//div/h1/text()')[0] #读取电影名称
genres_dict[title] = genre #把每部电影的名称和分级信息存入字典
这个函数就是为了读取每部电影信息页面的信息,其功能和上面读取url页面的功能类似,都非常简单,没有过多可说的。在每部电影页面中,我们要读取的每部电影的分级信息就在Genres这一行,比如图2中电影The Wretched,其Genres信息就是Horror。
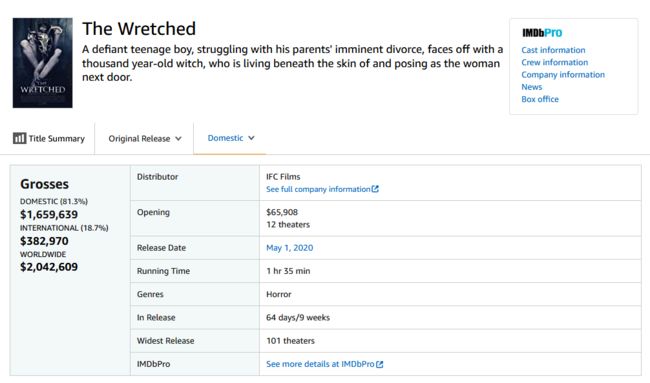
图2. 示例电影信息页面
接下来是时间测算。
normal_start = time.time() #程序开始时间
for u in movie_urls:
spider(u)
normal_end = time.time() #程序结束时间
normal_elapse = normal_end - normal_start #程序运行时间
print('The normal procedure costs %s seconds' % normal_elapse)
我们测算时间用time.time()方法,用结束时间减去开始时间就是程序运行时间,这里我们主要测试spider这个函数多次运行的时间。结果显示,该过程耗时59.6188秒。
第二个爬虫是使用gevent但不用monkey patch的爬虫。其完整代码如下。
import time
from lxml import etree
import gevent
import requests
url = r'https://www.boxofficemojo.com/quarter/q2/2020/?grossesOption=totalGrosses'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
rsp = requests.get(url, headers=headers)
text = rsp.text
html = etree.HTML(text)
movie_relative_urls = html.xpath(r'//td[@class="a-text-left mojo-field-type-release mojo-cell-wide"]/a/@href')
movie_urls = [r'https://www.boxofficemojo.com'+u for u in movie_relative_urls]
genres_dict = {}
task_list = [] #用于存放协程的列表
def spider(url):
rsp = requests.get(url, headers=headers)
text = rsp.text
html = etree.HTML(text)
genre = html.xpath(r'//div/span[text()="Genres"]/following-sibling::span[1]/text()')[0]
title = html.xpath(r'//div/h1/text()')[0]
genres_dict[title] = genre
gevent_start = time.time()
for u in movie_urls:
task = gevent.spawn(spider, u) #生成协程
task_list.append(task) #把协程放入这个列表
gevent.joinall(task_list) #运行所有协程
gevent_end = time.time()
gevent_elapse = gevent_end - gevent_start
print('The gevent spider costs %s seconds' % gevent_elapse)
这里绝大部分代码和前面爬虫代码相同,但多了一个task_list变量,其是用于存放协程的列表,我们从gevent_start = time.time()这行开始看,因为前面的代码都和之前的爬虫相同。task = gevent.spawn(spider, u)是生成gevent中生成协程的方法,task_list.append(task)是把每个协程放入这个列表中,而gevent.joinall(task_list)就是运行所有协程。上面这些过程和我们运行多线程的方式非常相似。运行结果是59.1744秒。
最后一个爬虫就是同时使用gevent和monkey patch的爬虫,在这里笔者不再粘贴代码,因为其代码和第二个爬虫几乎一模一样,只有一个区别,就是多了一行代码from gevent import monkey; monkey.patch_all(),注意这是一行代码,不过包含两个语句,用分号放在了一起。最重要的是,这行代码要放在所有代码的前面,切记!!!
这个爬虫的运行结果是26.9184秒。
笔者把这里三个爬虫分别放在三个文件中,分别命名为normal_spider.py、gevent_spider_no.py和gevent_spider.py,分别表示普通不用gevent的爬虫、使用gevent但不用monkey patch的爬虫、使用gevent和monkey patch的爬虫。这里有一点要注意,monkey patch暂不支持jupyter notebook,所以这三个程序要在命令行中使用,不能在notebook中使用。
最后把三种爬虫的结果总结如下。

图3. 三种爬虫的结果对比
可以看出使用了gevent但不用monkey patch的爬虫和普通爬虫的运行时间几乎完全相等,而在用了monkey patch以后,运行时间只有前面程序的一半不到,速度提升了大约120%,仅仅一行代码就带来如此大的速度提升,可见monkey patch的作用还是很大的。而对于前两个爬虫的速度几乎完全一样,笔者认为原因在于这两个程序都是单线程运行,本质上没有太大区别,同时网页读取数量较小(只有18个网页),也很难看出gevent的效果。
从本例中可以看出monkey patch还是有不小提升的,但gevent目前只对常见库尤其是官方标准库有patch作用,其他第三方库的效果还不得而知,所以对monkey patch的使用还是要视情况而定。本文的代码笔者放在gitee代码网站上,网址是https://gitee.com/leonmovie/speed-up-gevent-spider-with-monkey-patch,如有需要可以自行下载。
作者简介:Mort,数据分析爱好者,擅长数据可视化,比较关注机器学习领域,希望能和业内朋友多学习交流。
赞 赏 作 者

Python中文社区作为一个去中心化的全球技术社区,以成为全球20万Python中文开发者的精神部落为愿景,目前覆盖各大主流媒体和协作平台,与阿里、腾讯、百度、微软、亚马逊、开源中国、CSDN等业界知名公司和技术社区建立了广泛的联系,拥有来自十多个国家和地区数万名登记会员,会员来自以工信部、清华大学、北京大学、北京邮电大学、中国人民银行、中科院、中金、华为、BAT、谷歌、微软等为代表的政府机关、科研单位、金融机构以及海内外知名公司,全平台近20万开发者关注。

推荐阅读:
一文读懂高并发情况下的常见缓存问题
用 Django 开发基于以太坊智能合约的 DApp
一文读懂 Python 分布式任务队列 celery
5 分钟解读 Python 中的链式调用
用 Python 创建一个比特币价格预警应用
▼点击成为社区会员 喜欢就点个在看吧