SQL语句基本操作练习(三)
文章目录
- SQL语句基操(三)
- 一、单表查询
- 2、选择表中的若干元组。
- (2) 查询满足条件的元组
- ④字符匹配
- [例3.29] 查询学号为201215121的学生的详细情况。
- [例3.30] 查询所有姓刘学生的姓名、学号和性别。
- [例3.31] 查询姓"欧阳"且全名为三个汉字的学生的姓名。
- [例3.32] 查询名字中第2个字为"阳"字的学生的姓名和学号。
- [例3.33] 查询所有不姓刘的学生姓名、学号和性别。
- [例3.34] 查询DB_Design课程的课程号和学分。
- [例3.35] 查询以"DB_"开头,且倒数第3个字符为 i的课程的详细情况。
- ⑤涉及空值的查询
- [例3.36] 某些学生选修课程后没有参加考试,所以有选课记录,但没 有考试成绩。查询缺少成绩的学生的学号和相应的课程号。
- [例3.37] 查所有有成绩的学生学号和课程号。
- ⑥多重条件查询
- [例3.38] 查询计算机系年龄在20岁以下的学生姓名。
- 3、ORDER BY 子句
- [例3.39]查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列。
- [例3.40]查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
- 4、聚集函数
- [例3.41] 查询学生总人数。
- [例3.42] 查询选修了课程的学生人数。
- [例3.43] 计算1号课程的学生平均成绩。
- [例3.44] 查询选修1号课程的学生最高分数。
- [例3.45 ] 查询学生201215121选修课程的总学分数。
- GROUP BY 子句
- [例3.46] 求各个课程号及相应的选课人数。
- [例3.47] 查询选修了3门以上课程的学生学号。
- [例3.48 ]查询平均成绩大于等于90分的学生学号和平均成绩
SQL语句基操(三)
本篇文章记录了第六次作业
使用的数据库是SQL Server,使用的数据库管理软件是SQL Server Management Studio.
接上一篇文章:SQL语句基本操作练习(二)——INDEX-INSERT-SELECT.
大家好,又回来了(休息了二十分钟),上次我们说到“确定范围",这次我们从字符匹配开始说吧。
一、单表查询
2、选择表中的若干元组。
(2) 查询满足条件的元组
④字符匹配
我们用谓词LIKE来进行字符串的匹配,一般语法格式如下:[NOT] LIKE ‘<匹配串>’ [ESCAPE ‘ <换码字符>’]
这个语句的意思是查找指定的属性列值和<匹配串>相匹配的元组。<匹配串>可以是完整的字符串也可以包含通配符%和_这俩。
下面来讲讲通配符:
- % (百分号) 代表任意长度(长度可以为0)的字符串。例如a%b即代表以a开头b结尾的任意长度字符串,可以表示acb、asgsgb、ab等。
- _ (下横线) 代表任意单个字符。比如a_b可以代表acb、a1b等串。
下面来几个例题。
[例3.29] 查询学号为201215121的学生的详细情况。
SELECT *
FROM Student
WHERE Sno LIKE '201215121';
/*或者是*/
SELECT *
FROM Student
WHERE Sno = '201215121';
这里由于LIKE后面接的是一个具体的字符串,所以是等价与第二个语句的。同理,NOT LIKE可以用!=或者<>(都是不等于的意思)等价替换。
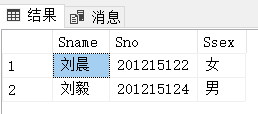
[例3.30] 查询所有姓刘学生的姓名、学号和性别。
SELECT Sname, Sno, Ssex
FROM Student
WHERE Sname LIKE '刘%';
这里很容易理解,就是在查询姓名、学号和性别的SQL语句后面加上了名字限定:以‘刘’开头的字符串,即刘姓。
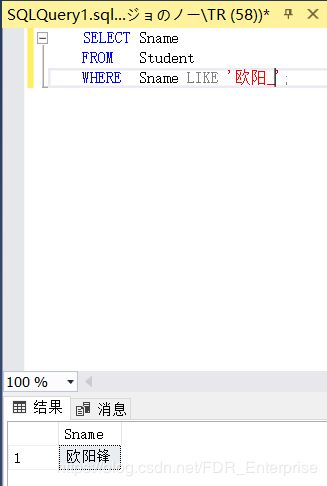
[例3.31] 查询姓"欧阳"且全名为三个汉字的学生的姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳__'; /*这里是俩_*/
按书上来说,数据库字符集为ASCII时一个汉字需要两个_;字符集为GBK时只需要一个_。在我的机子上测试的是一个下划线代表一个汉字。目前没有测试更多的数据类型不知道对字符集有没有影响,姑且认为SQL Server中均是一个下划线代表一个汉字。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳_'; /*SQL Server中使用一个下划线*/
结果:
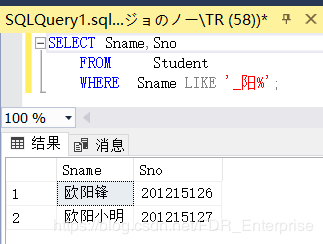
[例3.32] 查询名字中第2个字为"阳"字的学生的姓名和学号。
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE '_阳%'; /*书上是俩_,我这改成一个了*/
结果如下:
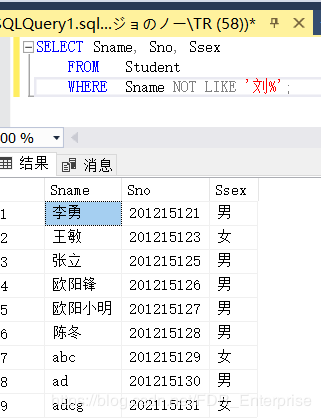
[例3.33] 查询所有不姓刘的学生姓名、学号和性别。
SELECT Sname, Sno, Ssex
FROM Student
WHERE Sname NOT LIKE '刘%';
这一题是对NOT LIKE 的运用。
在一开始的格式中我们讲解了通配符,但是并没有对ESCAPE’<换码字符>'进行分析,现在我们来了解以下。以下题为例:
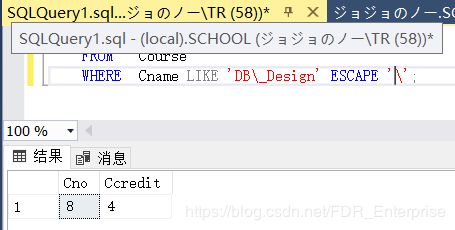
[例3.34] 查询DB_Design课程的课程号和学分。
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE 'DB\_Design' ESCAPE '\';
这里的ESCAPE ‘’ 表示 \ 为换码字符,在匹配串中紧跟在 \ 后面的字符 _ 不再具有通配符含义,变为普通的字符串中的” _ “。执行结果如下:
另外经过测试,换码字符也可以是别的字符,这就意味着你可以选择你觉得方便的字符作为换码字符。例如:
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE 'DB-_Design' ESCAPE '-'; /*经过测试可以使用*/
[例3.35] 查询以"DB_"开头,且倒数第3个字符为 i的课程的详细情况。
SELECT *
FROM Course
WHERE Cname LIKE 'DB\_%i__' ESCAPE'\';
代码中第一个 _ 因为换码字符的原因变成普通的 _ ,后面的%i__,因为没有 \ ,所以它们仍然是通配符。
⑤涉及空值的查询
我们这里用到的关键词是IS NULL 和 IS NOT NULL,这里面的IS 是不能用 = 代替的。
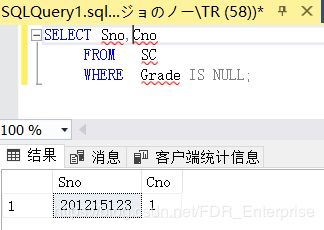
[例3.36] 某些学生选修课程后没有参加考试,所以有选课记录,但没 有考试成绩。查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NULL;
结果如下:
[例3.37] 查所有有成绩的学生学号和课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
⑥多重条件查询
我们可以用逻辑运算符AND和OR来连接多个查询条件,一般来说AND的优先级高于OR,但是用户可以用括号改变优先级。这个意思就是像加减乘除四则运算里面那样用括号来改变优先级。
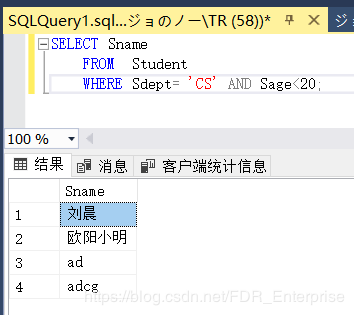
[例3.38] 查询计算机系年龄在20岁以下的学生姓名。
SELECT Sname
FROM Student
WHERE Sdept= 'CS' AND Sage<20;
结果如下:
而例题3.27 查询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别中使用了IN谓词,可以将其改写成如下形式:
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ('CS','MA','IS');
/*改写为*/
SELECT Sname,Ssex
FROM Student
WHERE Sdept= 'CS' OR Sdept= 'MA' OR Sdept= 'IS';
讲了这么多了,中场休息一下。

3、ORDER BY 子句
这些子句的作用就是让用户能对查询结果进行排序后输出,默认为升序。而对于空值,排序时显示的次序由具体数据库系统实现来决定,可能放在最前面也可能放在最后输出。
[例3.39]查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列。
SELECT Sno, Grade
FROM SC
WHERE Cno= '3'
ORDER BY Grade DESC;
前三句都很好理解,加了个ORDER BY也没有变得更复杂,毕竟它简单明了就是按分数降序排列。
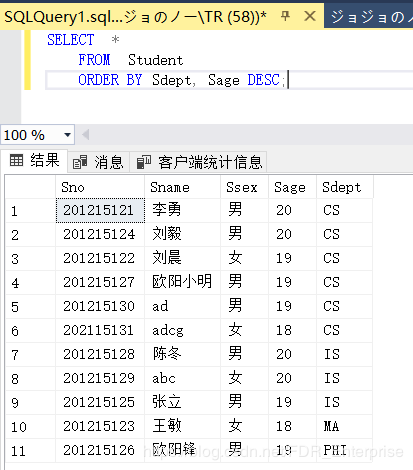
[例3.40]查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept, Sage DESC;
类似的操作我们在建立索引中做过,对于多个排序,先根据在前面的属性列排,然后再按后面的属性列排。结果如下:
4、聚集函数
聚集函数有点像Excel或者说C语言里面的库函数,都是开发者定义后用户可以直接调用的实用性函数,主要有以下几个函数:
- 统计元组个数 COUNT(*)
- 统计一列中值的个数 COUNT([DISTINCT|ALL] <列名>)
- 计算一列值的总和 SUM([DISTINCT|ALL] <列名>)
- 计算一列值的平均值 AVG([DISTINCT|ALL] <列名>)
- 求一列中的最大值和最小值 MAX([DISTINCT|ALL] <列名>) MIN([DISTINCT|ALL] <列名>)
我们注意到里面使用了DISTINCT和ALL,这是在之前的去除重复值的语句讲解里面用到的。详情可以看之前的文章,此处不再赘述。
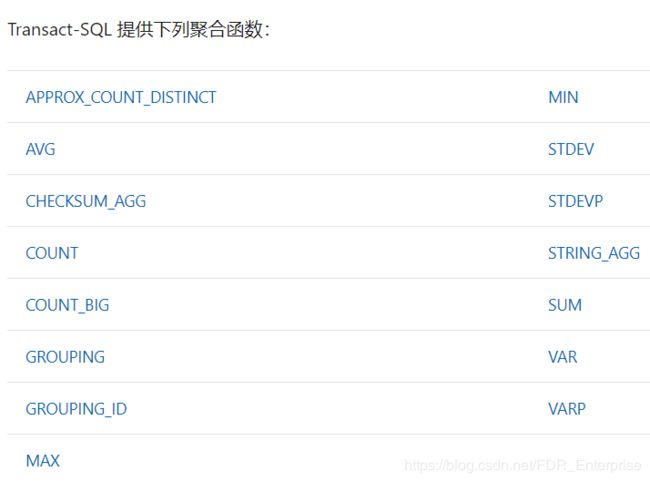
还有一些别的聚合函数,以下是微软Transact-SQl文档中提供的SQL Server中的聚合函数:
[例3.41] 查询学生总人数。
SELECT COUNT(*) /*这里的*可以替换成相应的属性列,如Sno,不过好像都差不多哈*/
FROM Student;
[例3.42] 查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno) /*这里的DISTINCT去掉了重复的Sno值,来统计真正的选课人数*/
FROM SC;
[例3.43] 计算1号课程的学生平均成绩。
SELECT AVG(Grade)
FROM SC
WHERE Cno= '1';
[例3.44] 查询选修1号课程的学生最高分数。
SELECT MAX(Grade)
FROM SC
WHERE Cno='1';
[例3.45 ] 查询学生201215121选修课程的总学分数。
SELECT SUM(Ccredit) /*该名学生选了3门课,都是4学分的,与结果相符*/
FROM SC,Course
WHERE Sno='201215121' AND SC.Cno=Course.Cno; /*这里涉及到一点关系代数部分,可以看之前的文章*/
3.45结果: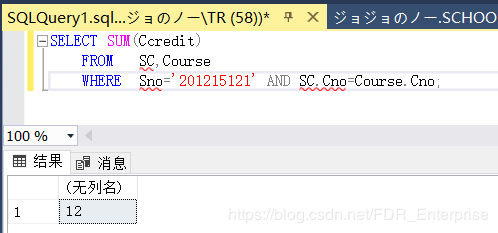
这里的例子没有体现,当聚集函数遇到空值时,除了COUNT(*)外(是否为空对这个函数的意义没有影响),都会跳过空值进行处理。另外WHERE子句中不能使用聚集函数做条件表达式,只能用于SELECT子句和GROUP BY中的 HAVING子句。(这一点在GROUP BY 子句的例子中有体现)
GROUP BY 子句
该子句是用来将查询结果按照某一列或多列的值分组,值相等的为一组。如果没有分组的话,聚集函数是直接作用于整个查询结果的。而查询结果分组后,聚集函数将分别作用于每个组,这样能够更加细化聚合函数的使用。
[例3.46] 求各个课程号及相应的选课人数。
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;
结果如下:

如果没有使用GROUP BY子句的话,查询结果返还的是Sno的总数,在这里是6。而分组过后每个课程都统计到了它被选中的次数——都是2。这样的确方便了我们统计和分析数据。
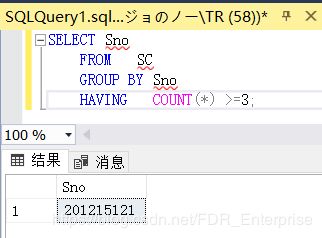
[例3.47] 查询选修了3门以上课程的学生学号。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*) >3; /*用HAVING短语指定筛选条件*/
/*这里先用GROUP BY分组了,再用HAVING筛选分组,把需要的结果提了出来*/
因为我的数据库里没有选课数大于3的,所以我改成了大于等于3,结果如下:
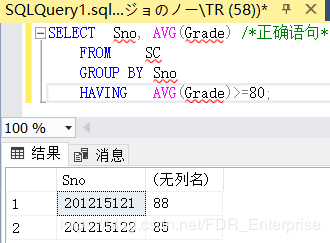
[例3.48 ]查询平均成绩大于等于90分的学生学号和平均成绩
SELECT Sno, AVG(Grade)
FROM SC
WHERE AVG(Grade)>=90
GROUP BY Sno;
/*上面一段是错误的,因为它在WHERE中使用了聚集函数做条件表达式*/
/*HAVING 作用于组,WHERE作用于基表或视图*/
SELECT Sno, AVG(Grade) /*正确语句*/
FROM SC
GROUP BY Sno
HAVING AVG(Grade)>=90; /*我的数据库里没有平均分大于90的学生wwww*/
鉴于我的数据库里的学生成绩都不太好,改成80终于得到了输出结果:
单表查询至此告一段落,感谢大家的支持,觉得有用的还请你帮我在右上角点个~~

下一篇文章:SQL语句基本操作练习(四)
参考文献:
[1]萨师煊,王珊,数据库系统概论.5版.北京:高等教育出版社,2014.
[2]David老师的PPT.