卷积神经网络的经典结构与PyTorch实现
(文章同步更新在个人博客@dai98.github.io)
前一篇文章已经介绍了卷积神经网络主要结构的特征与原理,这一篇文章我们来了解历史上比较有名的几种卷积神经网络结构,并用PyTorch实现网络结构。
注:本篇只实现了模型结构,加载模型和训练过程省略,依赖库如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
一、LeNet,1994
论文原文: Gradient-based learning applied to document recognition
手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
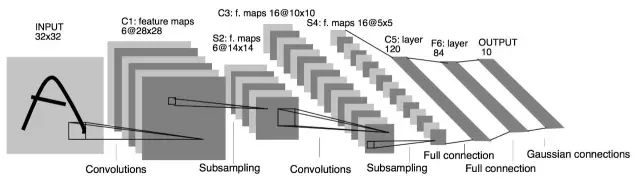
我们按照上图的结构,来实现LeNet:
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Sequential( # input size 1x28x28
# in_channel, out_channel, kernel_size, stride, padding
# size = [(input_size - kernel_size + padding * 2) / stride] + 1
nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,stride=1,padding=2),
nn.ReLU(), # input size 6x28x28
# kernel_size, stride
nn.MaxPool2d(kernel_size=2,stride=2) # output size 6x14x14
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5), # input size 6x14x14
nn.ReLU(), # input size 16x10x10
nn.MaxPool2d(kernel_size=2,stride=2) # output size 16x5x5
)
self.fc1 = nn.Sequential(
nn.Linear(5 * 5 * 16, 120)
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
# Squeeze the matrix into a vector
x = x.reshape(x.size()[0],-1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
二、AlexNet,2012
论文原文: ImageNet Classification with Deep Convolutional Neural Network
AlexNet由Alex Krizhevsky于2012年提出,夺得2012年ILSVRC比赛的冠军,top5预测的错误率为16.4%,它以领先第二名10%的准确率夺得冠军,并且成功的向世界展示了深度学习的魅力。
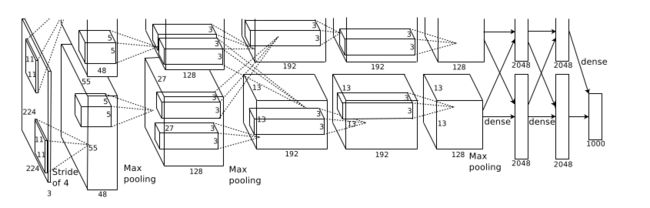
class AlexNet(nn.Module)
def __init__(self):
super(AlexNet, self).__init__()
self.conv1 = nn.Sequential(
# input_size 227x227x3
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding = 0),
# input_size
# (227 - 11 + 0 * 2) / 4 + 1 = 55
# 55x55x96
nn.ReLU(),
# Output Size
# (55 - 3)/2 +1 = 27
# 27x27x96
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.conv2 = nn.Sequential(
# input size 27x27x96
nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,stride=1,padding=2),
# input size
# (27 - 5 + 2*2) / 1 + 1 = 27
# 27x27x256
nn.ReLU(),
# output size
# (27-3)/2 + 1 = 13
# 13x13x256
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.conv3 = nn.Sequential(
# input size 13x13x256
nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,stride=1,padding=1),
# input size
# (13 - 3 + 1*2)/1 + 1 = 13
# 13x13x384
nn.ReLU()
)
self.conv4 = nn.Sequential(
# input size 13x13x384
nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,stride=1,padding=1),
# input size
# (13 - 3 + 1*2) / 1 + 1 = 13
# 13x13x384
nn.ReLU()
)
self.conv5 = nn.Sequential(
# input size 13x13x384
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,stride=1,padding=1),
#input size
# (13 - 3 + 2*1) / 1 + 1 =13
# 13x13x256
nn.ReLU(),
# output size
# (13 - 3) / 2 + 1 = 6
# 6x6x256
nn.MaxPool2d(kernel_size=3,stride=2)
)
self.fc6 = nn.Sequential(
nn.Linear(9216,4096),
nn.ReLU(),
nn.Dropout(0.5)
)
self.fc7 = nn.Sequential(
nn.Linear(4096,4096),
nn.ReLU(),
nn.Dropout(0.5)
)
self.fc8 = nn.Linear(4096,1000)
def forward(self,x):
out_1 = self.conv1(x)
out_2 = self.conv2(out_1)
out_3 = self.conv3(out_2)
out_4 = self.conv4(out_2)
out_5 = self.conv5(out_2)
out_5 = torch.view(out_5.size(0),-1)
out_6 = self.fc6(out_5)
out_7 = self.fc7(out_6)
out_8 = self.fc8(out_7)
return out_8
三、VGGNet,2014
论文原文: Very Deep Convolutional Network For Large Scale Image Recognition

下面的代码一次实现了VGG多个变体,是另一种实现模型的思路:
class VGG(nn.Module):
def __init__(self, features, num_classes = 1000, init_weight = True):
super(VGG,self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7,4096)
nn.ReLU(True)
nn.Dropout(0.5)
nn.Linear(4096,4096)
nn.ReLU(True)
nn.Dropout(0.5)
nn.Linear(num_classes)
)
if init_weight:
self._initialize_weight()
def forward(self,x):
x = self.features(x)
x = x.view(x.size(0),-1)
x = self.classifier(x)
return x
def _initialize_weight(self):
for m in self.modules():
if isinstance(m,nn.Conv2d):
# Size of weight matrix
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0,math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m,nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m,nn.Linear):
m.weight.data.normal_(0,0.01)
m.bias.data.zero_()
def make_layers(cfg, batch_norm = False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2,stride=2)]
else:
conv2d = nn.Conv2d(in_channels,v,kernel_size=3,padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace = True)]
else:
layers += [conv2d,nn.ReLU(inplace = True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64,'M',128,'M',256,256,'M',512,512,'M',512,512,'M'],
'B': [64,64,'M',128,128,'M',256,256,'M',512,512,'M',512,512,'M'],
'D': [64,64,'M',128,128,'M',256,256,256,'M',512,512,512,'M',512,512,512,'M'],
'E': [64,64,'M',128,128,'M',256,256,256,256,'M',512,512,512,512,'M',512,512,512,512,'M'],
}
def vgg11(**kwargs):
model = VGG(make_layers(cfg['A']), **kwargs)
return model
def vgg11_bn(**kwargs):
model = VGG(make_layers(cfg['A'], batch_norm = True), **kwargs)
return model
def vgg13(**kwargs):
model = VGG(make_layers(cfg['B']), **kwargs)
return model
def vgg13_bn(**kwargs):
model = VGG(make_layers(cfg['B'], batch_norm = True), **kwargs)
return model
def vgg16(**kwargs):
model = VGG(make_layers(cfg['D']), **kwargs)
return model
def vgg16_bn(**kwargs):
model = VGG(make_layers(cfg['D'], batch_norm = True), **kwargs)
return model
def vgg19(**kwargs):
model = VGG(make_layers(cfg['E']), **kwargs)
return model
def vgg19_bn(**kwargs):
model = VGG(make_layers(cfg['E'], batch_norm = True), **kwargs)
return model
四、GoogLeNet,2014
论文原文: Going Deeper with Convolutions

该模型的源码来自PyTorch官网,又是另外一种实现模型的思路。
我们先来实现一个单层的卷积结构:
class ConvLayer(nn.Module):
def __init__(self,in_channels,out_channels,**kwargs):
super(ConvLayer,self).__init__()
self.conv = nn.Conv2d(in_channels,out_channels,bias = False,**kwargs)
self.bn = nn.BatchNorm2d(out_channels,eps = 0.001)
def forward(self,x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace = True)
然后我们来实现Inception模块,分为主分支上的Inception模块和辅助分支上的Inception模块,我们先来看主分支上的Inception模块:

class Inception(nn.Module):
def __init__(self,in_channels,ch1x1,ch3x3red,ch3x3,ch5x5,ch5x5red,out_channels):
self.branch1 = ConvLayer(in_channels,ch1x1,kernel_size = 1)
self.branch2 = nn.Sequential(
ConvLayer(in_channels,ch3x3red,kernel_size=1),
ConvLayer(ch3x3red,ch3x3,kernel_size=3,padding=1)
)
self.branch3 = nn.Sequential(
ConvLayer(in_channels,ch5x5red,kernel_size=1),
ConvLayer(ch5x5red,ch5x5,kernel_size=3,padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1,ceil_mode=True),
ConvLayer(in_channels,out_channels,kernel_size=1)
)
def forward(self,x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1,branch2,branch3,branch4]
return torch.cat(outputs,1)
之后我们来实现辅助分类器分支上的Inception模块,参照上面模型的结构图:
class InceptionAux(nn.Module):
def __init__(self,in_channels,num_classes):
super(InceptionAux,self).__init__()
self.conv = ConvLayer(in_channels,128,kernel_size=1)
self.fc1 = nn.Linear(2048,1024)
self.fc2 = nn.Linear(1024,num_classes)
def forward(self,x):
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = x.view(x.size(0), -1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = F.dropout(x, 0.7, training=self.training)
# N x 1024
x = self.fc2(x)
# N x num_classes
return x
之后便可以搭建我们的模型了:
from collections import namedtuple
_GoogLeNetOuputs = namedtuple('GoogLeNetOuputs', ['logits', 'aux_logits2', 'aux_logits1'])
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, transform_input=False, init_weights=True):
super(GoogLeNet, self).__init__()
self.aux_logits = aux_logits
self.transform_input = transform_input
self.conv1 = BasicConv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = BasicConv2d(64, 64, kernel_size=1)
self.conv3 = BasicConv2d(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = Inception(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = Inception(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = Inception(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception(832, 384, 192, 384, 48, 128, 128)
if aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.2)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
import scipy.stats as stats
X = stats.truncnorm(-2, 2, scale=0.01)
values = torch.as_tensor(X.rvs(m.weight.numel()), dtype=m.weight.dtype)
values = values.view(m.weight.size())
with torch.no_grad():
m.weight.copy_(values)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = x.view(x.size(0), -1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
if self.training and self.aux_logits:
return _GoogLeNetOuputs(x, aux2, aux1)
return x
五、ResNet,2015
论文原文: Deep Residual Learning for Image Classification


我们同样在这里实现ResNet的不同架构,即ResNet18,ResNet34,ResNet50,ResNet101和ResNet152。其中ResNet18与ResNet34使用的是残差块是两个3x3的卷积层,其余的残差块是Bottleneck,即1x1卷积+3x3卷积+1x1卷积。
我们先来实现最基本模块:
class BasicModule(nn.Module)
expansion = 1
def __init__(self,in_channels,out_channels,stride = 1):
super(BasicModule,self).__init__()
self.cov1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=stride,padding = 1, bias = False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.cov2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=1,padding=1,bias = False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != self.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels,self.expansion* out_channels,kernel_size=1,stride=stride,bias = False),
nn.BatchNorm2d(self.expansion*out_channels)
)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(x))
out += self.shortcut(x)
out = F.relu(out)
return out
之后我们来实现Bottleneck模块,也就是1x1卷积+3x3卷积+1x1卷积:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self,in_channels,out_channels,stride=1):
super(Bottleneck,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=1,bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=stride,
padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels,self.expansion*out_channels,kernel_size=1,bias=False)
self.bn3 = bb.BatchNorm2d(self.expansion*out_channels)
self.shortcut = nn.Sequential()
if stride!=1 or in_channels != out_channels * self.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels,self.expansion*out_channels,kernel_size=1,
bias=False,stride=stride),
nn.BatchNorm2d(self.expansion*out_channels)
)
def forward(self,x):
out = self.bn1(self.conv1(x))
out = self.bn2(self.conv2(x))
out = self.bn3(self.conv3(x))
out += shortcut(x)
return F.relu(out)
两种模块实现完,我们就可以来实现ResNet的模型了:
class ResNet(nn.Module):
def __init__(self,block,num_blocks,num_classes=10):
super(ResNet,self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1,bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block,64,num_blocks,stride=1)
self.layer2 = self._make_layer(block,128,num_blocks,stride=2)
self.layer3 = self._make_layer(block,256,num_blocks,stride=2)
self.layer4 = self._make_layer(block,512,num_blocks,stride=2)
self.linear = nn.Linear(512*block.expansion,num_classes)
def _make_layer(self,block,out_channels,num_blocks,stride=1):
strides = [stride] + [1] * (stride-1)
layers = []
for stride in strides:
layers.append(block(self.in_channels,out_channels,stride))
self.in_channels = block.expansion*out_channels
return nn.Sequential(*layers)
def forward(self,x):
out = self.bn1(self.conv1(x))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out,4)
out = out.view(out.size(0),-1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicModule, [2,2,2,2])
def ResNet34():
return ResNet(BasicModule, [3,4,6,3])
def ResNet50():
return ResNet(Bottleneck, [3,4,6,3])
def ResNet101():
return ResNet(Bottleneck, [3,4,23,3])
def ResNet152():
return ResNet(Bottleneck, [3,8,36,3])
六、参考资料:
[1]. CNN几种常见网络结构及区别
[2]. CNN-常用的几种卷积神经网络
[3]. CNN几种经典模型比较
[4]. PyTorch实战1:LeNet手写数字识别
[5]. 经典CNN之:LeNet介绍
[6]. PyTorch实战:AlexNet
[7]. AlexNet网络结构分析及PyTorch代码
[8]. VGG系列(PyTorch实现)
[9]. 典型CNN结构(VGG13,16,19)
[10]. GoogLeNet的PyTorch实现
[11]. 大话CNN经典模型: GoogLeNet
[12]. PyTorch实现GoogLeNet
[13]. GoogLeNet的PyTorch实现
[14]. PyTorch实现ResNet