RC ORC Parquet之大数据文件存储格式的一哥之争
背 景
大数据如火如荼的发展中,以hadoop集群为基础的数据存储和计算框架也日新月异的精进,而如何减少存储空间又提升计算效率,一直是大数据集群老生常谈的问题,今天就一起聊聊最基本的大数据文件存储格式的区别对比,尤其是Hive建表的时候需要选择文件存储格式最为常用,
而为什么单独拎出来说RC, ORC,Parquet文件呢?而我们windows常用的文件txt,csv,excel等又怎么提都不提呢?首先,excel,word这些只适用于windows,大数据集群通常是linux集群,这些文件显然传到linux都解码不了,通常来说就是打开乱码,至于txt,csv在大数据集群用是能用,但是因为其本身压缩率低,查询效率低,行存储,而且列之间的分隔符就算取任何字符,始终都有可能和字段内包含这个分隔符本身起冲突,所以始终是个隐患,所以txt,csv,临时文件可以玩玩,大数据架构方案内,显然只能淘汰,而自带schema的json和xml显然就比txt和csv在大数据集群出名的多,但是因为压缩比,压缩空间,以及支持的架构以及文件本身可split等原因,并不是最佳文件存储格式的选择;
反观RC, ORC,Parquet三者,是当今Hive建表使用频率最多,效率相对成熟稳定,可支持列式存储,天生自带序列化和反序列化资质,而且资历也比较老的三位帅哥( 其实目前ORC基本取代了RC,RC也没什么地位了),而究竟谁才是真正的数据文件存储格式的一哥呢,请我们一探究竟。
列存储简介
看三种文件前,我们先了解下列存储,列存储和行存储的比较,当然首先要抛开极端数据模型,你不能拿单独1列n行的数据二维表来比较行列存储,这样行存储的行索引在搜索的时候有显然优势,1行n列二维表同理,那么在行列分布相对常见的n行m列的前提,下列存储和行式存储相比有哪些优势呢:
- 可以跳过不符合条件的数据,只读取需要的数据,降低 IO 数据量;
- 压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如 Run Length Encoding 和 Delta Encoding)进一步节约存储空间;
- 只读取需要的列,支持向量运算,能够获取更好的扫描性能;
- 数据分析使用的聚合统计,开窗函数,列存储操作起来有天然的快速高效优势。
关系型数据的列式存储,可以将每一列的值直接排列下来,不用引入其他的概念,也不会丢失数据。关系型数据的列式存储比l较好理解,如图1;

而嵌套类型数据的列存储则会遇到一些麻烦。如图 2 所示,我们把嵌套数据类型的一行叫做一个记录(record),嵌套数据类型的特点是一个 record 中的 column 除了可以是 Int, Long, String 这样的原语(primitive)类型以外,还可以是 List, Map, Set 这样的复杂类型。在行式存储中一行的多列是连续的写在一起的,在列式存储中数据按列分开存储,例如 (A.B.C)、( A.E) 和 (A.B.D)都是各自一列,要怎么存就很有学问了,最暴力的,这里出现的A反复存,这样对于嵌套层少的,数据量小的,存储空间上可以吃点亏,也不是不可,但是对于大数据量加嵌套层次10几层甚至更深的,这个显然就不科学了,具体怎么解决,请往下看Parquet,ORC文件的实现机制。

三种存储文件格式简介
1.Parquet文件简介
Parque支持的计算框架
Parquet 是语言无关的,而且不与任何一种数据处理框架绑定在一起,适配多种语言和组件,能够与 Parquet 配合的组件有:
- 查询引擎:
Hive, Impala, Pig, Presto, Drill, Tajo, HAWQ, IBM Big SQL - 计算框架:
MapReduce, Spark, Cascading, Crunch, Scalding, Kite - 数据模型:
Avro, Thrift, Protocol Buffers, POJOs
那么 Parquet 是如何与这些组件协作的呢?这个可以通过图3来说明。数据从内存到 Parquet 文件或者反过来的过程主要由以下三个部分组成:
存储格式 (storage format)parquet-format 项目定义了Parquet内部的数据类型、存储格式等;对象模型转换器 (object model converters)这部分功能由parquet-mr项目来实现,主要完成外部对象模型与 Parquet 内部数据类型的映射;对象模型 (object models)对象模型可以简单理解为内存中的数据表示,Avro, Thrift, Protocol Buffers, Hive SerDe, Pig Tuple, Spark SQL InternalRow等这些都是对象模型;
以上三点我们只做概念上的普及,至于底层实现的代码,可能就需要大家亲自去翻阅下源码或者例子了;
这里需要注意的是 Avro, Thrift, Protocol Buffers 都有他们自己的存储格式,但是 Parquet 并没有使用他们,而是使用了自己在parquet-format 项目里定义的存储格式。所以如果你的应用使用了 Avro 等对象模型,这些数据序列化到磁盘还是使用的 parquet-mr 定义的转换器把他们转换成 Parquet自己的存储格式,这个思想是不是很熟悉?你外界怎么处理我不管,但是跟我对接,我提供一层中间转换层,统一给你转成我这边协议一致的标准接口,很多架构都采用了这种设计理念。

Parquet数据模型
理解 Parquet 首先要理解这个列存储格式的数据模型。我们以一个下面这样的 schema 和数据为例来说明这个问题。
message AddressBook {
required string owner;
repeated string ownerPhoneNumbers;
repeated group contacts {
required string name;
optional string phoneNumber;
}
}
每个 schema 的结构是这样的:根叫做 message,message 包含多个 fields。每个 field 包含三个属性:repetition, type, name。repetition 可以是以下三种:required(出现 1 次),optional(出现 0 次或者 1 次),repeated(出现 0 次或者多次)。type 可以是一个 group 或者一个 primitive 类型(Int, Long, String)。
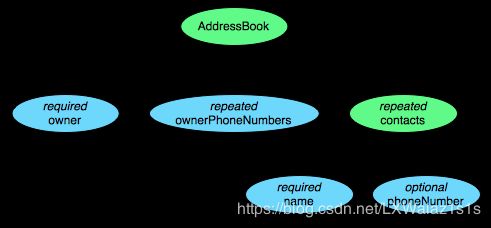
这个 schema 中每条记录表示一个人的 AddressBook。有且只有一个 owner,owner 可以有 0 个或者多个 ownerPhoneNumbers,owner 可以有 0 个或者多个 contacts。每个 contact 有且只有一个 name,这个 contact 的 phoneNumber 可有可无。这个 schema 可以用图4的树结构来表示。
Parquet 格式的数据类型没有复杂的Map, List, Set 等,而是使用 repeated fields 和 groups 来表示。例如 List 和 Set 可以被表示成一个 repeated field,Map 可以表示成一个包含有 key-value 对的 repeated field,而且 key 是 required 的,而ORC自身就有struct,map这种复杂数据类型,二者在则个设计理念就产生了偏差。
Parquet 文件的存储格式
那么如何把内存中每个 AddressBook 对象按照列式存储格式存储下来呢?
在 Parquet 格式的存储中,一个 schema 的树结构有几个叶子节点,实际的存储中就会有多少 column。例如上面这个 schema 的数据存储实际上有四个 column,如图5 所示。

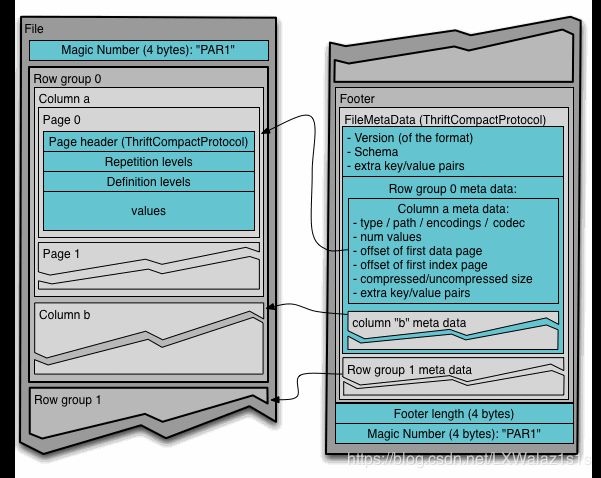
Parquet 文件在磁盘上的分布情况如图6 所示。所有的数据先按一定的行数被水平切分成 Row group,如一个1亿行的文件,每1千万行为一个 Row group,就有10个Row group,当然实际情况并不一定是平均的,我只是说明问题,模拟数据如下:
4-byte magic number “PAR1”
…
…
…
…
File Metadata
4-byte length in bytes of file metadata
4-byte magic number “PAR1”
一个 Row group包含这个 Row group 对应的区间内的所有列的 column chunk;
一个 column chunk 负责存储某一列的数据,这些数据是这一列的 Repetition levels, Definition levels 和 values(详见后文)。一个 column chunk 是由 Page组成的;
Page 是压缩和编码的单元,对数据模型来说是透明的。一个 Parquet 文件最后是 Footer,存储了文件的元数据信息和统计信息。Row group 是数据读写时候的缓存单元,所以推荐设置较大的 Row group 从而带来较大的并行度,当然也需要较大的内存空间作为代价。一般情况下推荐配置一个 Row group 大小 1G,一个 HDFS 块大小 1G,一个 HDFS 文件只含有一个块,注意这里说的是一般,不是一定哟,这个值还是要根据实际场景和你集群自身配置以及数据文件的大小来决定的,比如你要将集群内的一个parquet文件推送给某个mysql做app运用,这个时候如果你采用这个配置,及其可能造成数据倾斜,因为mysql不一定是分布式,这个时候你要是一个parquet文件只有一个块,你反而要自己reparation了;
总结:Row group > column chunk > Page ;Footer存储元数据;
拿我们的这个 schema 为例,在任何一个 Row group 内,会顺序存储四个 column chunk。这四个 column 都是 string 类型。这个时候 Parquet 就需要把内存中的 AddressBook 对象映射到四个 string 类型的 column 中。如果读取磁盘上的 4 个 column 要能够恢复出 AddressBook 对象。这就用到了我们前面提到的 “record shredding and assembly algorithm”。
Striping/Assembly算法
这里解答前面列存储简介对于嵌套数据类型列式存储Parquet的实现,我们除了存储数据的 value 之外还需要两个变量 Repetition Level(R), Definition Level(D) 才能存储其完整的信息用于序列化和反序列化嵌套数据类型。Repetition Level 和 Definition Level 可以说是为了支持嵌套类型而设计的,但是它同样适用于简单数据类型。在 Parquet 中我们只需定义和存储 schema 的叶子节点所在列的 Repetition Level 和 Definition Level。
Definition Level
嵌套数据类型的特点是有些 field 可以是空的,也就是没有定义。如果一个 field 是定义的,那么它的所有的父节点都是被定义的。从根节点开始遍历,当某一个 field 的路径上的节点开始是空的时候我们记录下当前的深度作为这个 field 的 Definition Level。如果一个 field 的 Definition Level 等于这个 field 的最大 Definition Level 就说明这个 field 是有数据的。对于 required 类型的 field 必须是有定义的,所以这个 Definition Level 是不需要的。在关系型数据中,optional 类型的 field 被编码成 0 表示空和 1 表示非空(或者反之)。
Repetition Level
记录该 field 的值是在哪一个深度上重复的。只有 repeated 类型的 field 需要 Repetition Level,optional 和 required 类型的不需要。Repetition Level = 0 表示开始一个新的 record。在关系型数据中,repetion level 总是 0。
下面用 AddressBook 的例子来说明 Striping 和 assembly 的过程,对于每个 column 的最大的 Repetion Level 和 Definition Level 如图7 所示。
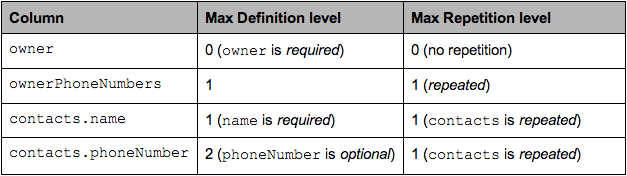
图6结果得来的思路解析
第1步:打开图4;
第2步:从根节点开始从左到右深度优先搜索遍历叶子节点
第3步:判断叶子节点的repetition类型:
第3.1步:如果为required(出现 1 次),说明该叶子节点不可能为空,除非他的父级节点为空,直接找到该叶子节点父节点所在的深度level就是这一列的Max Definition Level,如owner和contacts.name;同样的道理,required(出现 1 次),optional(出现 0 次或者 1 次),说明该叶子节点不可能重复,除非他的父级节点重复,直接找到该叶子节点父节点所在的深度level就是 这一列的Max Repetition Level;
第3.2步 如果为optional(出现 0 次或者 1 次),repeated(出现 0 次或者多次),说明该叶子节点可能出现空,如ownerPhoneNumbers和contacts.phoneNumber,那该叶子节点所在的深度就是Max Definition Level,而只有repeated(出现 0 次或者多次)类型的叶子节点才有可能出现重复,如ownerPhoneNumbers,所以这种叶子节点的深度就是这一列的 Max Repetition Level;
下面这样两条 record:
AddressBook {
owner: "Julien Le Dem",
ownerPhoneNumbers: "555 123 4567",
ownerPhoneNumbers: "555 666 1337",
contacts: {
name: "Dmitriy Ryaboy",
phoneNumber: "555 987 6543",
},
contacts: {
name: "Chris Aniszczyk"
}
}
AddressBook {
owner: "A. Nonymous"
}
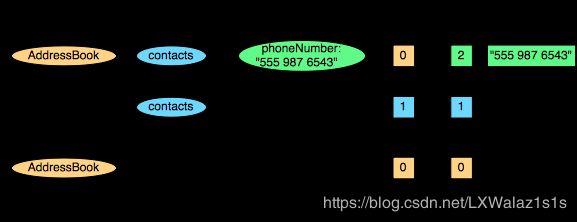
以 contacts.phoneNumber 这一列为例,"555 987 6543"这个 contacts.phoneNumber 的 Definition Level 是最大 Definition Level=2。而如果一个 contact 没有 phoneNumber,那么它的 Definition Level 就是 1。如果连 contact 都没有,那么它的 Definition Level 就是 0。
下面我们拿掉其他三个 column 只看 contacts.phoneNumber 这个 column,把上面的两条 record 简化成下面的样子:
AddressBook {
contacts: {
phoneNumber: "555 987 6543"
}
contacts: {
}
}
AddressBook {
}
这两条记录的序列化过程如图8所示:
如果我们要把这个 column 写到磁盘上,磁盘上会写入这样的数据,如图9所示:

注意:NULL 实际上不会被存储,如果一个 column value 的 Definition Level 小于该 column 最大 Definition Level 的话,那么就表示这是一个空值。
下面是从磁盘上读取数据并反序列化成 AddressBook 对象的过程:
-
读取第一个三元组 R=0, D=2: Value=”555 987 6543”,R=0 表示是一个新的 record,要根据 schema 创建一个新的 nested record 直到 Definition Level=2,D=2 说明 Definition Level=Max Definition Level,那么这个 Value 就是 contacts.phoneNumber 这一列的值,赋值操作 contacts.phoneNumber=”555 987 6543”。 -
读取第二个三元组 R=1, D=1:R=1 表示不是一个新的 record,是上一个 record 中一个新的 contacts,D=1 表示 contacts 定义了,但是 contacts 的下一个级别也就是 phoneNumber 没有被定义,所以创建一个空的 contacts。 -
读取第三个三元组 R=0, D=0:R=0 表示一个新的 record,根据 schema 创建一个新的 nested record 直到 Definition Level=0,也就是创建一个 AddressBook 根节点。
可以看出在 Parquet 列式存储中,对于一个 schema 的所有叶子节点会被当成 column 存储,而且叶子节点一定是 primitive 类型的数据。对于这样一个 primitive 类型的数据会衍生出三个 sub columns (R, D, Value),也就是从逻辑上看除了数据本身以外会存储大量的 Definition Level 和 Repetition Level。那么这些 Definition Level 和 Repetition Level 是否会带来额外的存储开销呢?实际上这部分额外的存储开销是可以忽略的。因为对于一个 schema 来说 level 都是有上限的,而且非 repeated 类型的 field 不需要 Repetition Level,required 类型的 field 不需要 Definition Level,也可以缩短这个上限。例如对于 Twitter 的 7 层嵌套的 schema 来说,只需要 3 个 bits 就可以表示这两个 Level 了。
对于存储关系型的 record,record 中的元素都是非空的(NOT NULL in SQL)。Repetion Level 和 Definition Level 都是 0,所以这两个 sub column 就完全不需要存储了。所以在存储非嵌套类型的时候,Parquet 格式也是一样高效的。
上面演示了一个 column 的写入和重构,那么在不同 column 之间是怎么跳转的呢,这里用到了有限状态机的知识,这里不多做介绍。
Parquet文件总结
以上就是Parquet文件的简单介绍,Parquet 列式存储带来的性能上的提高在业内已经得到了充分的认可,特别是当你们的表非常宽(column 非常多)的时候,Parquet 无论在资源利用率还是性能上都优势明显,Spark 已经将 Parquet 设为默认的文件存储格式,Cloudera 投入了很多工程师到 Impala+Parquet 相关开发中(目前ORC文件不支持Impala),Hive/Pig 都原生支持 Parquet。Parquet 现在为 Twitter 至少节省了 1/3 的存储空间,同时节省了大量的表扫描和反序列化的时间。这两方面直接反应就是节约成本和提高性能,而和Parquet文件关系不错的Snappy压缩方式也单独对Parquet文件做过优化,一般情况下采用Parquet文件+Snappy压缩的组合做大数据的文件存储格式,如Hive的表存储类型,如果说 HDFS 是大数据时代文件系统的事实标准的话,Parquet 就是大数据时代存储格式的事实标准。
2.ORC文件简介
ORC存储
ORC (Optimized Row Columnar)存储源自RC这种存储格式,可以认为是RC的二代,这也就是为什么现在RC没什么地位的原因,跟Parquet一样,也是列式存储,先按照行水平切割,再按列垂直切割存储。
ORC相对于Parquet独有的特性,比如支持update操作,支持ACID(关系型数据库的事务),本身支持struct,array复杂类型.你可以使用复杂类型构建一个类似parquet的嵌套式数据架构;对比缺点也跟明显,嵌套层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型,另外目前不支持impala,也是硬伤之一。
数据模型
`和Parquet不同,ORC原生是不支持嵌套数据格式的,而是通过对复杂数据类型特殊处理的方式实现嵌套格式的支持,例如对于如下的hive表:
CREATE TABLE `orcStructTable`(
`name` string,
`course` struct<course:string,score:int>,
`score` map<string,int>,
`work_locations` array<string>
)
在ORC的结构中包含了复杂类型列和原始类型,前者包括LIST、STRUCT、MAP和UNION类型,后者包括BOOLEAN、整数、浮点数、字符串类型等,其中STRUCT的孩子节点包括它的成员变量,可能有多个孩子节点,MAP有两个孩子节点,分别为key和value,LIST包含一个孩子节点,类型为该LIST的成员类型,UNION一般不怎么用得到。每一个Schema树的根节点为一个Struct类型,所有的column按照树的中序遍历顺序编号。
ORC只需要存储schema树中叶子节点的值,而中间的非叶子节点只是做一层代理,它们只需要负责孩子节点值得读取,只有真正的叶子节点才会读取数据,然后交由父节点封装成对应的数据结构返回。
而ORC的实现,更加简单直白一些,类似元素是否为Null的信息,就是一组bit位图,而对于元素个数不定的结构,如List,Map等数据结构,则在虚拟的父结构中维护了一个所拥有的子元素数量的信息。这样的带来的问题是,由单纯的某一叶节点列元素的数据出发,是无法独立构建复原出该列数据的结构层次的,需要借助父元素的辅助元数据才能完整复原,这一点设计思想,还是不如Parquet的Striping/Assembly算法的,过分的依赖于父节点的辅助元数据,就是为什么ORC相对Parquet在多层次的嵌套结构是显得更吃CPU和内存等资源的原因之一吧。
l
文件结构
ORC文件以二进制方式存储,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。ORC的文件结构如图10,其中涉及到如下的概念:
ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
文件级元数据:包括文件的描述信息PostScript、文件meta信息、所有stripe的信息和文件schema信息。
stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。

数据访问
读取ORC文件是从尾部开始的,第一次读取16KB的大小,尽可能的将Postscript和Footer数据都读入内存。文件的最后一个字节保存着PostScript的长度,它的长度不会超过256字节,PostScript中保存着整个文件的元数据信息,它包括文件的压缩格式、文件内部每一个压缩块的最大长度(每次分配内存的大小)、Footer长度,以及一些版本信息。在Postscript和Footer之间存储着整个文件的统计信息(上图中未画出),这部分的统计信息包括每一个stripe中每一列的信息,主要统计成员数、最大值、最小值、是否有空值等。
接下来读取文件的Footer信息,它包含了每一个stripe的长度和偏移量,该文件的schema信息(将schema树按照schema中的编号保存在数组中)、整个文件的统计信息以及每一个row group的行数。
处理stripe时首先从Footer中获取每一个stripe的其实位置和长度、每一个stripe的Footer数据(元数据,记录了index和data的的长度),整个striper被分为index和data两部分,stripe内部是按照row group进行分块的(每一个row group中多少条记录在文件的Footer中存储),row group内部按列存储。每一个row group由多个stream保存数据和索引信息。每一个stream的数据会根据该列的类型使用特定的压缩算法保存。在ORC中存在如下几种stream类型:
PRESENT:每一个成员值在这个stream中保持一位(bit)用于标示该值是否为NULL,通过它可以只记录部位NULL的值
DATA:该列的中属于当前stripe的成员值。
LENGTH:每一个成员的长度,这个是针对string类型的列才有的。
DICTIONARY_DATA:对string类型数据编码之后字典的内容。
SECONDARY:存储Decimal、timestamp类型的小数或者纳秒数等。
ROW_INDEX:保存stripe中每一个row group的统计信息和每一个row group起始位置信息。
在初始化阶段获取全部的元数据之后,可以通过includes数组指定需要读取的列编号,它是一个boolean数组,如果不指定则读取全部的列,还可以通过传递SearchArgument参数指定过滤条件,根据元数据首先读取每一个stripe中的index信息,然后根据index中统计信息以及SearchArgument参数确定需要读取的row group编号,再根据includes数据决定需要从这些row group中读取的列,通过这两层的过滤需要读取的数据只是整个stripe多个小段的区间,然后ORC会尽可能合并多个离散的区间尽可能的减少I/O次数。然后再根据index中保存的下一个row group的位置信息调至该stripe中第一个需要读取的row group中。
由于ORC中使用了更加精确的索引信息,使得在读取数据时可以指定从任意一行开始读取,更细粒度的统计信息使得读取ORC文件跳过整个row group,ORC默认会对任何一块数据和索引信息使用ZLIB压缩,因此ORC文件占用的存储空间相对也更小,带来的牺牲就是CPU和内存等计算资源耗损,就是以空间换时间的代价,可参考三种文件实践对比。
3.RC文件简介
RC File文件格式,因为是ORC的基石,实现的功能就比较简单,基本就是列存储的精髓实现,先水平按行切割,再垂直切按列切割,然后每个行组的Metadata里维护了行组的纪录数和每个column及每个Column纪录的长度,编码方面Metadata使用RLE编码,Column Data使用Gzip等压缩格式(取决于写入方,比如MR程序),相对简单,也因为ORC的出现,基本已经完全被取代,没什么江湖地位。
三种文件实践对比
cloudera blog测试结果

图11,对于很多人来说并不陌生,其实这样图片出自著名的cloudera blog中的一篇ORCFile in HDP 2: Better Compression, Better Performance,图片想表达的思想很简单,ORC文件天下第一,因为是cloudera blog,而且又是英文版的,以cloudera 在大数据集群的地位,这张图片也就被很多人拿出来当做吹捧ORC的圣经;
百度测试结论
之前瞟了一眼百度关于ORC和Parquet文件的测试报告,可惜拿不出来,结论可以参考下,之前百度采用了Array{Map{Map}}这样的嵌套数据做的测试,400G的ORC数据文件,吃了1000G的内存,而Parquet相对好点,结论大概是ORC压缩比高,但是吃CPU和内存,适合存储空间吃紧,计算资源强大的集群,既时间换空间;Parquet适合存储空间巨大,计算资源相对紧缺的资源,适合空间换时间,但是也提醒到,不能一概而论,如果可以,最好结合自己的数据结构做一下测试,另外如果集群有打算架Impala的想法,那么就要注意了,还是Parquet文件好,因为ORC目前不支持。
Parquet和ORC对比总结
| 性状 | Parquet | ORC |
|---|---|---|
| 现状 | Apache顶级项目 | Apache顶级项目 |
| 列式存储 | 支持 | 支持 |
| 开发语言 | Java | Java |
| 嵌套结构 | 完美支持 | 支持起来比较复杂,比较耗CPU,内存等资源 |
| ACID(事务) | 不支持 | 支持 |
| Update,Delete操作 | 不支持 | 支持 |
| 元数据 | 支持粗粒度的索引 | 支持粗粒度的索引 |
| 查询性能 | 具体要看数据文件结构分布,一般ORC略优 | 具体要看数据文件结构分布,一般ORC略优 |
| 压缩能力 | ORC略优 | ORC略优 |
| 支持的查询引擎 | 常见的大数据查询引擎都支持 | 不支持Impala |
总结:注意不要被关系型数据库所迷惑ACID(事务)和Update,Delete操作在大数据里面是很鸡肋的,不要因为这个条件来决定使用ORC合适Parquet,因为1T的数据里面有几条数据去做Update和Delete吗?没必要的,事务就跟没必要了,因为事务防止的危险如脏读等场景,一般在大数据场景下不太要求,或者采用其他的架构来避免。
个人建议的文件选取
具体还是要看自己数据文件的结构,结合测试会好一点,但是如果非要我说一种搭配,可以选取Parquet文件+Snappy压缩作为热数据的存储,相对于ORC牺牲点存储空间,而且存储空间快速填充也可以成为你集群扩容的资本,毕竟如果自己搭建集群的话,内存一般比较局限,你可以评估存储不够为理由要求运维机器,从而达到扩容集群内存的目的,谈判的艺术性,一般人我不告诉他。
而冷数据,如三年前的数据,可以采取牺牲时间换取空间的方式,采用ORC文件+Gzip压缩格式,进一步archive(归档)掉,别人申请三年前的数据,需要行政上约定提前一周时间提出申请。
常见压缩格式对比及搭配建议
Hadoop支持压缩格式,可以用指令hadoop checknative来获取自己Hadoop集群默认支持的压缩格式,注意这个hadoop是自己安装的hadoop目录下/tools/hadoop/hadoop-2.8.5/bin/hadoop指令hadoop,我做了环境变量
[liuxiaowei@shucang-01 ~]$ hadoop checknative
20/05/11 18:47:44 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
20/05/11 18:47:44 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
Native library checking:
hadoop: true /tools/hadoop/hadoop-2.8.5/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
snappy: true /lib64/libsnappy.so.1
lz4: true revision:10301
bzip2: true /lib64/libbz2.so.1
openssl: false Cannot load libcrypto.so (libcrypto.so: cannot open shared object file: No such file or directory)!
具体对比如表2:
| 压缩格式 | 可分割 | 算法 | 扩展名 | Linux工具 |
|---|---|---|---|---|
| gzip | 否 | DEFLATE | .gz | gzip |
| lzo | 是(加索引) | LZO | .lzo | lzop |
| snappy | 否 | Snappy | .snappy | 无 |
| Bzip2 | 是 | Bzip2 | .bz2 | bzip2 |
| deflate | 否 | DEFLATE | .deflate | 无 |
| zip | 是 | ZIP | .zip | zip |
基于128MB文本文件的压缩性能测试横向比较,具体如表3:
| 编码器 | 压缩时间(秒) | 解压缩时间(秒) | 压缩文件大小 | 压缩比率 |
|---|---|---|---|---|
| Deflate | 6.88 | 6.80 | 24,866,259 | 18.53% |
| gzip | 6.68 | 6.88 | 24,866,271 | 18.53% |
| bzip2 | 3,012.34 | 24.31 | 19,270,217 | 14.36% |
| lzo | 1.69 | 7.00 | 40,946,704 | 30.51% |
| lzop | 1.70 | 5.62 | 40,946,746 | 30.51% |
| Snappy | 1.31 | 6.66 | 46,108,189 | 34.45% |
-
Gzip压缩:
优点:压缩率比较高,压缩/解压速度也比较快,hadoop本身支持。
缺点:不支持分片。
应用场景:当每个文件压缩之后在1个block块大小内,可以考虑用gzip压缩格式,冷数据archive(归档)。 -
lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率,支持分片,是Hadoop中最流行的压缩格式,支持Hadoop native库。
缺点:压缩率比gzip要低一些,Hadoop本身不支持,需要安装,如果支持分片需要建立索引,还需要指定inputformat改为lzo格式。
应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越明显。 -
snappy压缩
优点:支持Hadoop native库,高速压缩速度和合理的压缩率,hadoop-2.8.5自带;
缺点:不支持分片,压缩率比gzip要低;
应用场景:当MapReduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式;Parquet文件的默认压缩方式。 -
bzip2压缩
优点:支持分片,具有很高的压缩率,比gzip压缩率都高,Hadoop本身支持,但不支持native。
缺点:压缩/解压速度慢,不支持Hadoop native库。
应用场景:适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式,输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况。
总结:压缩比:bzip2 > gzip > lzo > snappy;压缩速度:snappy > lzo> gzip > bzip2。
所有压缩算法都必须在压缩程度和压缩/解压缩速度之间进行权衡。我们必须根据我们的场景选择这些编解码器,假设我们必须对很少查询的数据进行存档,然后我们必须使用像Bzip2这样的编解码器,如果我们经常需要访问我们的数据,我们可以使用像Snappy这样的算法给我们最快的数据压缩和解压缩。
个人推荐:可以选取Parquet文件+Snappy压缩作为热数据的存储,相对于ORC牺牲点存储空间,采用ORC文件+Gzip压缩格式或者ORC文件+bzip2 压缩格式,进一步archive(归档)掉,别人申请三年前的数据,需要行政上约定提前一周时间提出申请。
参考文献
- Parquet与ORC:高性能列式存储格式
- 深入分析 Parquet 列式存储格式
- RC ORC Parquet 格式比较和性能测试
- ORCFile in HDP 2: Better Compression, Better Performance
- Hadoop_常用存储与压缩格式
- Parquet官网