Spark回炉重塑之数组操作之Array、ArrayBuffer
目录
Array
ArrayBuffer
遍历Array和ArrayBuffer
数组常见操作
使用yield和函数式编程转换数组
算法案例
移除第一个负数之后的所有负数
移除第一个负数之后的所有负数(改良版)
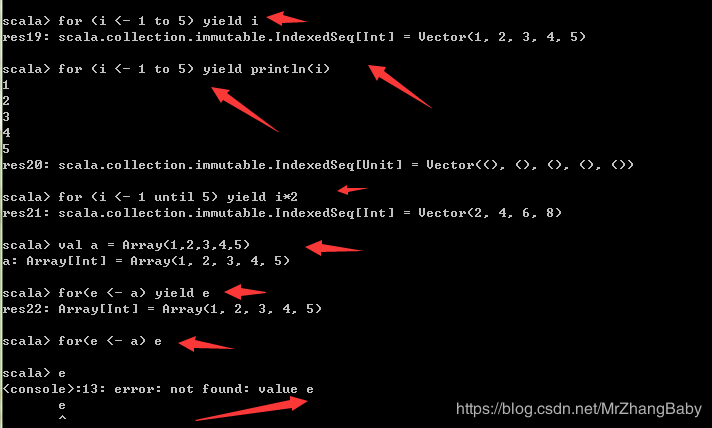
yield
Array
在Scala中,Array代表的含义与Java中类似,也是长度不可改变的数组。此外,由于Scala与Java都是运行在JVM中,双方可以互相调用,因此Scala数组的底层实际上是Java数组。例如字符串数组在底层就是Java的String[],整数数组在底层就是Java的Int[]。
// 数组初始化后,长度就固定下来了,而且元素全部根据其类型初始化
val a = new Array[Int](10)
a(0)
a(0) = 1
val a = new Array[String](10)
// 可以直接使用Array()创建数组,元素类型自动推断
val a = Array("hello", "world")
a(0) = "hi"
val a = Array("leo", 30)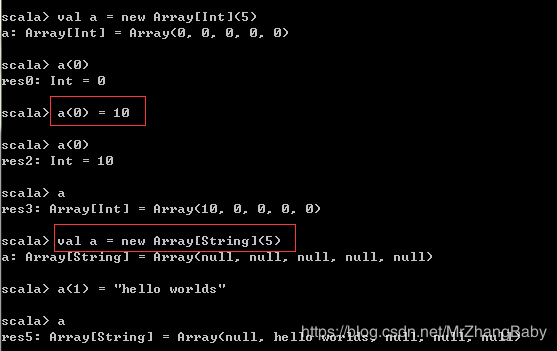
ArrayBuffer
在Scala中,如果需要类似于Java中的ArrayList这种长度可变的集合类,则可以使用ArrayBuffer。
// 如果不想每次都使用全限定名,则可以预先导入ArrayBuffer类
import scala.collection.mutable.ArrayBuffer// 使用ArrayBuffer()的方式可以创建一个空的ArrayBuffer
val b = ArrayBuffer[Int]()// 使用+=操作符,可以添加一个元素,或者多个元素
// 这个语法必须要谨记在心!因为spark源码里大量使用了这种集合操作语法!
b += 1
b += (2, 3, 4, 5)
// 使用++=操作符,可以添加其他集合中的所有元素
b ++= Array(6, 7, 8, 9, 10)
// 使用trimEnd()函数,可以从尾部截断指定个数的元素
b.trimEnd(5)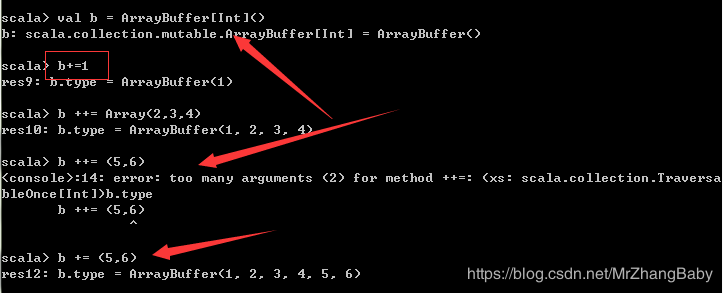
其实就是一句话:添加元素用 ”+=” ,不论一个还是多,添加集合必须用了 “++=”
// 使用insert()函数可以在指定位置插入元素
// 但是这种操作效率很低,因为需要移动指定位置后的所有元素
b.insert(5, 6)
b.insert(6, 7, 8, 9, 10)
// 使用remove()函数可以移除指定位置的元素
b.remove(1)
b.remove(1, 3)
// Array与ArrayBuffer可以互相进行转换
b.toArray
a.toBuffer遍历Array和ArrayBuffer
// 使用for循环和until遍历Array / ArrayBuffer
// 使until是RichInt提供的函数
for (i <- 0 until b.length)
println(b(i))
// 跳跃遍历Array / ArrayBuffer
for(i <- 0 until (b.length, 2))
println(b(i))
// 从尾部遍历Array / ArrayBuffer
for(i <- (0 until b.length).reverse)
println(b(i))
// 使用“增强for循环”遍历Array / ArrayBuffer
for (e <- b)
println(e)数组常见操作
- // 数组元素求和
- val a = Array(1, 2, 3, 4, 5)
- val sum = a.sum
- // 获取数组最大值
- val max = a.max
- // 对数组进行排序
- scala.util.Sorting.quickSort(a)
- // 获取数组中所有元素内容
- a.mkString
- a.mkString(", ")
- a.mkString("<", ",", ">")
- // toString函数
- a.toString
- b.toString
使用yield和函数式编程转换数组
- // 对Array进行转换,获取的还是Array
- val a = Array(1, 2, 3, 4, 5)
- val a2 = for (ele <- a) yield ele * ele
- // 对ArrayBuffer进行转换,获取的还是ArrayBuffer
- val b = ArrayBuffer[Int]()
- b += (1, 2, 3, 4, 5)
- val b2 = for (ele <- b) yield ele * ele
- // 结合if守卫,仅转换需要的元素
- val a3 = for (ele <- if ele % 2 == 0) yield ele * ele
- // 使用函数式编程转换数组(通常使用第一种方式)
- a.filter(_ % 2 == 0).map(2 * _)
- a.filter { _ % 2 == 0 } map { 2 * _ }
算法案例
移除第一个负数之后的所有负数
// 构建数组
val a = ArrayBuffer[Int]()
a += (1, 2, 3, 4, 5, -1, -3, -5, -9)
// 每发现一个第一个负数之后的负数,就进行移除,性能较差,多次移动数组
var foundFirstNegative = false
var arrayLength = a.length
var index = 0
while (index < arrayLength) {
if (a(index) >= 0) {
index += 1
} else {
if (!foundFirstNegative) { foundFirstNegative = true; index += 1 }
else { a.remove(index); arrayLength -= 1 }
}
}
移除第一个负数之后的所有负数(改良版)
// 重新构建数组
val a = ArrayBuffer[Int]()
a += (1, 2, 3, 4, 5, -1, -3, -5, -9)
// 每记录所有不需要移除的元素的索引,稍后一次性移除所有需要移除的元素
// 性能较高,数组内的元素迁移只要执行一次即可
var foundFirstNegative = false
val keepIndexes = for (i <- 0 until a.length if !foundFirstNegative || a(i) >= 0) yield {
if (a(i) < 0) foundFirstNegative = true
i
}
for (i <- 0 until keepIndexes.length) { a(i) = a(keepIndexes(i)) }
a.trimEnd(a.length - keepIndexes.length)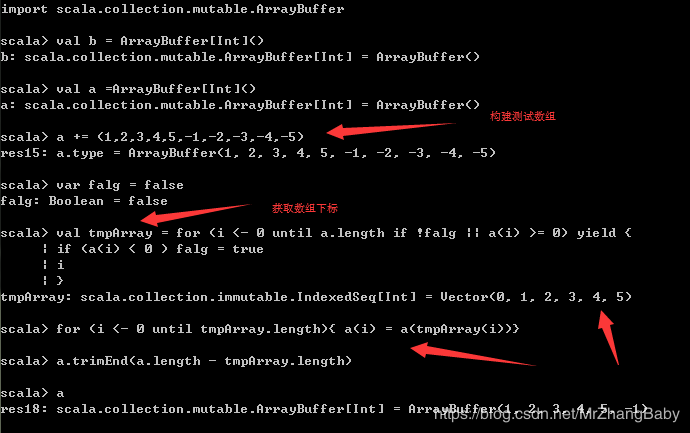
第一种算法是常规思路,讲第一个保留剩余全部删掉,频繁操作移动数组,性能较差!
第二种算法是改良版,之所以叫改良版就是讲所需要的数组值,讲下标进行存储下来,然后再通过循环进行赋值,并打印输出。
yield
- 针对每一次 for 循环的迭代, yield 会产生一个值,被循环记录下来 (内部实现上,像是一个缓冲区).
- 当循环结束后, 会返回所有 yield 的值组成的集合.
- 返回集合的类型与被遍历的集合类型是一致的.
个人觉得这个东西,你可以理解为迭代器、迭代器是啥子?看下c++就知道了,迭代器,然后如果后面跟变量就返回变量的迭代器,如果后面跟输出语句或者无返回值的,那么就返回空迭代器,并进行打印输出。