matlab距离判别分析的应用
matlab距离判别分析的应用
一、定义
距离判别法:距离判别分析方法是判别样品所属类别的一应用性很强的多因素决方法,其中包括两个样本总体距离判别法,多个样本距离判别法。
多个总体距离判别法:多个总体距离判别法是距离判别法的一种,是两个总体距离判别法的推广,具有多个总体,将待测样本归为多个样本中的一类。
1.1两个总体的距离判别法
设有两个总体(或称两类)G1、G2,从第一个总体中抽取n1个样品,从第二个总体中抽取n2个样品,每个样品测量p个指标如下页表。
今任取一个样品,实测指标值为,问X应判归为哪一类?


如果距离定义采用欧氏距离,则可计算出
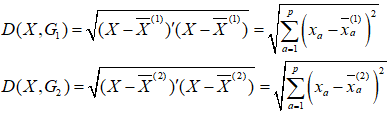
然后比较和大小,按距离最近准则判别归类。
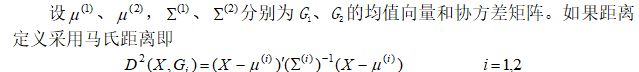
1.2
![]()


二、多个总体的距离判别法
设有k个总体G1, …, Gk,它们的均值和协方差阵分别为,从每个总体Gi中抽取ni个样品,i =1,…,k,每个样品测p个指标。今任取一个样品,实测指标值为,问X应判归为哪一类?


三、实际问题
3.1城市分类
例 对全国30个省市自治区1994年影响各地区经济增长差异的制度变量:x1—经济增长率(%)、x2—非国有化水平(%)、x3—开放度(%)、x4—市场化程度(%)作判别分析。

我们首先判断两组协方差是否相等,相等用一种算法,不相等用另外一种算法。
a=xlsread('keshe','sheet1','D2:G12');%第一类
b=xlsread('keshe','Sheet1','D13:G28');%第二类
x=xlsread('keshe','Sheet1','D29:G31');%待测数据
n1=length(a(:,1));n2=length(b(:,1)); %样本容量
n=n1+n2;s1=cov(a);s2=cov(b); %样本协方差
p=3;s=((n1-1)*s1+(n2-1)*s2)/(n1+n2-2);
q1=(n1-1)*(log(det(s))-log(det(s1))-p+trace(inv(s)*s1));
q2=(n2-1)*(log(det(s))-log(det(s2))-p+trace(inv(s)*s2));%检验统计量
if (q1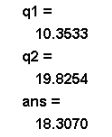
chi2inv(0.95,10)=18.3070,q1< 18.3070 q2>18.3070
所以协方差不相等
然后通过协方差不相同来调用函数进行判别:
q2=(n2-1)*(log(det(s))-log(det(s2))-p+trace(inv(s)*s2)); %检验统计量
chi2inv(0.95,10); %验证两总体的协方差矩阵相同
W=mahal(x,a)-mahal(x,b) %协方差不相等时,计算二次判别函数

得到以上结果,x1小于0,x2大于0。再根据判别准则可得 x1,属于第一类,x2,x3属于第二类,即待判样品中江苏被判属第一组,陕西和安徽被判属第二组
第二种方法 用classify进行判别,此时协方差不相同,选用二次判别函数。
n1=size(a,1);n2=size(b,1);
group=[ones(n1,1);2*ones(n2,1)];
training=[a;b];
[class2,err,POSTERIOR,logp,coeff]=classify(x,training,group,'mahalanobis');
class2

得到以上结果,x1小于0,x2大于0。再根据判别准则可得 x1,属于第一类,x2,x3属于第二类,即待判样品中江苏被判属第一组,陕西和安徽被判属第二组
对于判别结果的分析
%回代误判率
a=xlsread('keshe','sheet1','D2:G12');%第一类
b=xlsread('keshe','Sheet1','D13:G28');%第二类
x=xlsread('keshe','Sheet1','D29:G31');%待测数据
for i=1:n1
d11(i)=(a(i,:)-mean(a))*inv(s)*(a(i,:)-mean(a))'-(a(i,:)-mean(b))*inv(s)*(a(i,:)-mean(b))';end
for i=1:n2
d22(i)=(b(i,:)-mean(b))*inv(s)*(b(i,:)-mean(b))'-(b(i,:)-mean(a))*inv(s)*(b(i,:)-mean(a))';end
n12=length(find(d11>0));n21=length(find(d22>0));p0=(n12+n21)/(n1+n2)
%计算交叉误判率
for i=1:n1
A=a([1:i-1,i+1:n1],:);
n1=length(A(:,1));n2=length(b(:,1));
s1=cov(a);s2=cov(b);P=3;
s=((n1-1)*s1+(n2-1)*s2)/(n1+n2-2);
D11(i)=(a(i,:)-mean(A))*inv(s)*(a(i,:)-mean(A))'-(a(i,:)-mean(b))*inv(s)*(a(i,:)-mean(b))';end
for i=1:n2 B=b([1:i-1,i+1:n2],:);
n1=length(a(:,1));n2=length(B(:,1));
s1=cov(A);s2=cov(B);P=3;
s=((n1-1)*s1+(n2-1)*s2)/(n1+n2-2);
D22(i)=(b(i,:)-mean(B))*inv(s)*(b(i,:)-mean(B))'-(b(i,:)-mean(a))*inv(s)*(b(i,:)-mean(a))';
end
N11=length(find(D11>0));
N22=length(find(D22>0));
p1=(N11+N22)/(n1+n2)
两个总体协方差相等判别
n1=length(a(:,1));n2=length(b(:,1));s1=cov(a);s2=cov(b);
p=3;s=((n1-1)*s1+(n2-1)*s2)/(n1+n2-2);q1=(n1-1)*(log(det(s))-log(det(s1))-p+trace(inv(s)*s1)) q2=(n2-1)*(log(det(s))-log(det(s2))-p+trace(inv(s)*s2))
chi2inv(0.95,3) %根据q1 q2与临界值的大小关系判断协方差是否相等

回归误判率是0.0370,交叉误判率是0.07690,两个误判率都比较小,因此可见这个判别是有效的
那么再来一题多个总体的吧。
3.2医疗应用
为了研究某地区人口死亡状况,已按某种方法将15个已知样品分为三类(如下表所示),指标及原始数据见下表,试建立判别函数并判定另外4个待判样品分别属于哪类。

(1)判别协方差是否相等
判别多个样本协方差是否相等
a=xlsread('ks','sheet1','B1:G5');%第一组
b=xlsread('ks','sheet1','B6:G10');%第二组
c=xlsread('ks','sheet1','B11:G15');%第三组
x=xlsread('ks','sheet1','B16:G19');%待测样本
n=size(a,1)+ size(b,1)+ size(c,1); %计算总的样本容量
[n1,p]= size(a);
k=3;
f=p*(p+1)*(k-1)/2; %统计量自由度
d=(2*p^2+3*p-1)*(k+1)/(6*(p+1)*(n-k)); %由(2.2.18)式计算
s1=cov(a); %协方差矩阵
s2=cov(b); %协方差矩阵
s3=cov(c); %协方差矩阵
s=(n1-1)*(s1+s2+s3)/(n-k); %总体协方差估计
M=(n-k)*log(det(s))-19*(log(det(s1))+log(det(s2))+log(det(s3))); %(2.2.17)中的M值
T=(1-d)*M; % 统计量(2.2.17)
P0=1-chi2cdf(T,f); % 卡方分布概率
if P0>0.1
disp('协方差相同');
else
disp('协方差不相同');
end
结果是不相等蛤
(2)调用classify判别

所以第一三个样本是属于第二类,第二四个样本属于第一类误差为0.1333%,这个误差很小,说明该判定是有效的。
调用classify进行判别多个总体
x=xlsread('ks_2','sheet1','C17:H20');%待测样本
group=[ones(n1,1);2*ones(n2,1);3*ones(n3,1)];
training=[a;b;c];
[class2,err2,POSTERIOR2,logp2,coeff2]=classify(x,training,group,'diagquadratic');
class2