PySpark---SparkSQL中的DataFrame(四)
1.replace(to_replace, value=_NoValue, subset=None)
"""Returns a new :class:`DataFrame` replacing a value with another value.
:func:`DataFrame.replace` and :func:`DataFrameNaFunctions.replace` are
aliases of each other.
Values to_replace and value must have the same type and can only be numerics, booleans,
or strings. Value can have None. When replacing, the new value will be cast
to the type of the existing column.
For numeric replacements all values to be replaced should have unique
floating point representation. In case of conflicts (for example with `{42: -1, 42.0: 1}`)
and arbitrary replacement will be used.
:param to_replace: bool, int, long, float, string, list or dict.
Value to be replaced.
If the value is a dict, then `value` is ignored or can be omitted, and `to_replace`
must be a mapping between a value and a replacement.
:param value: bool, int, long, float, string, list or None.
The replacement value must be a bool, int, long, float, string or None. If `value` is a
list, `value` should be of the same length and type as `to_replace`.
If `value` is a scalar and `to_replace` is a sequence, then `value` is
used as a replacement for each item in `to_replace`.
:param subset: optional list of column names to consider.
Columns specified in subset that do not have matching data type are ignored.
For example, if `value` is a string, and subset contains a non-string column,
then the non-string column is simply ignored."""
这个方法通过第一个参数指定要 被替换掉的老的值,第二个参数指定新的值,subset关键字参数指定子集,默认是在整个 DataFrame上进行替换。
注意上面在替换的过程中to_replace和value的类型必须要相同,而且to_replace数据类型只 能是:bool, int, long, float, string, list or dict。value数据类型只能是: bool, int, long, float, string, list or None
df.show()
df.replace([r'\N', ' ', '\t',"''"], None).show()
df.replace([r'\N', ' ', '\t',"''"],None,["name","age"]).show()

还可以针对某列中的值进行对应替换,如下:将Genre列的Female替换成F,将Male替换成M

2.sample(withReplacement=None, fraction=None, seed=None)
"""Returns a sampled subset of this :class:`DataFrame`.
:param withReplacement: Sample with replacement or not (default False).
:param fraction: Fraction of rows to generate, range [0.0, 1.0].
:param seed: Seed for sampling (default a random seed).
.. note:: This is not guaranteed to provide exactly the fraction specified of the total
count of the given :class:`DataFrame`.
.. note:: `fraction` is required and, `withReplacement` and `seed` are optional"""
用于从DataFrame中进行采样的方法,withReplacement关键字参数用于指定是否采用有放回的采样,true为有放回采用,false为无放回的采样,fraction指定采样的比例,seed采样种子,相同的种子对应的采样总是相同的,用于场景的复现。
df.sample(withReplacement=True, fraction=0.6, seed=3)3.sampleBy(col, fractions, seed=None)
"""
Returns a stratified sample without replacement based on the
fraction given on each stratum.
:param col: column that defines strata
:param fractions:
sampling fraction for each stratum. If a stratum is not
specified, we treat its fraction as zero.
:param seed: random seed
:return: a new DataFrame that represents the stratified sample"""
按照指定的col列根据fractions指定的比例进行分层抽样,seed是随机种子,用于场景的复现
df.sampleBy('Genre',{'Male':0.1,'Female':0.15}).groupBy('Genre').count().show()注意:fractions 这里是一个dict
4.schema
Returns the schema of this :class:`DataFrame` as a :class:`pyspark.sql.types.StructType
返回DataFrame的schema信息。它是 pyspark.sql.types.StructType类型。注意:@property
print(df.schema)
# 结果如下:
StructType(List(StructField(id,StringType,true),StructField(name,StringType,true),StructField(age,StringType,true),StructField(grade1,StringType,true),StructField(grade2,StringType,true),StructField(grade3,StringType,true)))
5.select(*cols)
"""Projects a set of expressions and returns a new :class:`DataFrame`.
:param cols: list of column names (string) or expressions (:class:`Column`).
If one of the column names is '*', that column is expanded to include all columns
in the current DataFrame."""
通过表达式选取DataFrame中符合条件的数据,返回新的DataFrame
df.select("id",df["name"],df["grade1"],(df["grade1"]+10).alias("科目1加10分")).show()
这里可以发现,null运算还是null
6.selectExpr(*expr)
"""Projects a set of SQL expressions and returns a new :class:`DataFrame`. This is a variant of :func:`select` that accepts SQL expressions."""
这个方法是select方法的一个变体,他可以接收一个SQL表达式, 返回新的DataFrame
df.selectExpr("id","name","grade1 * 2 as 2grade1","abs(grade2) as absg2").show()
7.show(n=20, truncate=True, vertical=False)
这个方法默认返回DataFrame的前20行记 录,可以通过truncate指定超过20个字符的记录将会被截断,vertical指定是否垂直显示。这个方法用的大家很熟悉了,这里就不赘述了.
8..stat
"""Returns a :class:`DataFrameStatFunctions` for statistic functions."""
@property
返回DataFrameStatFunctions对象,这个对象中提供了一些统计的方法,这 个对象后面会详细讲解。
9.storageLevel
"""Get the :class:`DataFrame`'s current storage level."""
@property
返回DataFrame的缓存级别
print(df.storageLevel)
df.cache()
print(df.storageLevel)
10.subtract(other)
""" Return a new :class:`DataFrame` containing rows in this frame but not in another frame. This is equivalent to `EXCEPT DISTINCT` in SQL."""
这个方法用来获取在A集合里而不再B集合里的数据,返回新的DataFrame
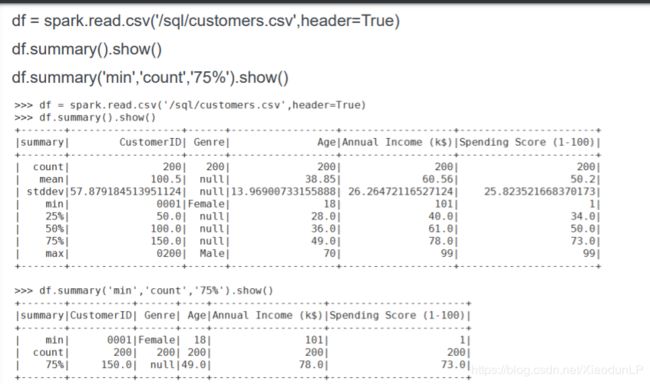
11.summary(*statistics)
用传入的统计方法返回概要信息。不传参数会默认计算count, mean, stddev, min, approximate quartiles (percentiles at 25%, 50%, and 75%), and max, *statistics参数可以是: count mean stddev min max arbitrary approximate percentiles
12.take(num)
返回DataFrame的前num个Row数据组成的列表,注意num不要太大,容易造成driver节点的OOM
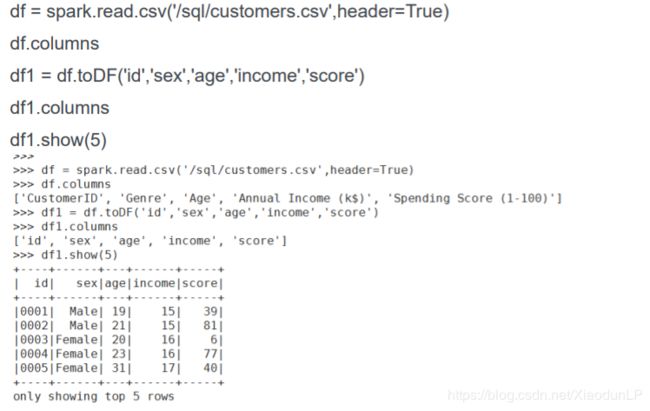
13.toDF(*cols)
返回新的带有指定cols名字的DataFrame对象
14.toJSON(use_unicode=True)
将DataFrame中的Row对象转换为json字符串,默认使用 unicode编码。toJSON方法返回的是RDD对象,而不是DataFrame对象。
print(df.toJSON().collect())
#返回结果
['{"id":"1","name":"\\\\N","age":"\'\'","grade1":" ","grade2":"\\t","grade3":"90"}', '{"id":"2","name":"ls","age":"20","grade2":"80","grade3":"50"}', '{"id":"3","name":"ww","grade1":"40","grade2":"70","grade3":"99"}', '{"id":"10","name":"ok","age":"99","grade1":"11","grade2":"22","grade3":"33"}', '{"id":"11","name":"hh","age":"64","grade1":"111","grade2":"12","grade3":"23"}', '{"id":"6","name":"ll","age":"34","grade1":"12","grade2":"34","grade3":"67"}']
15.toLocalIterator()
将DataFrame中所有数据返回为本地的可迭代的数据,数据量大了容易OOM
res = df.toLocalIterator()
for data in res:
print(data)
16.toPandas()
将Spark中的DataFrame对象转换为pandas中的DataFrame对象。
res = df.toPandas()
print(res.head(10))
print(type(res))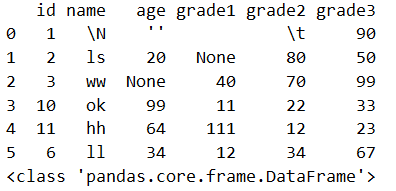
17.union(other) 和 unionByName(other)
前者返回两个DataFrame的合集。
后者根据名字来找出两个DataFrame的合集,与字段的顺序没关系,只要字段名称能对应上即可。
df.show()
df1.show()
df.union(df1).show()
df.unionByName(df1).show()

注意比对结果,就能看出这两个方法的差异....后者较前者更好一点,相对更安全
18.unpersist(blocking=False)
这个方法用于将DataFrame上持久化的数据全部清除掉
19.where(condition)
这个方法和filter方法类似。更具传入的条件作出选择。

df.where("grade1>10").show()
df.where(df["grade1"] > 10).show()
df.where("grade1 > 10 and grade2 > 30").show()
df.where((df["grade1"] > 10) & (df["grade2"] > 30)).show()
20.withColumn(colName, col)
返回一个新的DataFrame,这个DataFrame中新增加 colName的列,或者原来本身就有colName的列,则替换掉。
这个方法在做数据处理的时候经常用到...
""" Returns a new :class:`DataFrame` by adding a column or replacing the existing column that has the same name. The column expression must be an expression over this DataFrame; attempting to add a column from some other dataframe will raise an error. :param colName: string, name of the new column. :param col: a :class:`Column` expression for the new column."""
df.withColumn("grade_total",df.grade1+df.grade2+df["grade3"]).show()
和它名字类似,但是功能仅用来改名的一个方法:
withColumnRenamed(existing, new)
对已经存在的列名重命名为new,若名称不存在 则这个操作不做任何事情。
21.write
""" Interface for saving the content of the non-streaming :class:`DataFrame` out into external storage. :return: :class:`DataFrameWriter` """
@property
借助这个接口将DataFrame的内容保存到外部的系统..类似read方法一样.该方法返回一个DataFrameWriter类的对象
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_df', '_jwrite', '_set_opts', '_spark', '_sq', 'bucketBy', 'csv', 'format', 'insertInto', 'jdbc', 'json', 'mode', 'option', 'options', 'orc', 'parquet', 'partitionBy', 'save', 'saveAsTable', 'sortBy', 'text']
该类里面包含如上方法,在我们将数据落地时,可以选择相应的格式.