大数据阿里云工具之DataWorks(一)
本文主要介绍dataworks的数据集成、数据质量、数据地图与数据开发
一、简介
DataWorks(数据工场,原大数据开发套件)是阿里云重要的PaaS平台产品,提供数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,一站式开发管理的界面,帮助企业专注于数据价值的挖掘和探索。DataWorks支持多种计算和存储引擎服务,包括离线计算MaxCompute、开源大数据引擎E-MapReduce、实时计算(基于Flink)、机器学习PAI、图计算服务Graph Compute和交互式分析服务等,并且支持用户自定义接入计算和存储服务。DataWorks为您提供全链路智能大数据及AI开发和治理服务。(引用阿里DataWorks文档)
二、作用
可以使用DataWorks,对数据进行传输、转换和集成等操作,从不同的数据存储引入数据,并进行转化和开发,最后将处理好的数据同步至其它数据系统。(引用阿里DataWorks文档)
三、数据集成
1.创建工作空间
此步骤的前置条件是必须购买了DataWorks的服务,进入到DataWorks的控制台,点击创建工作空间
购买服务链接:https://common-buy.aliyun.com/?spm=a2c0j.8205274.1252641.124455.21da154drWipQc&commodityCode=dide_pre#/buy

其他的都是项目名、显示名什么的,最主要的是模式的选择,工作空间氛围两种模式,一种是单环境模式,一种是双环境模式,我们使用的是双环境模式,如果选择双环境模式,项目名后缀_dev是开发环境,如果想要查询其他环境的表数据时,得加上项目空间名+表才可以查询到。

2.数据集成
数据集成分为两种模式,一种是向导模式,一种是脚本模式,目前数据集成只适合离线数据同步,据说阿里云三月份会上线支持实时数据同步,向导模式就是按照阿里云的提示一步一步的操作,相当于是傻瓜式的操作,脚本模式,是根据自己编写导入导出的脚本,如果使用过datax的同学,这个脚本模式其实跟datax差不多。无论是想到模式还是脚本模式都需要前置设置数据源。
数据源设置,在数据集成模块里面有个数据源管理的选项,进行数据源配置

配置好数据源后点击新建同步任务
向导模式,在数据源为MySql的时候,支持过滤语句,可以根据过滤语句进行筛选出新增数据,ODPS为DataWorks的数据源,默认库odps_first
同步任务支持的数据源可查看官方文档:https://help.aliyun.com/document_detail/137670.html?spm=a2c4g.11186623.2.7.7bbc4c07xGyZXa#concept-uzy-hgv-42b

脚本模式,其实里面书写的是json,但是要注意的是,是用脚本模式的话,有些过滤字段是不支持的,具体不支持的条件请看相应的配置文档(这里踩过坑)
PS;重点,向导模式转为脚本模式不可逆,慎重!慎重!!慎重!!!

四、数据质量
数据质量这块,个人感觉更适合一些非结构化数据或者一些敏感数据对某一项的值要求比较严格,这边主要是对列变化的值做的一个报警规则配置。点击数据质量里面的创建规则按钮。
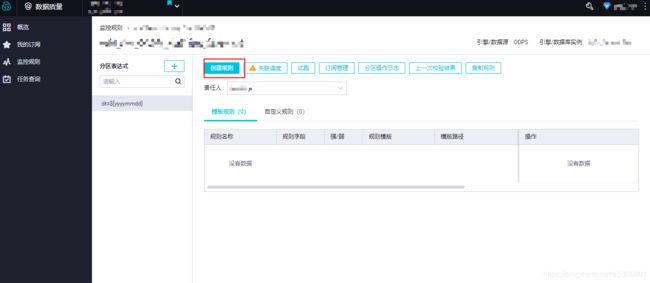

在规则里面我们可以按照自己的业务去进行设定,当一定量的数据超过某个值,或者当天的数据量超过某个值,或某个列的值不可能为负,结果为负的一些报警规则设置,通过这些设定去分析我们这批数据在生产的时候的一个质量情况,也可以帮助我们再业务上规避很多风险。
五、数据地图
数据地图顾名思义就是你可以在这里看到所有空间创建的表的信息,并可以在这里去删除生产环境的表,也可以监控到表每天的一个数据变化,目前数据地图的更新周期为天,阿里是一天对数据地图的数据进行更新(更新不是实时的)
数据地图概况,可以查看到有多少个项目,多少张表,数据存储量,以及需要消耗的计算资源等

在全部数据里可以搜索你想找到的表

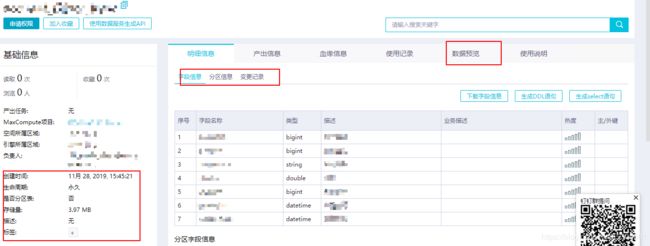
点击表名,可以去查看标的详细信息,可以查看到这张表的创建时间、存储量、分区变更以及预览表数据等等
六、数据开发
数据开发才是DataWorks里面的重中之重,数据开发又分为离线开发和实时开发,分别对应着两个计算引擎,(MC和实时计算)
只有有实时计算引擎的才能开发实时任务(目前我们还没开通实时开发),主要给大家介绍一下离线开发
1.创建业务流程

创建好业务流程后,我在业务流程里面可以看到,业务流程里面可以使用的节点信息,包括我们前面提到的数据集成,MC计算引擎提供的数据计算节点,通过MC提供的节点我们对同步过来的数据进行ETL,并把最后统计好的数据在使用数据集成,同步到业务数据库中。

这里看大家数据工具的程度,如果以前写过MR或者Spark,那么直接使用SQL就可以了,如果使用MR或者Spark比较熟的话,可以写代码,我们这里主要使用的还是isql,有点像MySql,但是又不完全是
ps:在阿里云的这个MC计算评台,每一步操作查询都是要花钱的(按量付费)(包月的不用)

我们写完我们的sql后,按照流程串起来
串起来后,我们就可以进行测试了,根据自己的测试结果进行修改或者调整j。
七、总结
阿里云服务是一整套的大数据框架体系,让我们开发人员操作的很方便,中间也出现过其他问题,但是在阿里的帮助下,都是追不解决,不能说完全解决,因为我们使用的还是公用的,不是给我们公司自己搭建的计算服务,说一下,使用过程中遇到的问题,第一就是费钱,我们使用的是按量付费,每一次开发的查询sql都需要花钱。第二就是阿里的文档个别解释不准确或是书写有问题,这些都是在工作中遇到的也跟阿里的开发人员反应过来,建议如果你们公司使用产品服务,一定要加阿里云的钉钉群,减少你们的摸索时间,因为你在开发中遇到问题,提交工单的话,一个工单可能你得等一个多小时才能有回复,中间的时间就完全浪费掉了,但是在钉钉群里,大家如果遇到类似的问题都会回答你的,钉钉群也有阿里的专职技术人员。
这一节就给大家分享这么多吧,DataWorks还包含着其他的东西,例如运维中心、数据服务等等,到下一节再给大家继续分享,如果文中有什么描述有歧义的,欢迎批评指正。
谢谢浏览~~