用Word2vec训练中文wiki,构造词向量并做词聚类
第一次写博客,以前都是转载其他网友的,自己试着写一个,虽然只是实现别人的实验,但是为了学习,便于以后复习,所以写下自己实验记录而已,希望不喜勿喷啊!
直接进入主题了,了解word2vec的话,网上的资料有很多。
首先需要下载官网上的word2vechttp://word2vec.googlecode.com/svn/trunk/
以下两小段来自@Esatmoun thttp://blog.csdn.net/eastmount/article/details/50700528(他的博客非常认真)
运行 make 编译word2vec工具:
Makefile的编译代码在makefile.txt文件中,先改名makefile.txt 为Makefile,然后在当前目录下执行make进行编译,生成可执行文件(编译过程中报出很出Warning,gcc不支持pthread多线程命令,注释即可)。
再运行示例脚本:./demo-word.sh 和 ./demo-phrases.sh:
a). 从http://mattmahoney.net/dc/text8.zip 在线下载了一个文件text8 ( 一个解压后不到100M的txt文件,可自己下载并解压放到同级目录下),可替换为自己的语料
b). 执行word2vec生成词向量到 vectors.bin文件中
c). 如果执行 sh demo-word.sh 训练生成vectors.bin文件后,下次可以直接调用已经训练好的词向量,如命令 ./distance vectors.bin
以上两段内容很容易实现,我在自己虚拟机Ubuntu上实验了一下,里面的text8都是英文语料,由于我要做中文的,所以继续去找语料了,这个语料可以自己爬取,爬取和自己研究领域相关的语料,或者直接用其他人的(如果好心人分享的话),我在网上找了wiki中文语料,是已经处理好的,纯度较高(也就是里面的繁体字都转换了,不过也可以自己进行处理,可以参考http://licstar.net/archives/262)
下面对中文wiki语料进行分词,我自己用的是jieba分词,写了个非常简单的小程序,代码很水的,你想象不到的水。
import jieba
f1 = open(r"E:\word2vec for clustering\wiki_cn\wiki_cn.txt", 'r')
#s=f1.read()
f2 = open(r"E:\word2vec for clustering\test_result.txt", 'w')
'''seglist=jieba.cut(s,cut_all=False)
output=' '.join(seglist).encode('utf-8')'''
for line in f1:
seglist=jieba.cut(line,cut_all=False)
output=' '.join(seglist).encode("utf-8")
f2.write(output)
f2.close()
f1.close()由于程序过于简单,完全没有考虑性能问题,纯属为了分词而写,分词过后,把生成的文件放到ubuntu系统的word2vec文件夹下,命名为key_train2.txt。
下面开始训练了,把word2vec文件夹下的demo-word.sh打开,修改,因为这是一个demo,之前是用来训练text8这个语料的,所以我们要把中间操作text8的代码注释掉。

这样修改后,待会运行 sh demo-word.sh时,就直接训练的是你自己的语料了,并直接生成词向量了。
实验进行到这,已经生成了vectors.bin文件了,并且运行了 ./distance vectors.bin了,此时运行结果如下图所示

会提示你输入词或句子,我输了哈佛大学,结果如上图啊。
下面用同样的方法做聚类,也是直接利用word2vec中的文件,demo-classes.sh这个文件,同样修改里面的代码,
修改训练文件为key_train2.txt,生成文件wiki_classes.txt,下面那行代码意思是把wiki_classes.txt按照聚类顺序排序生成wiki_classes.sorted.txt文件。
所以下面只要运行 sh demo-classes.sh就行了,如图所示
下面我们打开生成的文件看一看,见下图。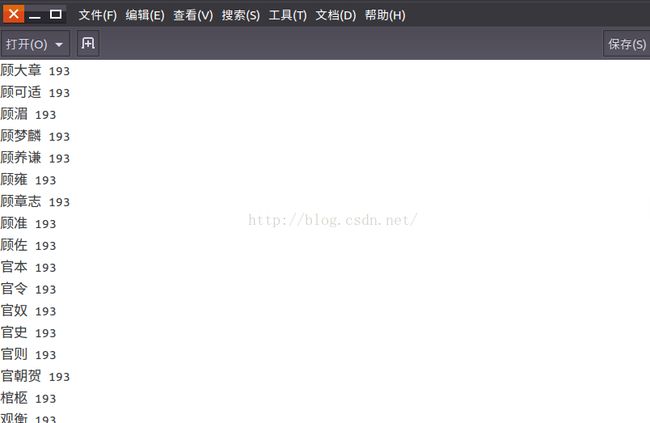
这是第194个cluster,看上去还是有那么个样子的。
好吧,实验结束了,记录就这么多了,与这篇相似的文章非常多,我只是为了记录一下。
另外,一定要训练语料大一些,不然训练不了,可能和word2vec的原理有关,语料规模太小,效果非常不好,甚至没有效果,就是出不来结果。
附上参考资料:http://blog.csdn.net/eastmount/article/details/50637476
2016.9.25@zixiaozhang