MS COCO:指标问题(续集) MAP,MAR: 以项目:mmdetection(v1.0rc0)为例-coco拆分合并
MS COCO:指标问题 MAP,MAR: 以项目:mmdetection为例
https://blog.csdn.net/baidu_40840693/article/details/102852404
上次只关注了怎么计算mAP,mAR,但是一些可视化的显示没有关注,输出的数据不够直观
Python 为目标检测任务绘制 ROC 和 PR 曲线
https://github.com/Xingyb14/curves_for_object_detection
https://blog.csdn.net/Xingyb14/article/details/81434087
如何画PR curve (PR曲线)基于COCO格式数据集 在maskrcnn_benchmark中
https://zhuanlan.zhihu.com/p/60707912
浅析经典目标检测评价指标--mmAP(一)
https://zhuanlan.zhihu.com/p/55575423
浅析经典目标检测评价指标--mmAP(二)
https://zhuanlan.zhihu.com/p/56899189
深度学习-目标检测评估指标P-R曲线、AP、mAP
https://blog.csdn.net/qq_41994006/article/details/81051150
AUC,ROC我看到的最透彻的讲解
https://blog.csdn.net/u013385925/article/details/80385873
二战周志华《机器学习》-PR曲线和ROC曲线
https://www.jianshu.com/p/75a163a17fb5
计算精度以及roc曲线
https://blog.csdn.net/qq_16949707/article/details/72770809
做机器学习,再别把IoU,ROI 和 ROC,AUC 搞混了 !聊聊目标检测,医疗领域的那些评价函数
http://nooverfit.com/wp/%E5%81%9A%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%EF%BC%8C%E5%86%8D%E5%88%AB%E6%8A%8Aiou%EF%BC%8Croi-%E5%92%8C-roc%EF%BC%8Cauc-%E6%90%9E%E6%B7%B7%E4%BA%86-%EF%BC%81%E8%81%8A%E8%81%8A%E7%9B%AE%E6%A0%87/
转:目标检测的评估指标 P-R曲线、AP、mAP、IoU、ROC曲线
https://blog.csdn.net/weixin_39790264/article/details/96139504
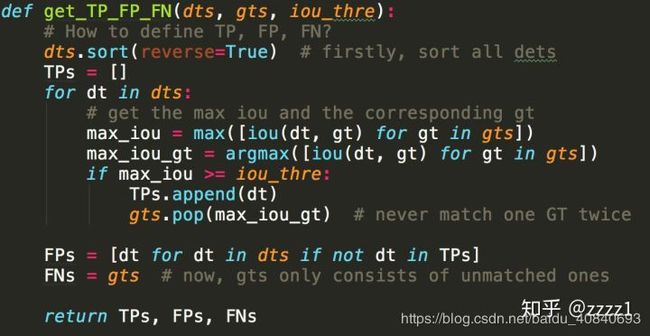
现在我们来看看,给定了一个IOU阈值、并给定了一个类别,如何具体地计算检测的性能。首先,我们要先对所有的检测结果排序,得分越高的排序越靠前,然后依次判断检测是否成功。将排序后的所有结果定义为DTs,所有同类别的真实目标定义为GTs。先依序遍历一遍DTs中的所有DT,每个DT和全部GT都计算一个IOU,如果最大的IOU超过了给定的阈值,那么视为检测成功,算作TP(True Positive),并且最大IOU对应的GT被视为匹配成功;如果该DT与所有GT的IOU都没超过阈值,自然就是FP(False Positive);同时,每当一个GT被检测成功后,都会从GTs中“被取走”,以免后续的检测结果重复匹配。因此如果有多个检测结果都与同一个GT匹配,那么分数最高的那个会被算为TP,其余均为FP。遍历完成后,我们就知道了所有DTs中,哪些是TP,哪些是FP,而由于被匹配过的GT都会“被取走”,因此GTs中剩下的就是没有被匹配上的FN(False Negative)。以下是为了方便理解的代码(Python),这段代码仅用于理解,效率较低。真实代码请参考MS COCO的官方源码。
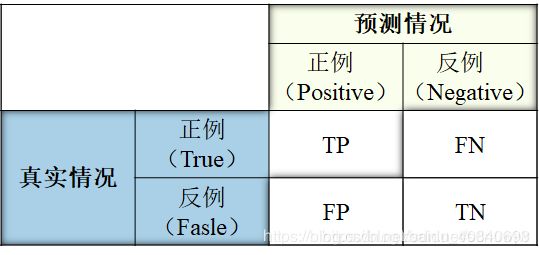
有了TP、FP、FN的定义,就可以方便地得出准确率(Precison,P,即所有的检测结果中多少是对的)和召回率(Recall,R,即所有的真实目标中有多少被检测出来了),两者的定义分别为:P = TP / (TP + FP), R = TP / (TP + FN) = TP / len(GTs)。

对比一下deeplabv3语义分割的:


回到mmdetection:

mmdetection/mmdet/core/evaluation/coco_utils.py:
def coco_eval(result_files, result_types, coco, max_dets=(100, 300, 1000)):
for res_type in result_types:
assert res_type in [
'proposal', 'proposal_fast', 'bbox', 'segm', 'keypoints'
]
if mmcv.is_str(coco):
coco = COCO(coco)
assert isinstance(coco, COCO)
if result_types == ['proposal_fast']:
ar = fast_eval_recall(result_files, coco, np.array(max_dets))
for i, num in enumerate(max_dets):
print('AR@{}\t= {:.4f}'.format(num, ar[i]))
return
for res_type in result_types:
result_file = result_files[res_type]
assert result_file.endswith('.json')
coco_dets = coco.loadRes(result_file)
img_ids = coco.getImgIds()
iou_type = 'bbox' if res_type == 'proposal' else res_type
cocoEval = COCOeval(coco, coco_dets, iou_type)
cocoEval.params.imgIds = img_ids
if res_type == 'proposal':
cocoEval.params.useCats = 0
cocoEval.params.maxDets = list(max_dets)
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()lib/python3.6/site-packages/pycocotools/cocoeval.py
def accumulate(self, p = None):
'''
Accumulate per image evaluation results and store the result in self.eval
:param p: input params for evaluation
:return: None
'''
print('Accumulating evaluation results...')
tic = time.time()
if not self.evalImgs:
print('Please run evaluate() first')
# allows input customized parameters
if p is None:
p = self.params
p.catIds = p.catIds if p.useCats == 1 else [-1]
T = len(p.iouThrs)
R = len(p.recThrs)
K = len(p.catIds) if p.useCats else 1
A = len(p.areaRng)
M = len(p.maxDets)
precision = -np.ones((T,R,K,A,M)) # -1 for the precision of absent categories
recall = -np.ones((T,K,A,M))
scores = -np.ones((T,R,K,A,M))
# create dictionary for future indexing
_pe = self._paramsEval
catIds = _pe.catIds if _pe.useCats else [-1]
setK = set(catIds)
setA = set(map(tuple, _pe.areaRng))
setM = set(_pe.maxDets)
setI = set(_pe.imgIds)
# get inds to evaluate
k_list = [n for n, k in enumerate(p.catIds) if k in setK]
m_list = [m for n, m in enumerate(p.maxDets) if m in setM]
a_list = [n for n, a in enumerate(map(lambda x: tuple(x), p.areaRng)) if a in setA]
i_list = [n for n, i in enumerate(p.imgIds) if i in setI]
I0 = len(_pe.imgIds)
A0 = len(_pe.areaRng)
# retrieve E at each category, area range, and max number of detections
for k, k0 in enumerate(k_list):
Nk = k0*A0*I0
for a, a0 in enumerate(a_list):
Na = a0*I0
for m, maxDet in enumerate(m_list):
E = [self.evalImgs[Nk + Na + i] for i in i_list]
E = [e for e in E if not e is None]
if len(E) == 0:
continue
dtScores = np.concatenate([e['dtScores'][0:maxDet] for e in E])
# different sorting method generates slightly different results.
# mergesort is used to be consistent as Matlab implementation.
inds = np.argsort(-dtScores, kind='mergesort')
dtScoresSorted = dtScores[inds]
dtm = np.concatenate([e['dtMatches'][:,0:maxDet] for e in E], axis=1)[:,inds]
dtIg = np.concatenate([e['dtIgnore'][:,0:maxDet] for e in E], axis=1)[:,inds]
gtIg = np.concatenate([e['gtIgnore'] for e in E])
npig = np.count_nonzero(gtIg==0 )
if npig == 0:
continue
tps = np.logical_and( dtm, np.logical_not(dtIg) )
fps = np.logical_and(np.logical_not(dtm), np.logical_not(dtIg) )
tp_sum = np.cumsum(tps, axis=1).astype(dtype=np.float)
fp_sum = np.cumsum(fps, axis=1).astype(dtype=np.float)
for t, (tp, fp) in enumerate(zip(tp_sum, fp_sum)):
tp = np.array(tp)
fp = np.array(fp)
nd = len(tp)
rc = tp / npig
pr = tp / (fp+tp+np.spacing(1))
q = np.zeros((R,))
ss = np.zeros((R,))
if nd:
recall[t,k,a,m] = rc[-1]
else:
recall[t,k,a,m] = 0
# numpy is slow without cython optimization for accessing elements
# use python array gets significant speed improvement
pr = pr.tolist(); q = q.tolist()
for i in range(nd-1, 0, -1):
if pr[i] > pr[i-1]:
pr[i-1] = pr[i]
inds = np.searchsorted(rc, p.recThrs, side='left')
try:
for ri, pi in enumerate(inds):
q[ri] = pr[pi]
ss[ri] = dtScoresSorted[pi]
except:
pass
precision[t,:,k,a,m] = np.array(q)
scores[t,:,k,a,m] = np.array(ss)
self.eval = {
'params': p,
'counts': [T, R, K, A, M],
'date': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'precision': precision,
'recall': recall,
'scores': scores,
}
toc = time.time()
print('DONE (t={:0.2f}s).'.format( toc-tic))
我想使用100张coco数据进行测试,那么就需要分割出来100张的json
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import os
import datetime
import random
import sys
import operator
import math
import numpy as np
import skimage.io
import matplotlib
from matplotlib import pyplot as plt
import cv2
from collections import defaultdict, OrderedDict
import json
import copy
def load_json(filenamejson):
with open(filenamejson, 'r') as f:
raw_data = json.load(f)
return raw_data
root_data={}
ori_data = load_json("/media/spple/新加卷/Dataset/coco_dataset/annotations/instances_val2014.json")
print("load OK")
#root_data = copy.deepcopy(ori_data)
root_data["annotations"] = []
root_data["images"] = []
root_data["categories"] = ori_data["categories"]
root_data["licenses"] = ori_data["licenses"]
root_data["info"] = ori_data["info"]
print("copy OK")
#统计bbox-seg个数
temp_ann = []
temp_imageid = []
annotation_count = str(ori_data["annotations"]).count('image_id',0,len(str(ori_data["annotations"])))
for i in range(annotation_count):
#追加annotations的数据
temp_ann.append(ori_data['annotations'][i])
temp_imageid.append(int(ori_data['annotations'][i]['image_id']))
print("annotation_count append OK")
images_count = str(ori_data["images"]).count('file_name',0,len(str(ori_data["images"])))
print("images_count",images_count)
#处理前100g个,不是id0-99,只是list前100个
for i in range(100):
#追加images的数据
root_data['images'].append(ori_data['images'][i])
image_id = ori_data['images'][i]['id']
# try:
# index = temp_imageid.index(int(image_id))
# except ValueError as e:
# print('ValueError:',e)
# exit()
temp = np.array(temp_imageid)
index = np.where(temp==int(image_id))
print(index)
if index is not None:
for key in index[0]:
root_data['annotations'].append(temp_ann[int(key)])
else:
print("No annotation image_id",image_id)
#https://blog.csdn.net/u012609509/article/details/88680841
print("共处理 {0} 个图片文件".format(100))
print("共处理 {0} 个annotation文件".format(str(root_data["annotations"]).count('image_id',0,len(str(root_data["annotations"])))))
print("共找到 {0} 个类别".format(str(root_data["categories"]).count('name',0,len(str(root_data["categories"])))))
json_str = json.dumps(root_data, indent=1)
#json_str = json.dumps(root_data, ensure_ascii=False, indent=1)
#json_str = json.dumps(root_data)
with open('./instances_val2019.json', 'w') as json_file:
json_file.write(json_str)
#写出合并文件
print("Done!") 顺便附上合并操作:
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
import os
import datetime
import random
import sys
import operator
import math
import numpy as np
import skimage.io
import matplotlib
from matplotlib import pyplot as plt
from collections import defaultdict, OrderedDict
import json
#待合并的路径
FILE_DIR = "./coco_all_10.26/annotations/val/"
def load_json(filenamejson):
with open(filenamejson, 'r') as f:
raw_data = json.load(f)
return raw_data
file_count = 0
files = os.listdir(FILE_DIR)
root_data = {}
annotations_num = 0
images_num = 0
annotations_id = []
images=[]
for x in range(len(files)):
#解析文件名字和后缀
#print(str(files[x]))
file_suffix = str(files[x]).split(".")[1]
file_name = str(files[x]).split(".")[0]
#过滤类型不对的文件
if file_suffix not in "json":
continue
#json文件计数
file_count = file_count + 1
#组合文件路径
filenamejson = FILE_DIR + str(files[x])
print(filenamejson)
#读取文件
if x == 0:
#第一个文件作为root
root_data = load_json(filenamejson)
#为了方便直接在第一个json的id最大值基础上进行累加新的json的id
annotations_num = len(root_data['annotations'])
images_num = len(root_data['images'])
#拿到root的id
for key1 in range(annotations_num):
annotations_id.append(int(root_data['annotations'][key1]['id']))
for key2 in range(images_num):
images.append(int(root_data['images'][key2]['id']))
print("{0}生成的json有 {1} 个图片".format(x, len(root_data['images'])))
print("{0}生成的json有 {1} 个annotation".format(x, len(root_data['annotations'])))
else:
#载入新的json
raw_data = load_json(filenamejson)
next_annotations_num = len(raw_data['annotations'])
next_images_num = len(raw_data['images'])
categories_num = len(raw_data['categories'])
print("{0}生成的json有 {1} 个图片".format(x, len(raw_data['images'])))
print("{0}生成的json有 {1} 个annotation".format(x, len(raw_data['annotations'])))
#对于image-list进行查找新id且不存在id库,直到新的id出现并分配
old_imageid = []
new_imageid = []
for i in range(next_images_num):
#追加images的数据
while(images_num in images):
images_num += 1
#将新的id加入匹配库,防止重复
images.append(images_num)
#保存新旧id的一一对应关系,方便annotations替换image_id
old_imageid.append(int(raw_data['images'][i]['id']))
new_imageid.append(images_num)
#使用新id
raw_data['images'][i]['id'] = images_num
root_data['images'].append(raw_data['images'][i])
#对于annotations-list进行查找新id且不存在id库,直到新的id出现并分配
for i in range(next_annotations_num):
#追加annotations的数据
while(annotations_num in annotations_id):
annotations_num += 1
#将新的annotations_id加入匹配库,防止重复
annotations_id.append(annotations_num)
#使用新id
raw_data['annotations'][i]['id'] = annotations_num
#查到该annotation对应的image_id,并将其替换为已经更新后的image_id
ind = int(raw_data['annotations'][i]['image_id'])
#新旧image_id一一对应,通过index旧id取到新id
try:
index = old_imageid.index(ind)
except ValueError as e:
print("error")
exit()
imgid = new_imageid[index]
raw_data['annotations'][i]['image_id'] = imgid
root_data['annotations'].append(raw_data['annotations'][i])
#统计这个文件的类别数--可能会重复,要剔除
#这里我的,categories-id在多个json文件下是一样的,所以没做处理
raw_categories_count = str(raw_data["categories"]).count('name',0,len(str(raw_data["categories"])))
for j in range(categories_num):
root_data["categories"].append(raw_data['categories'][j])
#统计根文件类别数
temp = []
for m in root_data["categories"]:
if m not in temp:
temp.append(m)
root_data["categories"] = temp
print("共处理 {0} 个json文件".format(file_count))
print("共找到 {0} 个类别".format(str(root_data["categories"]).count('name',0,len(str(root_data["categories"])))))
print("最终生成的json有 {0} 个图片".format(len(root_data['images'])))
print("最终生成的json有 {0} 个annotation".format(len(root_data['annotations'])))
json_str = json.dumps(root_data, ensure_ascii=False, indent=1)
#json_str = json.dumps(root_data)
with open('./coco_all_10.26/annotations/instances_val2017.json', 'w') as json_file:
json_file.write(json_str)
#写出合并文件
print("Done!") 看下结果:
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 100/100, 4.9 task/s, elapsed: 20s, ETA: 0s
writing results to temp_pred/maskrcnn_out.pkl
Starting evaluate bbox and segm
Loading and preparing results...
DONE (t=0.01s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *bbox*
DONE (t=0.41s).
Accumulating evaluation results...
DONE (t=0.33s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.446
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.646
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.500
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.270
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.514
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.602
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.372
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.511
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.515
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.346
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.597
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.647
Loading and preparing results...
DONE (t=0.03s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *segm*
DONE (t=0.43s).
Accumulating evaluation results...
DONE (t=0.24s).
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.409
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.635
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.459
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.224
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.445
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.622
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.346
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.467
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.470
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.311
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.529
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.647没问题
接着走
在文件:
mmdetection/mmdet/core/evaluation/coco_utils.py中 ROC不对,但我没想好怎么画出来,先画出PR
def coco_eval(result_files, result_types, coco, max_dets=(100, 300, 1000)):
for res_type in result_types:
assert res_type in [
'proposal', 'proposal_fast', 'bbox', 'segm', 'keypoints'
]
if mmcv.is_str(coco):
coco = COCO(coco)
assert isinstance(coco, COCO)
if result_types == ['proposal_fast']:
ar = fast_eval_recall(result_files, coco, np.array(max_dets))
for i, num in enumerate(max_dets):
print('AR@{}\t= {:.4f}'.format(num, ar[i]))
return
for res_type in result_types:
result_file = result_files[res_type]
assert result_file.endswith('.json')
coco_dets = coco.loadRes(result_file)
img_ids = coco.getImgIds()
iou_type = 'bbox' if res_type == 'proposal' else res_type
cocoEval = COCOeval(coco, coco_dets, iou_type)
cocoEval.params.imgIds = img_ids
if res_type == 'proposal':
cocoEval.params.useCats = 0
cocoEval.params.maxDets = list(max_dets)
cocoEval.evaluate()
cocoEval.accumulate()
cocoEval.summarize()
# new code
'''
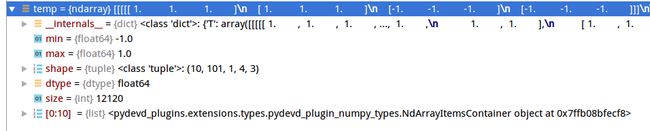
# coco_eval.eval['precision']是一个5维的数组
# precision - [TxRxKxAxM] precision for every evaluation setting
# catIds - [all] K cat ids to use for evaluation
# iouThrs - [.5:.05:.95] T=10 IoU thresholds for evaluation
# recThrs - [0:.01:1] R=101 recall thresholds for evaluation
# areaRng - [...] A=4 object area ranges for evaluation
# maxDets - [1 10 100] M=3 thresholds on max detections per image
#第一维T:IoU的10个阈值,从0.5到0.95间隔0.05
#第二维R:101个recall 阈值,从0到101
#第三维K:类别,如果是想展示第一类的结果就设为0
#第四维A:area 目标的大小范围 (all,small, medium, large)(全部,小,中,大)
#第五维M:maxDets 单张图像中最多检测框的数量 三种 1,10,100
# coco_eval.eval['precision'][0, :, 0, 0, 2] 所表示的就是当IoU=0.5时
# 从0到100的101个recall对应的101个precision的值
# plt.grid是用来在图中加网格
# plt.legend是用来在图中添加注释
'''
'''
# 有了TP、FP、FN的定义,就可以方便地得出准确率(Precison,P,即所有的检测结果中多少是对的)
# 和召回率(Recall,R,即所有的真实目标中有多少被检测出来了),两者的定义分别为:
# P = TP / (TP + FP),
# R = TP / (TP + FN) = TP / len(GTs)。
# ROC曲线是x轴为FP FP是N个负样本中被分类器预测为正样本的个数
# y轴为TP/p的曲线 P是真实正样本的个数,TP是P个正样本中被分类器预测为正样本的个数=Rcall
'''
# pr 曲线是针对一个类别分类的
# 如果是多类别可看多可以将其转换成“1 vs other”的二分类,从而使用ROC的面积、F1等二分类的指标
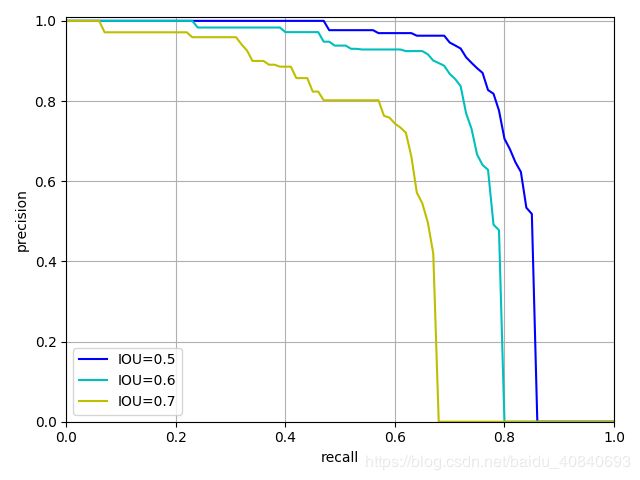
pr_array1 = cocoEval.eval['precision'][0, :, 0, 0, 2]
pr_array2 = cocoEval.eval['precision'][2, :, 0, 0, 2]
pr_array3 = cocoEval.eval['precision'][4, :, 0, 0, 2]
x = np.arange(0.0, 1.01, 0.01)
import matplotlib.pyplot as plt
plt.figure()
plt.title(res_type+" PR")
plt.xlabel("recall")
plt.ylabel("precision")
plt.xlim(0, 1.0)
plt.ylim(0, 1.01)
plt.grid(True)
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(x, pr_array1, 'b-', label='IOU=0.5')
plt.plot(x, pr_array2, 'c-', label='IOU=0.6')
plt.plot(x, pr_array3, 'y-', label='IOU=0.7')
plt.legend(loc="lower left")
plt.show()
# ROC 曲线
plt.figure()
plt.title(res_type + " ROC")
plt.xlabel('False Positives')
plt.ylabel('True Positive rate')
#plt.ylim(0, 1)
plt.xlim(0, 1.0)
plt.ylim(0, 1.01)
plt.grid(True)
plt.plot([1, 0], [0, 1], 'r--')
plt.plot(x, pr_array1, 'b-', label='IOU=0.5')
plt.plot(x, pr_array2, 'c-', label='IOU=0.6')
plt.plot(x, pr_array3, 'y-', label='IOU=0.7')
#plt.plot(fp_list, recall_list, label='AUC: ' + str(auc))
plt.legend(loc="lower right")
plt.show()
box我设置2类,背景+1类,mask我设置81类,背景+80类看一下:
temp = cocoEval.eval['precision']box:
seg:这里是因为,我的coco数据里面就一类,
是以coco数据集类别建立评价类的,所以也显示1

bbox_head=dict(
type='SharedFCBBoxHead',
num_fcs=2,
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=2,
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2],
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0)),
mask_head=dict(
type='FCNMaskHead',
num_convs=4,
in_channels=256,
conv_out_channels=256,
num_classes=81,
loss_mask=dict(
type='CrossEntropyLoss', use_mask=True, loss_weight=1.0)))COCOEval 解析:
https://blog.csdn.net/noiplcx/article/details/100690936
https://www.jianshu.com/p/d7a06a720a2b
http://www.immersivelimit.com/tutorials/create-coco-annotations-from-scratch
https://www.twblogs.net/a/5ca0fa04bd9eee5b1a06a16e
MS COCO数据集目标检测评估(Detection Evaluation)(来自官网)
https://blog.csdn.net/u014734886/article/details/78831884
MS COCO数据集输出数据的结果格式(result format)和如何参加比赛(participate)(来自官网
https://blog.csdn.net/u014734886/article/details/78831382
这个是参考这个,实现是.m实现
https://github.com/matteorr/coco-analyze
https://github.com/cocodataset/cocoapi/blob/master/MatlabAPI/CocoEval.m

P-R曲线及与ROC曲线区别
https://www.cnblogs.com/gczr/p/10137063.html