深入理解Spark RDD——RDD依赖(构建DAG的关键)
在《深入理解Spark RDD——为什么需要RDD?》一文我们解释了为什么需要RDD,并且在《深入理解Spark RDD——RDD实现的初次分析》一文对RDD进行了基本的分析,本文将继续对RDD的依赖实现进行分析。正是由于RDD之间具有依赖关系,才能进而转换为调度中的DAG。
DAG中的各个RDD之间存在着依赖关系。换言之,正是RDD之间的依赖关系构建了由RDD所组成的DAG。Spark使用Dependency来表示RDD之间的依赖关系,Dependency的定义如下:
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}抽象类Dependency只定义了一个名叫rdd的方法,此方法返回当前依赖的RDD。
Dependency分为NarrowDependency和ShuffleDependency两种依赖,下面对它们分别介绍。
窄依赖NarrowDependency
如果RDD与上游RDD的分区是一对一的关系,那么RDD和其上游RDD之间的依赖关系属于窄依赖。NarrowDependency继承了Dependency,以表示窄依赖。NarrowDependency的定义如下:
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}NarrowDependency定义了一个类型为RDD的构造器参数_rdd,NarrowDependency重写了Dependency的rdd方法,让其返回_rdd。NarrowDependency还定义了一个获取某一分区的所有父级别分区序列的getParents方法。NarrowDependency一共有两个子类,它们的实现见代码清单1。
代码清单1 OneToOneDependency与RangeDependency
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}根据代码清单1,OneToOneDependency重写的getParents方法告诉我们子RDD的分区与依赖的父RDD的分区相同。OneToOneDependency可以用图1更形象的说明。
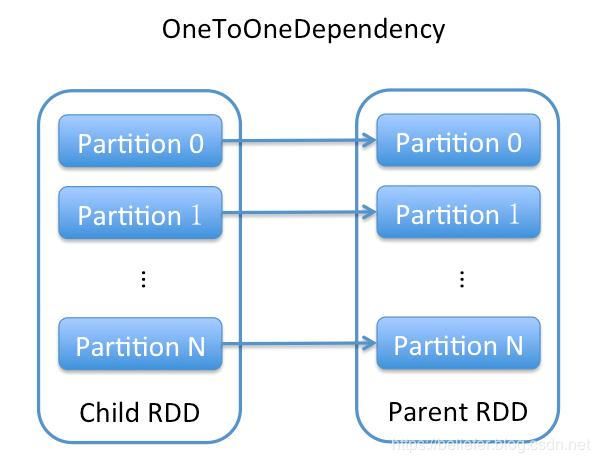 图1 OneToOneDependency的依赖示意图
图1 OneToOneDependency的依赖示意图
根据代码清单1,RangeDependency重写了Dependency的getParents方法,其实现告诉我们RangeDependency的分区是一对一的, 且索引为partitionId的子RDD分区与索引为partitionId - outStart + inStart的父RDD分区相对应(outStart代表子RDD的分区范围起始值,inStart代表父RDD的分区范围起始值)。RangeDependency可以用图2更形象的说明。
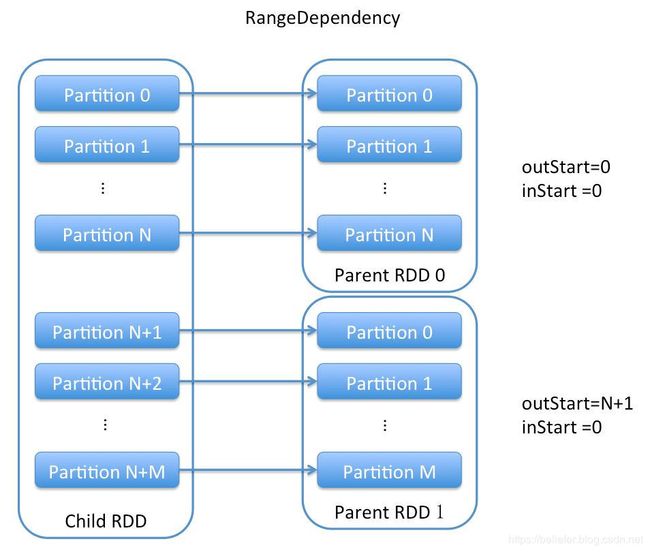 图2 RangeDependency的依赖示意图
图2 RangeDependency的依赖示意图
Shuffle依赖ShuffleDependency
RDD与上游RDD的分区如果不是一对一的关系,或者RDD的分区依赖于上游RDD的多个分区,那么这种依赖关系就叫做Shuffle依赖。ShuffleDependency的实现见代码清单2。
代码清单2 ShuffleDependency的实现
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}根据代码清单2,ShuffleDependency定义了如下属性。
- _rdd:泛型要求必须是Product2[K, V]及其子类的RDD。
- partitioner:分区计算器Partitioner。Partitioner将在下一小节详细介绍。
- serializer:SparkEnv中创建的serializer,即org.apache.spark.serializer.JavaSerializer。
- keyOrdering:按照K进行排序的scala.math.Ordering的实现类。
- aggregator:对map任务的输出数据进行聚合的聚合器。
- mapSideCombine:是否在map端进行合并,默认为false。
- keyClassName:K的类名。
- valueClassName:V的类名。
- combinerClassName:结合器C的类名。
- shuffleId:当前ShuffleDependency的身份标识。
- shuffleHandle:当前ShuffleDependency的处理器。
此外,ShuffleDependency还重写了父类Dependency的rdd方法,其实现将_rdd转换为RDD[Product2[K, V]]后返回。ShuffleDependency在构造的过程中还将自己注册到SparkContext的ContextCleaner中。
请继续阅读《深入理解Spark RDD——RDD分区计算器Partitioner》
深入理解Spark RDD系列文章:
《深入理解Spark RDD——为什么需要RDD?》
《深入理解Spark RDD——RDD实现的初次分析》
《深入理解Spark RDD——RDD依赖(构建DAG的关键)》
《深入理解Spark RDD——RDD分区计算器Partitioner》
《深入理解Spark RDD——RDD信息对象》